










这篇博客专门介绍一下MarkerMapper的实现原理,不了解MarkerMapper的可以先看一下我的上一篇博客:基于ArUco的视觉定位(三)。
这不是一篇翻译,而是博主对上述论文的总结,理解之中难免有不到位的地方,不足之处还请参看原文。
〇、MarkerMapper干了啥?
这里再陈述一遍MarkerMapper到底干了些什么事:
- 根据我们指定的空间中任意一个ID的marker,MakerMapper将整个空间中任意分布的所有marker以指定marker为参考坐标系构建marker的分布图,生成一个二维码分布文件。二维码的分布体现在每个marker的四个角点相对指定marker坐标系的三维坐标,即得到所有marker在参考世界坐标系下的位姿分布。其实最重要的也是我们最想得到的,就是所有marker的角点在世界坐标系下的三维坐标,因为有了这些角点的三维坐标,我们就可以用PnP算法估计相机的位姿。
- 在构建二维码分布图的过程中,MarkerMapper同时对相机的运行轨迹进行了估计,记录了关键帧在参考世界坐标系下的位姿。这里的关键帧是指那些至少观察到两个marker的帧。
- 除了优化了二维码的位姿分布和相机的运行轨迹,MarkerMapper还优化了相机的内参数。
- MakerMapper为我们生成了一个包含二维码位姿分布以及关键帧轨迹的可视化点云图。
一、基本原理
1、基本思路
如上图(a)所示,当第
f
6
f\,^6
f6帧图像中同时检测到marker1和marker2时,我们可以得到相机当前与marker1之间的位姿关系
γ
1
6
\gamma\,_1^6
γ16、与marker2之间的位姿关系
γ
2
6
\gamma\,_2^6
γ26,由此我们就可以在
f
6
f\,^6
f6帧下求得marker1与marker2之间的位姿变换矩阵
γ
2
,
1
6
=
(
γ
2
6
)
−
1
γ
1
6
\gamma\,_{2,1}^6=(\gamma\,_2^6)^{-1}\gamma\,_1^6
γ2,16=(γ26)−1γ16;当第
f
7
f\,^7
f7帧图像中同时检测到marker1、marker2和marker3时,我们可以得到相机当前与marker1之间的位姿关系
γ
1
7
\gamma\,_1^7
γ17、与marker2之间的位姿关系
γ
2
7
\gamma\,_2^7
γ27、以及与marker3之间的位姿关系
γ
3
7
\gamma\,_3^7
γ37,从而我们可以在
f
7
f\,^7
f7帧下求得marker1与marker2之间的位姿变换矩阵
γ
2
,
1
7
\gamma\,_{2,1}^7
γ2,17、marker1与marker3之间的位姿变换矩阵
γ
3
,
1
7
\gamma\,_{3,1}^7
γ3,17、marker2与marker3之间的位姿变换矩阵
γ
3
,
2
7
\gamma\,_{3,2}^7
γ3,27。同理,当第
f
t
f\,^t
ft帧图像中同时检测到marker{
i
i
i,
j
j
j,
k
k
k,
.
.
.
...
...}时,我们可以求得在当前帧下各marker之间的位姿变换矩阵
γ
j
,
i
t
\gamma\,_{j,i}^t
γj,it、
γ
k
,
i
t
\gamma\,_{k,i}^t
γk,it、
γ
k
,
j
t
\gamma\,_{k,j}^t
γk,jt、
.
.
.
...
