









从医学统计学关联到因果关系

随机对照实验是医学研究的金标准,但是开展难度较大。孟德尔遗传的证据等级介于队列研究和随机对照研究之间。

作为工具变量,来研究中间表型和疾病之间的关联性。


孟德尔随机化例子
基因型SLC2A9与尿酸有关(基于文献),同时SLC2A9也与缺血性心脏病无关。该基因型与年龄、性别等混杂因素无关。借助这个模型就可以研究尿酸与缺血性心脏病的关系。

孟德尔随机化的步骤为:
①找工具变量,从其他研究中挑选特定基因作为工具变量,从基因库中挑选需要的和暴露相关的基因变量SNPs。
②估计工具变量对结局的作用,工具变量对结局的作用也是从所有的研究中估计出来的整体效应,这样可以拒绝单个研究的偏倚。
③合并多个SNP的效应量,效应量是得到暴露和结局因果效应的前提。
④用合并后的数据进行孟德尔随机化分析和相应的敏感性分析。
孟德尔随机化的统计方法包括:
①逆方差加权法(inverse variance weighted.Ivw):IVW是MR在分析多个SNP时对多个位点效应进行Meta汇总的方法。IVW的应用前提是所有的SNP均为有效的工具变量且相互之间完全独立。
②加权中位数估计(Weighted median,WM):WM为所有的个体SNP效应值按照权重排序后得到的分布函数的中位数。当至少50%的信息来自于有效的工具变量时,WM可得到稳健的估计值。
③MR-Egger法:MR-Egger不强制回归直线通过原点,允许纳入的工具变量存在定向的基因多效性。当回归截距不为零且P for intercept <0.05时表明基因多效性的存在。
④MR-PRESSO法:可以通过排除异常值(outliers)排除特定的SNP以获得更加接近真实值的估计值。
例子
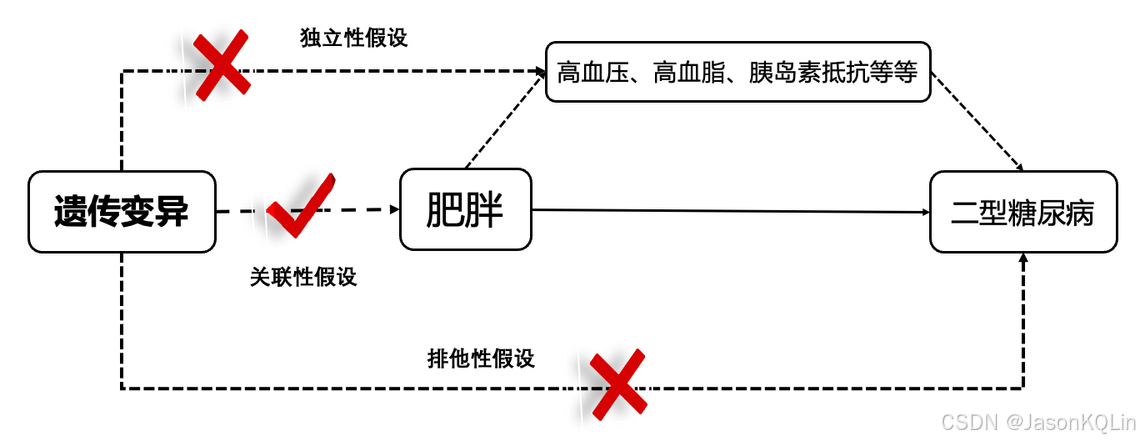
