







目录
一、TL;DR
-
推出了DataComp,这是一个围绕从Common Crawl中提取的128亿图像-文本对候选池构建的数据集实验平台和数据实验范式,可用于各种filter的数据实验(具备不同规模实验能力)
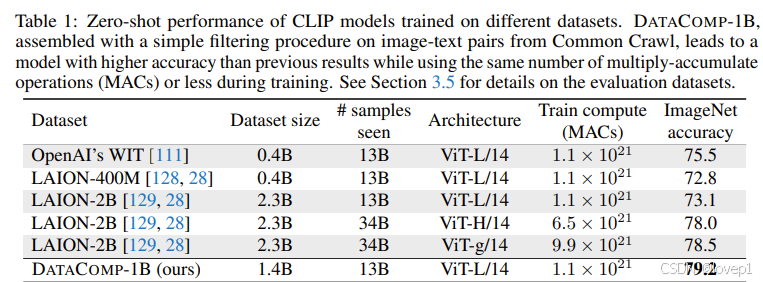
- 提出了一个工作流,产生了DataComp-1B,同计算资源情况下,Vit-L/14实现zero-shot-79.2%的sota
- 核心可学习的地方:除了结论以外,各种消融实验的设计和整个范式的学习
二、方法
2.1 为什么要单独研究数据质量?
- 即使是LAION2B这种公开数据集,由于其规模/来源等,人们也不清楚其内容到底包括了什么
- paper指出尽管有超过千种针对算法的消融实验设计,但没有人专门去针对数据集设计去研究
- 数据集目前缺乏一种像模型改进那样持续稳定的开发流程,这种流程能够使得模型类似损失函数一样持续优化模型性能
2.2 数据质量的研究范式
- 核心贡献点1-整体方式:
- 提出DataComp,相较于传统的dataset不变,改变算法的方式,而是保持整个训练代码和计算资源不变,改变新的数据集从而达到指标的提升等创新
- 下游使用包括38个分类和检索的测试平台对模型进行评分,这些任务包括ImagenetV2、DTD、、COCO等
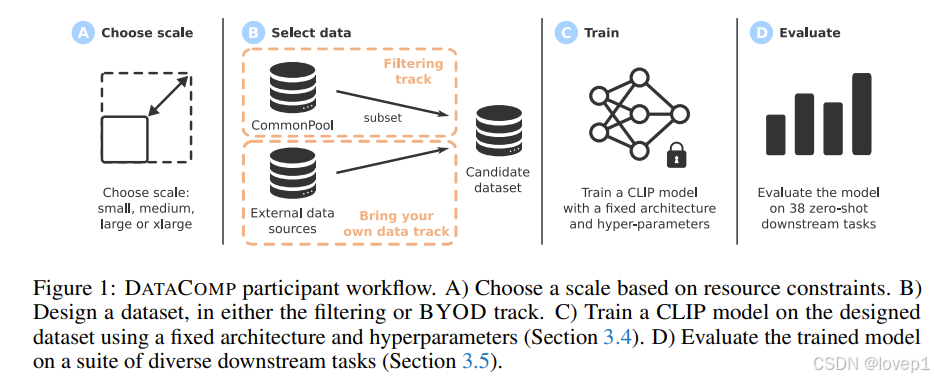
- 核心贡献点2-两个赛道:
- 筛选赛道:paper给出了Common Craw收集的128亿图文对,从这个common pool里面筛选出最佳子集用于训练
- 自带数据(BYOD):参与者可以利用任何数据源,只要它不与我们的评估测试平台重叠即可。
- 核心贡献点3-对数据集的设计的scale也进行了研究和设计:
- DataComp包括4个规模,从1280万-> 128亿样本,不同规模的指标如下所示:
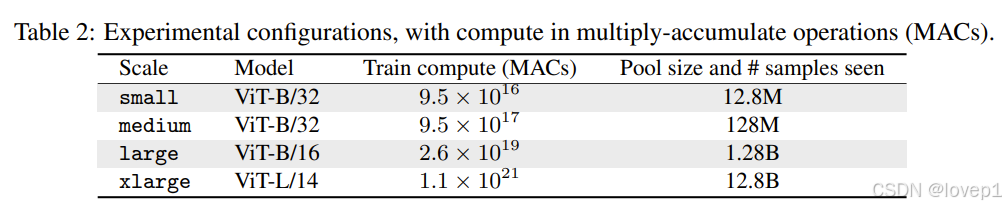
- 在作者提供的A100集群上,单次训练运行的成本范围从4到40000 GPU小时,但结果的筛选排名的方法在不同规模上基本能够做到一致,就是说方法的有效性是通用的
- DataComp包括4个规模,从1280万-> 128亿样本,不同规模的指标如下所示:
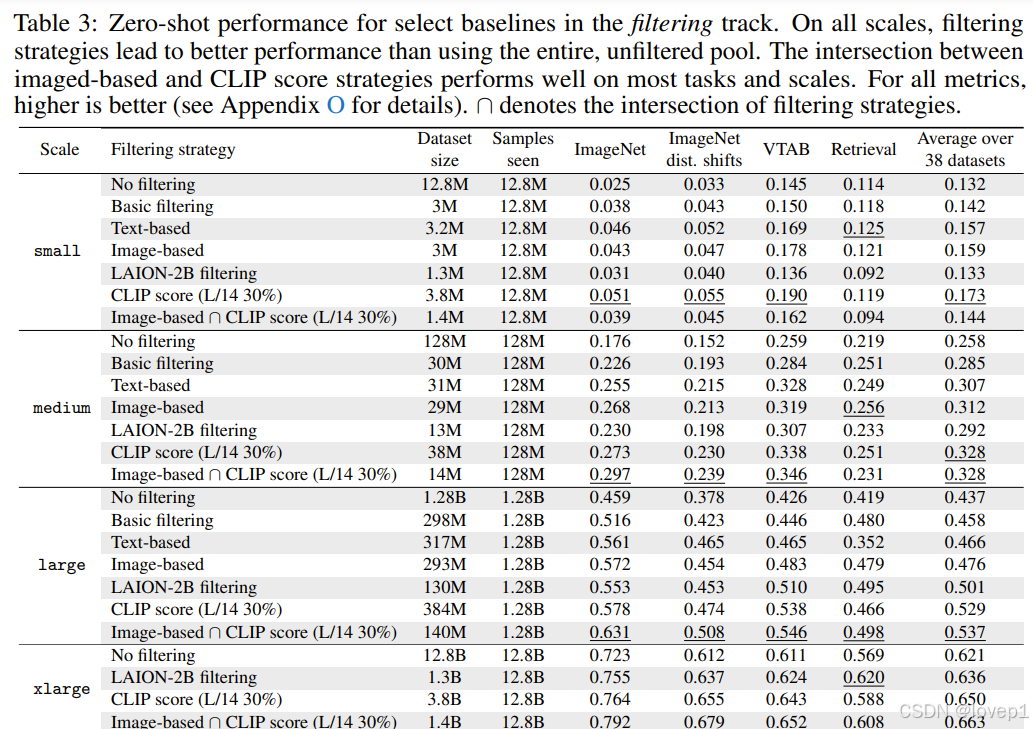
- 核心贡献点4-设计和进行了300多个baseline实验:
- 包括相关关键词筛选、基于图像向量的筛选和基于clip的分数进行筛选等技术
- 关键结果:更小、更严格的数据集可以产生比来自同一池子的大型数据集泛化性能更强的模型
- 在128亿规模下,最好的筛选规模将Imagenet提升了6.9个点
- 在BYOD下,增加1.09亿数据,提点1.2个点
- 在128亿规模下,最好的筛选规模将Imagenet提升了6.9个点
- 核心贡献点5-提出DataComp-1B:
- benchmark的zero-shot上面达到了79.2%。与在LAION-2B上训练约3倍时间的更大CLIP ViT-g/14模型相比,计算成本降低了9倍,在使用相同的训练资源的情况下,比OpenAI的原始CLIP ViT-L/14高出3.7个百分点。