...。
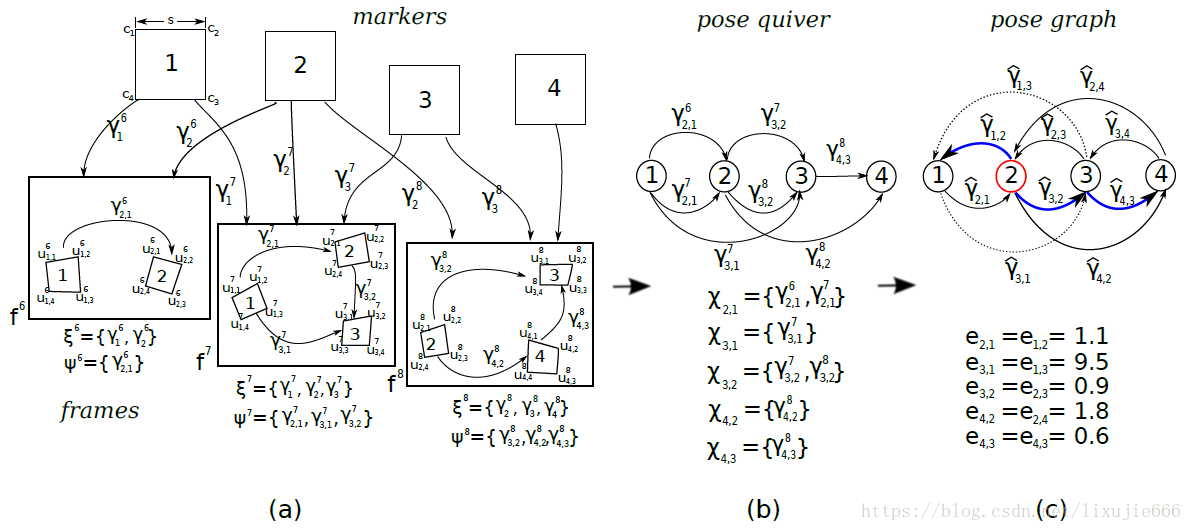
按照上面的思路,我们可以得到空间中所有二维码任意两两之间的相对位姿关系。指定其中一个二维码坐标系作为参考世界坐标系,就可以求得所有二维码相对于参考坐标系的位姿,进而得到所有二维码的角点在世界坐标系下的三维坐标。
道理我们都懂,但实现起来远非这么简单。
理论上,在相机经过若干帧观察到所有marker后,我们就可以推算出任意marker间的相对位姿关系
γ
j
,
i
\gamma\,_{j,i}
γj,i,但由于光线不佳、相机移动过快、分辨率较低、对焦不清等等原因,二维码角点的像素坐标是不准的,由此计算出来的
γ
i
t
\gamma_i^t
γit也是不准的,
γ
j
,
i
t
\gamma\,_{j,i}^t
γj,it就更不准。总而言之,由于观测噪声的存在,这种简单地推算出来的关系是非常不准确的,存在极大的累积误差。所以,如何在有噪声的观测数据下精确地计算出每个marker在世界坐标系下的角点坐标,才是我们真正要解决的问题。
2、核心问题
经过上面的分析,我们知道,问题的关键在于如何在相机不准确的观测数据下估计出二维码准确的位姿分布。了解SLAM的同学应该都知道,要解决这个问题最终不得不使出我们的杀手锏——非线性优化。好吧,MarkerMapper最终也要归结到一个优化问题上,基本手段就是最小化重投影误差:
e
i
t
=
∑
j
[
Ψ
(
δ
,
γ
t
,
γ
i
⋅
c
j
)
−
u
i
,
j
t
]
2
(非常重要)
\color{#F00}{e_i^t=\sum_{j}[\Psi(\delta,\gamma^t,\gamma_i\cdot c_j)-{\bf u}_{i,j}^t]^2\tag{非常重要}}
eit=j∑[Ψ(δ,γt,γi⋅cj)−ui,jt]2(非常重要)
解释一下这个重要的公式:
- c j c_j cj为已知量,表示marker i \,i\, i在该marker坐标系下角点 j \,j\, j的三维坐标。通常,在marker边长已知为 s \,s\, s的情况下,每个marker的4个角点在自身坐标系下的坐标分别为 c 0 = ( s / 2 , − s / 2 , 0 ) , c 1 = ( s / 2 , s / 2 , 0 ) , c 2 = ( − s / 2 , s / 2 , 0 ) , c 3 = ( − s / 2 , − s / 2 , 0 ) c_0=(s/2,-s/2,0),\,c_1=(s/2,s/2,0),\,c_2=(-s/2,s/2,0),\,c_3=(-s/2,-s/2,0) c0=(s/2,−s/2,0),c1=(s/2,s/2,0),c2=(−s/2,s/2,0),c3=(−s/2,−s/2,0)。
- γ i \gamma_i γi为待估计量,表示从marker坐标系到世界坐标系的齐次变换矩阵,这里的世界坐标系是指参考的marker坐标系。 γ i ⋅ c j \gamma_i\cdot c_j γi⋅cj是将marker i \,i\, i的第 j \,j\, j个角点有marker坐标系转换到世界坐标系下表示。
- γ t \gamma^t γt为待估计量,表示从世界坐标系到相机坐标系的齐次变换矩阵,也即相机的外参。
- δ \delta δ为待估计量,表示相机的内参矩阵。
- 函数 Ψ ( δ , γ t , γ i ⋅ c j ) \Psi(\delta,\gamma^t,\gamma_i\cdot c_j) Ψ(δ,γt,γi⋅cj)表示marker i \,i\, i的角点 j \,j\, j从三维空间坐标到像素坐标的一种投影,它先将角点 c j c_j cj转换到世界坐标系,再转换到相机坐标系,最后转换到像素坐标系。所以, Ψ \Psi Ψ表示的角点像素坐标是根据待估计量计算出来的,称为重投影。
- u i , j t u_{i,j}^t ui,jt为观测量,表示在第 f t f^t ft帧下观察到的marker i \,i\, i第 j \,j\, j个角点真实的像素坐标,由于各种原因产生的观测噪声,真实的并不代表就是准确的。
所以,
e
i
t
=
∑
j
[
Ψ
−
u
i
,
j
t
]
2
e_i^t=\sum_{j}[\Psi-{\bf u}_{i,j}^t]^2
eit=∑j[Ψ−ui,jt]2表示在第
f
t
f^t
ft帧下marker
i
\,i\,
i 4个角点的重投影误差平方和,我们的最终目的是估计出最优的
γ
i
\,\gamma_i
γi、
γ
t
\gamma^t
γt、
δ
\delta\,
δ 使得所有的
e
i
t
\,e_i^t\,
eit和最小,即:
e
(
γ
1
,
⋅
⋅
⋅