研究肥胖和二型糖尿病的直接因果关系遇到如下挑战:1),高血压和高血脂等因素与肥胖、二型糖尿病都有关系,肥胖可能是通过高血压和高血脂等因素去导致二型糖尿病,而本身与二型糖尿病没有直接关系;2),现有数据只能表明肥胖和二型糖尿病有强相关性,无法证明是肥胖引起了二型糖尿病,还是二型糖尿病引起了肥胖。
孟德尔随机化的解决方案是:找出与肥胖强相关的SNP位点(扮演着肥胖的代理人的角色),根据这些SNP位点对二型糖尿病患者进行分组(有该等位基因vs.无该等位基因),这样就可以认为是随机分组(因为非同源染色体上的非姐妹染色单体交叉互换是随机的),并且这样的分组排除了混杂因素的干扰(因为这些SNP位点与混杂因素无关)。
如果直接根据肥胖与否进行分组的话就有下面的问题:1),高血压和高血脂等因素与肥胖有关,在分组的时候要考虑这些混杂因素;2),肥胖组中可能有二型糖尿病导致的肥胖患者(因果关系比较难说清楚)。
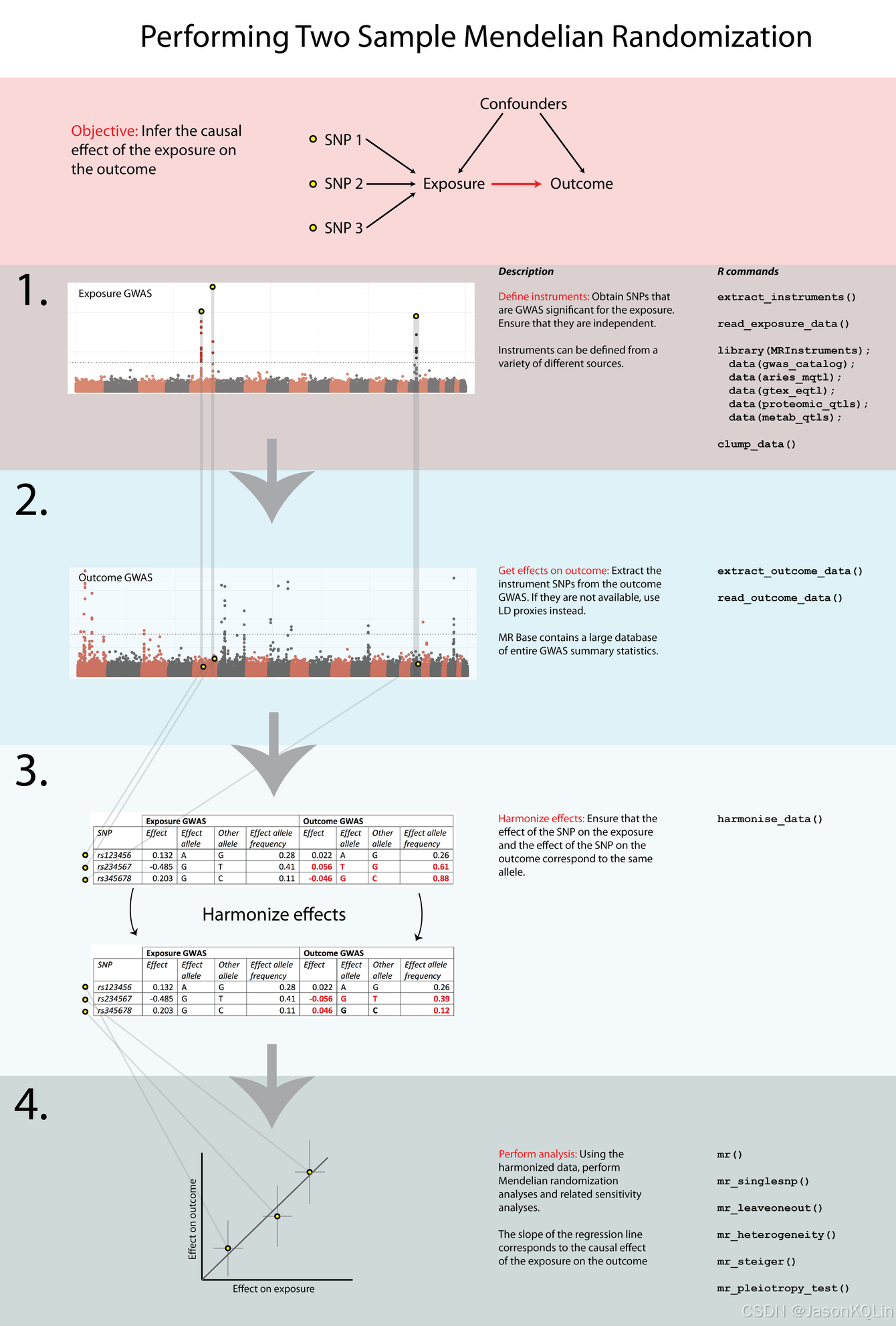
官网分析流程
Reference
https://www.sohu.com/a/666661861_121118947
https://gwaslab.org/2021/06/24/mr/
https://blog.csdn.net/weixin_43843918/article/details/136063754
https://blog.csdn.net/weixin_43843918/article/details/137787561

















 1648
1648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









