







Spatially-Adaptive Feature Modulation for Efficient Image Super-Resolution
论文地址:
主要问题:
现有的图像超分辨率方法通常使用全局的注意力机制来聚合特征,这可能导致模型关注到无关区域的特征,从而影响模型的性能和效率。
解决方案:
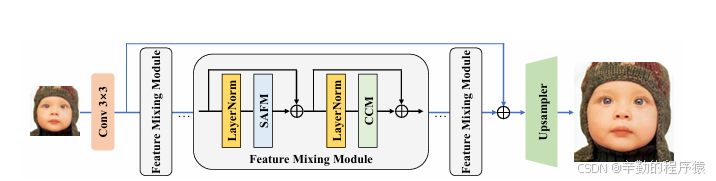
论文提出了一种空间自适应特征调制 (SAFM) 模块,该模块通过学习空间上下文信息来动态地调整特征权重,从而增强有用特征并抑制无关特征。
SAFM模块的主要特点:
-
空间自适应: SAFM模块通过学习空间上下文信息来动态地调整特征权重,从而能够更好地捕捉图像中的局部细节和结构信息。
-
特征调制: SAFM模块通过调制特征权重来增强有用特征并抑制无关特征,从而提高模型的性能和效率。
-
高效性: SAFM模块的计算复杂度较低,可以有效地提高模型的运行速度。
SAFM模块的具体实现:
-
空间上下文学习: SAFM模块首先通过一个卷积层学习图像中的空间上下文信息。
-
特征权重调制: SAFM模块根据学习到的空间上下文信息,通过一个调制函数来动态地调整特征权重。
-
特征融合: SAFM模块将调制后的特征与原始特征进行融合,从而得到最终的特征表示。
适用任务:
SAFM模块可以应用于各种图像处理任务,包括:
-
图像超分辨率: SAFM模块可以有效地提高图像超分辨率模型的性能和效率。
-
图像去噪: SAFM模块可以去除图像中的噪声,并保留图像的细节信息。
-
图像去模糊: SAFM模块可以去除图像中的模糊,并恢复图像的清晰度。
-
目标检测任务中的应用:
SAFM模块可以应用于目标检测任务中的特征提取部分,以提高特征的质量和效率。具体来说,SAFM模块可以放在以下位置:
-
主干网络: SAFM模块可以替换主干网络中的卷积层,以提高特征的提取能力。
-
特征融合模块: SAFM模块可以用于融合不同尺度的特征,以提高特征的丰富度。
-
注意力机制: SAFM模块可以与注意力机制结合使用,以提高模型的关注能力。
SAFM模块通过学习空间上下文信息来动态地调整特征权重,从而有效地解决了基于全局注意力机制的图像处理方法中存在的问题。SAFM模块可以应用于各种图像处理任务,包括图像超分辨率、图像去噪和图像去模糊等。在目标检测任务中,SAFM模块可以放在主干网络、特征融合模块或注意力机制中,以提高特征的质量和效率。
即插即用代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class DMlp(nn.Module):
def __init__(self, dim, growth_rate=2.0):
super().__init__()
hidden_dim = int(dim * growth_rate)
self.conv_0 = nn.Sequential(
nn.Conv2d(dim, hidden_dim, 3, 1, 1, groups=dim),
nn.Conv2d(hidden_dim, hidden_dim, 1, 1, 0)
)
self.act = nn.GELU()
self.conv_1 = nn.Conv2d(hidden_dim, dim, 1, 1, 0)
def forward(self, x):
x = self.conv_0(x)
x = self.act(x)
x = self.conv_1(x)
return x
class SMFA(nn.Module):
def __init__(self, dim=36):
super(SMFA, self).__init__()
self.linear_0 = nn.Conv2d(dim, dim * 2, 1, 1, 0)
self.linear_1 = nn.Conv2d(dim, dim, 1, 1, 0)
self.linear_2 = nn.Conv2d(dim, dim, 1, 1, 0)
self.lde = DMlp(dim, 2)
self.dw_conv = nn.Conv2d(dim, dim, 3, 1, 1, groups=dim)
self.gelu = nn.GELU()
self.down_scale = 8
self.alpha = nn.Parameter(torch.ones((1, dim, 1, 1)))
self.belt = nn.Parameter(torch.zeros((1, dim, 1, 1)))
def forward(self, f):
_, _, h, w = f.shape
y, x = self.linear_0(f).chunk(2, dim=1)
x_s = self.dw_conv(F.adaptive_max_pool2d(x, (h // self.down_scale, w // self.down_scale)))
x_v = torch.var(x, dim=(-2, -1), keepdim=True)
x_l = x * F.interpolate(self.gelu(self.linear_1(x_s * self.alpha + x_v * self.belt)), size=(h, w),
mode='nearest')
y_d = self.lde(y)
return self.linear_2(x_l + y_d)
if __name__ == '__main__':
input = torch.randn(1, 36, 32, 32) # 输入b c h w
block = SMFA(dim=36)
output = block(input)
print(output.size())如果你对YOLO改进感兴趣可以进群交流,群中有答疑(QQ:828370883)



















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