,
γ
M
,
γ
1
,
⋅
⋅
⋅
,
γ
N
,
δ
)
=
∑
t
∑
i
∈
f
t
e
i
t
(1)
{\bf e}(\gamma_1,\cdot\cdot\cdot,\gamma_M,\gamma^1,\cdot\cdot\cdot,\gamma^N,\delta)=\sum_{t}\sum_{i\in{f^t}}e_i^t\tag{1}
e(γ1,⋅⋅⋅,γM,γ1,⋅⋅⋅,γN,δ)=t∑i∈ft∑eit(1)
将变换矩阵
γ
\,\gamma\,
γ用它的李代数形式
ζ
\,\zeta\,
ζ代替,写成如下形式:
f
(
γ
i
,
γ
t
,
δ
)
=
e
(
ζ
1
,
⋅
⋅
⋅
,
ζ
M
,
ζ
1
,
⋅
⋅
⋅
,
ζ
N
,
δ
)
=
∑
t
∑
i
∈
f
t
{
∑
j
[
Ψ
(
δ
,
Γ
(
ζ
t
)
,
Γ
(
ζ
i
)
⋅
c
j
)
−
u
i
,
j
t
]
2
}
(2)
f(\gamma_i,\gamma^t,\delta)={\bf e}(\zeta_1,\cdot\cdot\cdot,\zeta_M,\zeta^1,\cdot\cdot\cdot,\zeta^N,\delta)=\sum_{t}\sum_{i\in{f^t}}\left\{\sum_{j}[\Psi(\delta,\Gamma(\zeta^t),\Gamma(\zeta_i)\cdot c_j)-{\bf u}_{i,j}^t]^2\right\}\tag{2}
f(γi,γt,δ)=e(ζ1,⋅⋅⋅,ζM,ζ1,⋅⋅⋅,ζN,δ)=t∑i∈ft∑{j∑[Ψ(δ,Γ(ζt),Γ(ζi)⋅cj)−ui,jt]2}(2)
其中,
ζ
=
(
r
,
t
)
∣
r
,
t
∈
R
3
\zeta=({\bf r},{\bf t})\,|\,{\bf r},{\bf t}\in{\Bbb R}^3
ζ=(r,t)∣r,t∈R3,
γ
=
Γ
(
ζ
)
=
[
R
t
T
0
1
]
\gamma=\Gamma(\zeta)=\begin{bmatrix}{\bf R}&{\bf t}^\text{T}\\{\bf 0}&1\end{bmatrix}
γ=Γ(ζ)=[R0tT1],这里的
r
\,\bf r
r、
t
\bf t\,
t均为行向量。
f
t
f^t
ft为所有观察到两个及两个以上marker的帧组成的集合,我在这里称之为关键帧。
好了,接下来的问题就是求上述非线性函数
f
(
γ
i
,
γ
t
,
δ
)
f(\gamma_i,\gamma^t,\delta)
f(γi,γt,δ)的最小二乘解,它得到的最优解就是
γ
i
\,\gamma_i
γi、
γ
t
\gamma^t
γt、
δ
\delta\,
δ的最大似然估计值。那么,如何求解这个最小二乘问题?有以下两个要点:
- (1)给定待估计量一个合适的初始值
- (2)选择合适的迭代算法
二、确定优化变量的初始值
我们要优化的变量有三个: γ i \,\gamma_i γi、 γ t \gamma^t γt、 δ \delta\, δ,其中 δ \,\delta\, δ的初始值是通过各种相机标定方法在线下获得的,属于MakerMapper的输入参数,所以对 δ \,\delta\, δ而言直接优化即可,无需再确定它的初始值。下面详细介绍如何确定 γ i \,\gamma_i γi、 γ t \gamma^t\, γt的初始值。
1、如何获得每个marker在参考世界坐标系下的最优初始位姿 γ ~ i \,\tilde{\gamma}_i\, γ~i
1.1、创建位姿箭图 Q Q Q,找出marker间最优的位姿变换矩阵 γ ^ j , i \hat \gamma_{j,i} γ^j,i
上图(b)即是一个位姿箭图 Q Q Q,它由节点和边组成。节点表示不同ID的marker,节点之间相连的边表示所对应marker与marker之间的相对位姿关系 γ j , i t \gamma_{j,i}^{t} γj,it。不是所有节点之间都有直接相连的边,节点之间也可能存在多条边,任意两个节点之间所有的边组成的集合记为 χ j , i \chi_{j,i} χj,i。
我们首先要解决的,是从任意两两节点之间所有的边
χ
j
,
i
\chi_{j,i}
χj,i中选出最优的
γ
^
j
,
i
\hat \gamma_{j,i}
γ^j,i,用来创建初始位姿图。定义下式:
ε
(
γ
j
,
i
t
′
,
f
t
)
=
∑
k
[
Φ
(
δ
,
γ
j
t
,
γ
j
,
i
t
′
⋅
c
k
)
−
u
i
,
k
t
]
2
,
γ
j
,
i
t
′
∈
χ
j
,
i
(3)
