







一、学习目标
1.学习语料库的概念
2.了解n元文法模型的定义以及相关问题
3.使用参数估计方法求解模型最优
4.使用数据平滑消除零概率现象
5.了解N元文法模型的一个应用
二、语料库
1.语料库(corpus)的定义:语言数据库,用于存放语言数据的文件。
2.语料库的分类:

3.语料库的应用:

三、N元文法模型定义
1.N元文法模型的定义:

历史基元是当前词语前面的词语。根据n的多少,可以进行分类:

例子如下:

2.句首、句末标志:

四、N元文法模型参数估计
1.语言模型的参数估计方法一般选择极大似然估计,而不使用最大后验估计,主要原因在于我们无法确立一个很好的先验概率分布。相关原理可见《机器学习(第2章)》的参数估计小节。
2.极大似然估计实现方法:

例子:

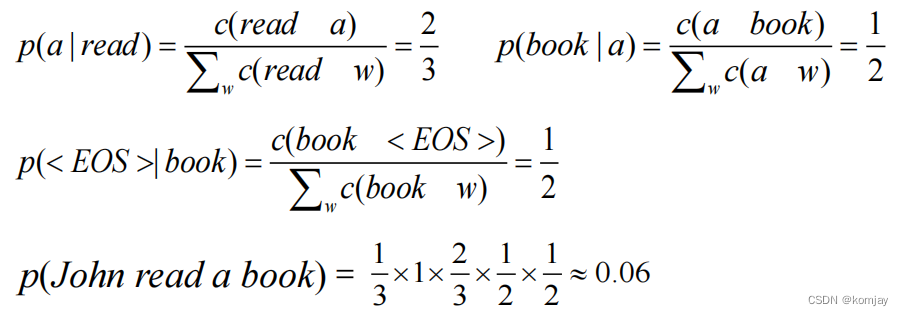
一个不正常的例子:

由于语料库的不存在“Cher read”的词对,导致出现0概率,由于最后乘算,就导致最终概率也为0。这显然是不合理的,这主要是语料库不足导致的,除了扩大语料库外,显然我们也可以设计一种方法去避免这种现象,即数据平滑。
五、数据平滑
1.方法原理:

困惑度即将交叉熵进行幂级放大:
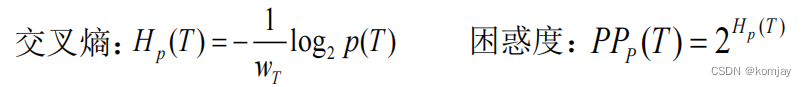
其中p(T)在语言模型中,就是:
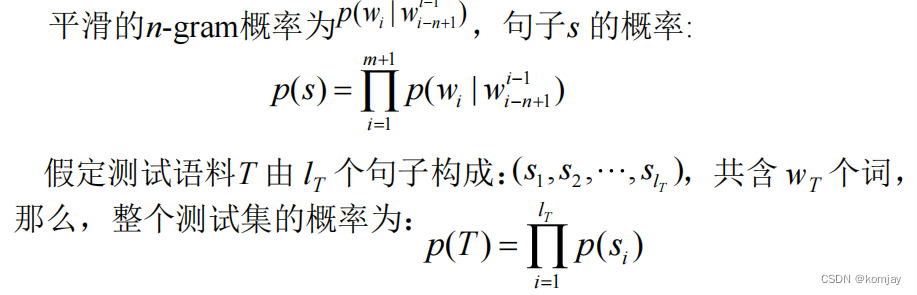
2.实际上,我们并不需要真的去求困惑度最小的语言模型,因为已经有许多种方法:

为了减少篇幅,这里只展示加1法:

而针对前面出现0概率的例子,我们就能通过加1操作使结果不为0:


六、N元文法模型的应用
1.问题描述:对下面汉语句子进行分词才是正确的呢?

进行语言建模:
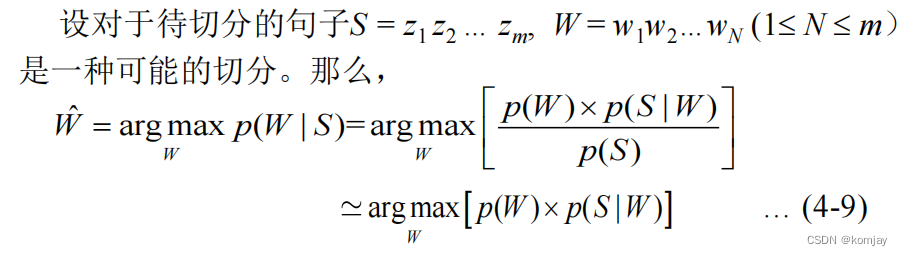
2.词典的拓展:由于原有词典并不能包含所有的词语,为了拓展足够多的正确的词汇,我们可以人为地拓展词典,方法与例子有:

3.而为了使用隐马尔可夫模型,我们需要对词序列转化为词性序列:

例如:

4.公式计算:(这里采用的是最大后验估计,实际中会有些难实现)


(4-9)是我们的目标函数,其包含两个部分,语言模型和生成模型,语言模型部分我们可以通过(4-10)、(4-11)来计算,生成模型由(4-12)来计算。最后求解出的W是最优的词序列,C是词性序列。
5.整体算法描述:

七、本章总结















 1677
1677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