\varepsilon(\gamma_{j,i}^{t'},f^t)=\sum_k\left[\Phi(\delta,\gamma_j^t,\gamma_{j,i}^{t'}\cdot c_k)-{\bf u}_{i,k}^t\right]^2,\,\gamma_{j,i}^{t'}\in\chi_{j,i}\tag{3}
ε(γj,it′,ft)=k∑[Φ(δ,γjt,γj,it′⋅ck)−ui,kt]2,γj,it′∈χj,i(3)
这个式子的意思是,利用在第 f t ′ f^{t'} ft′帧算出的 γ j , i t ′ \gamma_{j,i}^{t'} γj,it′将marker i \,i\, i四个角点的三维坐标转换到marker j \,j\, j下表示,然后通过第 f t f^t ft帧中的 γ j t \gamma_j^t γjt将marker j \,j\, j坐标系下表示的marker i \,i\, i的四个角点投影到 f t f^t ft帧的像素坐标中,最后求marker i \,i\, i在 f t f^t ft中四个角点的重投影误差。其中, t , t ′ ∈ F i , j t,{t'}\in\mathcal{F}_{i,j} t,t′∈Fi,j, F i , j \mathcal{F}_{i,j} Fi,j表示所有包含marker i \,i\, i与marker j \,j\, j的帧。
如果
ε
(
γ
j
,
i
t
′
,
f
t
)
<
ε
(
γ
j
,
i
t
,
f
t
′
)
\,\varepsilon(\gamma_{j,i}^{t'},f^t)<\varepsilon(\gamma_{j,i}^{t},f^{t'})
ε(γj,it′,ft)<ε(γj,it,ft′),即认为
γ
j
,
i
t
′
\gamma_{j,i}^{t'}
γj,it′优于
γ
j
,
i
t
\gamma_{j,i}^{t}
γj,it,据此,我们就可以从节点
i
\,i\,
i与节点
j
\,j\,
j的所有边中找到marker
i
\,i\,
i与marker
j
\,j\,
j之间最优的位姿矩阵
γ
^
j
,
i
\hat \gamma_{j,i}
γ^j,i:
γ
^
j
,
i
=
argmin
γ
j
,
i
∈
χ
j
,
i
e
j
,
i
(
γ
j
,
i
)
=
argmin
γ
j
,
i
∈
χ
j
,
i
∑
t
,
t
′
∈
F
i
,
j
ε
(
γ
j
,
i
t
′
,
f
t
)
(4)
\hat\gamma_{j,i}=\underset{\gamma_{j,i}\,\in\chi_{j,i}}{\text{argmin}}\,{\bf e}_{j,i}(\gamma_{j,i})=\underset{\gamma_{j,i}\,\in\chi_{j,i}}{\text{argmin}}\sum_{t,t'\in\mathcal{F}_{i,j}}\varepsilon(\gamma_{j,i}^{t'},f^t)\tag{4}
γ^j,i=γj,i∈χj,iargminej,i(γj,i)=γj,i∈χj,iargmint,t′∈Fi,j∑ε(γj,it′,ft)(4)
上式表示从节点 i , j i,j i,j之间所有的边 χ j , i \chi_{j,i} χj,i中找到一条 γ j , i \gamma_{j,i} γj,i,使得在包含所有marker i , j i,j i,j的帧 F i , j \mathcal{F}_{i,j} Fi,j中由 γ j , i \gamma_{j,i} γj,i得到的重投影误差平方和最小,这条边就记作 γ ^ j , i \hat \gamma_{j,i} γ^j,i
1.2、创建初始位姿图 G G G,计算位姿图 G G G的最小生成树***mst***
有了 γ ^ j , i \hat \gamma_{j,i} γ^j,i,现在 Q Q Q中的所有节点之间就只剩下了唯一的一条边,当然有的节点之间也可能没有边,但这并不代表它们之间是没有联系的。接下来,我们要利用 γ ^ j , i \hat \gamma_{j,i} γ^j,i创建一个位姿图 G G G,如上图(c)所示。它的节点也代表不同ID的marker,但节点与节点之间有两条边,分别为 γ ^ j , i \hat \gamma_{j,i} γ^j,i和 γ ^ i , j \hat \gamma_{i,j} γ^i,j,两者是互逆的关系。
根据位姿图
G
G
G,我们可以指定其中任意一个节点代表的marker
a
\,a\,
a作为参考,利用节点之间连接的边将所有marker的位姿都转换到参考marker
a
\,a\,
a坐标系下表示:
γ
^
i
=
γ
^
a
,
b
⋅
⋅
⋅
γ
^
k
,
h
γ
^
h
,
i
=
γ
^
a
,
i
(5)
\hat \gamma_i=\hat\gamma_{a,b}\cdot\cdot\cdot\hat\gamma_{k,h}\hat\gamma_{h,i}=\hat\gamma_{a,i}\tag{5}
γ^i=γ^a,b⋅⋅⋅γ^k,hγ^h,i=γ^a,i(5)
在计算 γ ^ i \hat \gamma_i γ^i之前要先计算位姿图 G G G的最小生成树(mst),即找到可以连通所有节点的最优路径,路径是由节点与节点之间的边连接而成。当然,任意一个节点 i \,i\, i到参考节点 a \,a\, a的路径都可能不止一条,这里寻找最优路径的原则是使得组成该路径的所有边的重投影误差和最小,即找到一条最佳路径使得 e a , i ( γ ^ a , i ) {\bf e}_{a,i}(\hat\gamma_{a,i}) ea,i(γ^a,i)最小:
( a , b , ⋅ ⋅ ⋅ , k , h , i ) = argmin e a , i ( γ ^ a , i ) = argmin { e a , b ( γ ^ a , b ) + ⋅ ⋅ ⋅ + e k , h ( γ ^ k , h ) + e h , i ( γ ^ h , i ) } (6) (a,b,\cdot\cdot\cdot ,k,h,i)={\text{argmin}}\,{\bf e}_{a,i}(\hat\gamma_{a,i})={\text{argmin}}\,\{{\bf e}_{a,b}(\hat\gamma_{a,b})+\cdot\cdot\cdot+{\bf e}_{k,h}(\hat\gamma_{k,h})+{\bf e}_{h,i}(\hat\gamma_{h,i})\}\tag{6} (a,b,⋅⋅⋅,k,h,i)=argminea,i(γ^a,i)=argmin{ea,b(γ^a,b)+⋅⋅⋅+ek,h(γ^k,h)+eh,i(γ^h,i)}(6)
上式在论文中并没有出现,是本人自己的理解,其中 e j , i ( γ ^ j , i ) {\bf e}_{j,i}(\hat\gamma_{j,i}) ej,i(γ^j,i)就是在上一步式(4)中计算的 γ ^ j , i \hat\gamma_{j,i} γ^j,i所对应的最小重投影误差平方和。最后,位姿图 G G G会变成类似下图所示的样子(加粗的黑线就是 mst ),连通节点 i \,i\, i与节点 j \,j\, j的路径都只剩下了唯一一条,但节点与节点之间依然有两条互逆的边(表示往返):

其实这一步的最终目的并不是计算 γ ^ i \hat \gamma_i γ^i,而是要得到满足上述条件的最小生成树 mst 。另外,如果我们在MarkerMapper的入口参数中没有指定参考marker,那么程序就会根据上述原则利用弗洛伊德算法从所有的marker中选择一个合适的参考节点,使得生成的 mst 最优。
1.3、优化位姿图 G G G,并得到所有marker在参考坐标系下的初始位姿 γ ~ i \tilde\gamma_i γ~i
这一步是论文中最复杂的部分。首先,为了防止outliers(位姿图
G
G
G中某些不太靠谱的边)败坏优化的过程,我们先计算 mst 中所有边的权重
ϖ
(
e
)
=
e
j
,
i
(
γ
^
j
,
i
)
\varpi(e)={\bf e}_{j,i}(\hat\gamma_{j,i})
ϖ(e)=ej,i(γ^j,i)的均值和标准差,对于不在 mst 中的边,凡是权重大于均值2.58倍的都去掉,剩下的所有边和节点组成的位姿图记作
G
′
G'
G′。然后对
G
′
G'
G′做进一步优化。
考虑
G
′
G'
G′中的一组循环节点
c
=
(
1
,
2
,
3
,
⋅
⋅
⋅
,
n
−
1
,
n
,
1
)
c=(1,2,3,\cdot\cdot\cdot,n-1,n,1)
c=(1,2,3,⋅⋅⋅,n−1,n,1),节点之间最优的边
γ
~
j
,
i
\tilde\gamma_{j,i}
γ~j,i应该满足下式:
I
4
×
4
=
γ
~
1
,
2
γ
~
2
,
3
⋅
⋅
⋅
γ
~
n
−
1
,
n
γ
~
n
,
1
{\bf I}_{4\times4}=\tilde\gamma_{1,2}\tilde\gamma_{2,3}\cdot\cdot\cdot\tilde\gamma_{n-1,n}\tilde\gamma_{n,1}
I4×4=γ~1,2γ~2,3⋅⋅⋅γ~n−1,nγ~n,1
即经过一个循环,节点 i \,i\, i仍能投影到原处。假设节点之间的初始位姿 γ ^ j , i \hat\gamma_{j,i} γ^j,i都是相对正确的,那我们应该最小化 γ ~ j , i \tilde\gamma_{j,i} γ~j,i与 γ ^ j , i \hat\gamma_{j,i} γ^j,i之间的加权距离,即:
min ∑ k ∈ c w k , k + 1 d ( γ ~ k , k + 1 , γ ^ k , k + 1 ) \text{min}\sum_{k\in c}w_{k,k+1}\,\text{d}(\tilde\gamma_{k,k+1},\hat\gamma_{k,k+1}) mink∈c∑wk,k+1d(γ~k,k+1,γ^k,k+1)
其中 w k , k + 1 = 1 e k , k + 1 ∑ k ∈ c 1 e k , k + 1 w_{k,k+1}=\cfrac{1}{{\bf e}_{k,k+1}\sum\limits_{k\in c}\cfrac{1}{{\bf e}_{k,k+1}}} wk,k+1=ek,k+1k∈c∑ek,k+111, w k , k + 1 w_{k,k+1} wk,k+1的值域为(0,1),并且 ∑ k ∈ c w k , k + 1 = 1 \sum\limits_{k\in c}w_{k,k+1}=1 k∈c∑wk,k+1=1,下面对 w k , k + 1 w_{k,k+1} wk,k+1的这两个性质进行推导:
令 e ′ ( c ) = ∑ k ∈ c 1 e k , k + 1 ∈ ( 0 , + ∞ ) , e ′ ′ ( c ) = ∏ k ∈ c e k , k + 1 w k , k + 1 = 1 e k , k + 1 e ′ ( c ) = 1 1 + e ′ ( c − k ) ∈ ( 0 , 1 ) , k ∈ c ; e ′ ( c − k ) ∈ ( 0 , + ∞ ) 表 示 e ′ ( c ) 中 没 有 1 e k , k + 1 这 一 项 ∑ k ∈ c w k , k + 1 = e ′ ′ ( c − 1 ) + ⋅ ⋅ ⋅ + e ′ ′ ( c − k ) + ⋅ ⋅ ⋅ + e ′ ′ ( c − n ) { ∏ k ∈ c e k , k + 1 } e ′ ( c ) = ( 1 e 1 , 2 + ⋅ ⋅ ⋅ + 1 e k , k + 1 + ⋅ ⋅ ⋅ 1 e n , 1 ) e ′ ′ ( c ) { ∏ k ∈ c e k , k + 1 } e ′ ( c ) = e ′ ′ ( c ) { ∑ k ∈ c 1 e k , k + 1 } { ∏ k ∈ c e k , k + 1 } e ′ ( c ) = 1 令\; {\bf e}'(c)=\sum_{k\in c}\cfrac{1}{{\bf e}_{k,k+1}}\in(0,+\infty),\;{\bf e}''(c)=\prod_{k\in c}{\bf e}_{k,k+1}\\ w_{k,k+1}=\cfrac{1}{{\bf e}_{k,k+1}{\bf e}'(c)}=\cfrac{1}{1+{\bf e}'(c-k)}\in(0,1),\;k\in c;{\bf e}'(c-k)\in(0,+\infty)表示{\bf e}'(c)中没有\cfrac{1}{{\bf e}_{k,k+1}}这一项\\ \sum_{k\in c}w_{k,k+1}=\cfrac{{\bf e}''(c-1)+\cdot\cdot\cdot+{\bf e}''(c-k)+\cdot\cdot\cdot+{\bf e}''(c-n)}{\left\{\prod\limits_{k\in c}{\bf e}_{k,k+1}\right\}{\bf e}'(c)}=\cfrac{(\cfrac{1}{{\bf e}_{1,2}}+\cdot\cdot\cdot+\cfrac{1}{{\bf e}_{k,k+1}}+\cdot\cdot\cdot\cfrac{1}{{\bf e}_{n,1}}){\bf e}''(c)}{\left\{\prod\limits_{k\in c}{\bf e}_{k,k+1}\right\}{\bf e}'(c)}=\cfrac{e''(c)\left\{\sum\limits_{k\in c}\cfrac{1}{{\bf e}_{k,k+1}}\right\}}{\left\{\prod\limits_{k\in c}{\bf e}_{k,k+1}\right\}{\bf e}'(c)}=1 令e′(c)=k∈c∑ek,k+11∈(0,+∞),e′′(c)=k∈c∏ek,k+1wk,k+1=ek,k+1e′(c)1=1+e′(c−k)1∈(0,1),k∈c;e′(c−k)∈(0,+∞)表示e′(c)中没有ek,k+11这一项k∈c∑wk,k+1={k∈c∏ek,k+1}e′(c)e′′(c−1)+⋅⋅⋅+e′′(c−k)+⋅⋅⋅+e′′(c−n)={k∈c∏ek,k+1}e′(c)(e1,21+⋅⋅⋅+ek,k+11+⋅⋅⋅en,11)e′′(c)={k∈c∏ek,k+1}e′(c)e′′(c){k∈c∑ek,k+11}=1
对于
γ
~
=
[
R
~
t
~
0
1
]
\tilde\gamma=\begin{bmatrix}\tilde{\bf R}&\tilde{\bf t}\\{\bf 0}&1\end{bmatrix}
γ~=[R~0t~1]和
γ
^
=
[
R
^
t
^
0
1
]
\hat\gamma=\begin{bmatrix}\hat{\bf R}&\hat{\bf t}\\{\bf 0}&1\end{bmatrix}
γ^=[R^0t^1],有:
R
~
1
,
2
⋅
⋅
⋅
R
~
k
,
k
+
1
⋅
⋅
⋅
R
~
n
,
1
=
R
^
1
,
2
E
1
,
2
α
1
,
2
⋅
⋅
⋅
R
^
k
,
k
+
1
E
k
,
k
+
1
α
k
,
k
+
1
⋅
⋅
⋅
R
^
n
,
1
E
n
,
1
α
n
,
1
=
I
3
×
3
(7)
{\bf {\tilde R}}_{1,2}\cdot\cdot\cdot{\bf {\tilde R}}_{k,k+1}\cdot\cdot\cdot{\bf {\tilde R}}_{n,1}= {\bf {\hat R}}_{1,2}{\bf E}_{1,2}^{\alpha_{1,2}}\cdot\cdot\cdot{\bf {\hat R}}_{k,k+1}{\bf E}_{k,k+1}^{\alpha_{k,k+1}}\cdot\cdot\cdot{\bf {\hat R}}_{n,1}{\bf E}_{n,1}^{\alpha_{n,1}}={\bf I}_{3\times3}\tag{7}
R~1,2⋅⋅⋅R~k,k+1⋅⋅⋅R~n,1=R^1,2E1,2α1,2⋅⋅⋅R^k,k+1Ek,k+1αk,k+1⋅⋅⋅R^n,1En,1αn,1=I3×3(7)
其中,
E
k
,
k
+
1
α
k
,
k
+
1
=
exp
{
α
k
,
k
+
1
ln
E
k
,
k
+
1
}
{\bf E}_{k,k+1}^{\alpha_{k,k+1}}=\text{exp}\{\alpha_{k,k+1}\,\text{ln}{\bf E}_{k,k+1}\}
Ek,k+1αk,k+1=exp{αk,k+1lnEk,k+1},
α
k
,
k
+
1
=
1
/
w
k
,
k
+
1
∑
j
∈
c
1
/
w
j
,
j
+
1
=
e
k
,
k
+
1
∑
j
∈
c
e
j
,
j
+
1
∈
[
0
,
1
]
\alpha_{k,k+1}=\cfrac{1/w_{k,k+1}}{\sum\limits_{j\in c}1/w_{j,j+1}}=\cfrac{{\bf e}_{k,k+1}}{\sum\limits_{j\in c}{\bf e}_{j,j+1}}\in[0,1]
αk,k+1=j∈c∑1/wj,j+11/wk,k+1=j∈c∑ej,j+1ek,k+1∈[0,1],
∑
k
∈
c
α
k
,
k
+
1
=
1
\sum\limits_{k\in c}\alpha_{k,k+1}=1
k∈c∑αk,k+1=1,
e
j
,
i
(
γ
j
,
i
)
=
∑
t
,
t
′
∈
F
i
,
j
γ
j
,
i
∈
χ
j
,
i
ε
(
γ
j
,
i
t
′
,
f
t
)
{\bf e}_{j,i}(\gamma_{j,i})=\sum\limits_{t,t'\in\mathcal{F}_{i,j}\\\gamma_{j,i}\,\in\chi_{j,i}}\varepsilon(\gamma_{j,i}^{t'},f^t)
ej,i(γj,i)=t,t′∈Fi,jγj,i∈χj,i∑ε(γj,it′,ft)。注意这里
E
k
,
k
+
1
α
k
,
k
+
1
\,{\bf E}_{k,k+1}^{\alpha_{k,k+1}}\;
Ek,k+1αk,k+1中的
α
k
,
k
+
1
{\alpha_{k,k+1}}
αk,k+1并不是一个普通的右上标,而是代表矩阵的指数,可以理解为旋转矩阵的幂运算,即有:
E
k
,
k
+
1
α
1
,
2
⋅
⋅
⋅
E
k
,
k
+
1
α
k
,
k
+
1
⋅
⋅
⋅
E
k
,
k
+
1
α
n
,
1
=
E
k
,
k
+
1
α
1
,
2
+
⋅
⋅
⋅
+
α
k
,
k
+
1
+
⋅
⋅
⋅
+
α
n
,
1
=
E
k
,
k
+
1
{\bf E}_{k,k+1}^{\alpha_{1,2}}\cdot\cdot\cdot{\bf E}_{k,k+1}^{\alpha_{k,k+1}}\cdot\cdot\cdot{\bf E}_{k,k+1}^{\alpha_{n,1}}={\bf E}_{k,k+1}^{\alpha_{1,2}\;+\cdot\cdot\cdot+\;\alpha_{k,k+1}\;+\cdot\cdot\cdot+\;\alpha_{n,1}}={\bf E}_{k,k+1}
Ek,k+1α1,2⋅⋅⋅Ek,k+1αk,k+1⋅⋅⋅Ek,k+1αn,1=Ek,k+1α1,2+⋅⋅⋅+αk,k+1+⋅⋅⋅+αn,1=Ek,k+1
其中每一个 E k , k + 1 α k , k + 1 \,{\bf E}_{k,k+1}^{\alpha_{k,k+1}}\; Ek,k+1αk,k+1都是与 E k , k + 1 {\bf E}_{k,k+1} Ek,k+1同轴的旋转矩阵,即旋转 E k , k + 1 {\bf E}_{k,k+1} Ek,k+1由这些微小的旋转 E k , k + 1 α k , k + 1 \,{\bf E}_{k,k+1}^{\alpha_{k,k+1}}\; Ek,k+1αk,k+1组成。

那么(7)式表示的到底是什么意思?就是说,比如在上图所示的一个循环 c = ( 1 , 2 , 4 , 3 ) c=(1,2,4,3) c=(1,2,4,3)中,我们可以给每个边添加一个微小的误差项,使得这个循环满足(7)式。同样对于循环 c = ( 1 , 2 , 5 , 3 ) c=(1,2,5,3) c=(1,2,5,3),我们也可以给每个边添加一个微小的误差项,使得这个循环满足(7)式。即
{ R ^ 1 , 2 E 1 , 2 α 1 , 2 R ^ 2 , 4 E 2 , 4 α 2 , 4 R ^ 4 , 3 E 4 , 3 α 4 , 3 R ^ 3 , 1 E 3 , 1 α 3 , 1 = I 3 × 3 R ^ 1 , 2 E 1 , 2 α 1 , 2 R ^ 2 , 5 E 2 , 5 α 2 , 5 R ^ 5 , 3 E 5 , 3 α 5 , 3 R ^ 3 , 1 E 3 , 1 α 3 , 1 = I 3 × 3 \begin{cases}{\bf {\hat R}}_{1,2}{\bf E}_{1,2}^{\alpha_{1,2}}\,{\bf {\hat R}}_{2,4}{\bf E}_{2,4}^{\alpha_{2,4}}\,{\bf {\hat R}}_{4,3}{\bf E}_{4,3}^{\alpha_{4,3}}\,{\bf {\hat R}}_{3,1}{\bf E}_{3,1}^{\alpha_{3,1}}={\bf I}_{3\times3}\\ {\bf {\hat R}}_{1,2}{\bf E}_{1,2}^{\alpha_{1,2}}\,{\bf {\hat R}}_{2,5}{\bf E}_{2,5}^{\alpha_{2,5}}\,{\bf {\hat R}}_{5,3}{\bf E}_{5,3}^{\alpha_{5,3}}\,{\bf {\hat R}}_{3,1}{\bf E}_{3,1}^{\alpha_{3,1}}={\bf I}_{3\times3}\end{cases} {R^1,2E1,2α1,2R^2,4E2,4α2,4R^4,3E4,3α4,3R^3,1E3,1α3,1=I3×3R^1,2E1,2α1,2R^2,5E2,5α2,5R^5,3E5,3α5,3R^3,1E3,1α3,1=I3×3
对于旋转矩阵 R k , k + 1 {\bf { R}}_{k,k+1} Rk,k+1,它的误差项是一个与之同轴的旋转矩阵 E k , k + 1 α k , k + 1 {\bf E}_{k,k+1}^{\alpha_{k,k+1}} Ek,k+1αk,k+1,这个旋转矩阵的旋转角度由 α k , k + 1 \alpha_{k,k+1} αk,k+1确定, α k , k + 1 \alpha_{k,k+1} αk,k+1与节点 k \,k\, k到节点 k + 1 \,k+1 k+1之间的重投影误差有关。(这一部分我不是特别理解,待修正)
2、如何获得关键帧在参考世界坐标系下的最优初始位姿 γ ~ t \,\tilde{\gamma}^t\, γ~t
未完成。。。















 1925
1925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