- benchmark的zero-shot上面达到了79.2%。与在LAION-2B上训练约3倍时间的更大CLIP ViT-g/14模型相比,计算成本降低了9倍,在使用相同的训练资源的情况下,比OpenAI的原始CLIP ViT-L/14高出3.7个百分点。
三、其他的工作(related work)
3.1 传统的做法
经典的研究通过数据集清理和异常值移除来丢弃可能导致模型出现不良偏差的样本。对应开发的一些列的子集选择算法,目标是从整个数据集中选择与完整数据集训练相同的性能(其实这个很牛逼啊) 问题是这些工作无法扩展到大规模数据上,更近期的一些工作都是在小的规模上做的,比如TFC-5M,这些场景通常会无法反映几个问题:
问题是这些工作无法扩展到大规模数据上,更近期的一些工作都是在小的规模上做的,比如TFC-5M,这些场景通常会无法反映几个问题:
- 带噪声的图像-文本对,而不是带有类别标签的图像;
- 大规模数据集(例如数十亿样本)
DataComp通过data-centric和大规模图文对相结合,来填补这个空白
3.2 数据剪枝和去重(paper直接翻译)
这个地方也许是我之前忽略的工作,后面详细补充
Sorscher等人表明,数据剪枝可以改善在ImageNet上的传统扩展趋势,但没有考虑图像-文本训练或更大的数据集。Raffel等人在创建C4语料库时移除了句子冗余。后续的研究进一步证明了去重对于更好的语言模型的益处。Radenovic等人为图像-文本数据集引入了CAT过滤——一个基于规则的系统,用于保留高质量样本。Abbas等人提出了SemDeDup,它从经过CAT过滤的LAION-440M子集开始,进一步利用聚类去除语义上的重复项。DataComp促进了更大规模(即128亿样本规模)的数据为中心的研究,并为数据集创建算法之间的公平比较提供了一个共同的实验设置。
四、DataComp的benchmark
4.1 竞赛条件限制和目标
更大的数据集通常会导致性能更好的模型,但是存在2个关键的约束:候选池大小(即要收集的图像-文本对的数量)和训练计算资源,数据集数量很好理解,训练计算资源要求的是规定训练期间看到的总样本数;
- 假设数据集A和B分别有64亿和32亿图像-文本对。在这个规模下,我们通过两次遍历A进行训练,而对B进行四次遍历。
- 我们实验的一个关键结果是,更小、筛选更严格的数据集可以导致泛化能力更强的模型。
4.2 数据使用流程
总体流程:URL提取与数据下载、NSFW(Not Safe For Work,不适宜工作场合的内容)检测、评估集去重以及面部模糊处理;
细节:略,不在本文描述的重点范围里面
这里面涉及到了使用NSFW、图片集去重、还有面部模糊对模型效果的影响一些实验参数,如果感兴趣还是需要参考原文
4.3 训练过程
创建了一个通用的实验设置,通过固定训练过程来实现可比的实验,使用clip的配置来from stracth来训练,但是模型是使用openclip训练的,不是openai的代码,训练的iteration由数据集大小决定
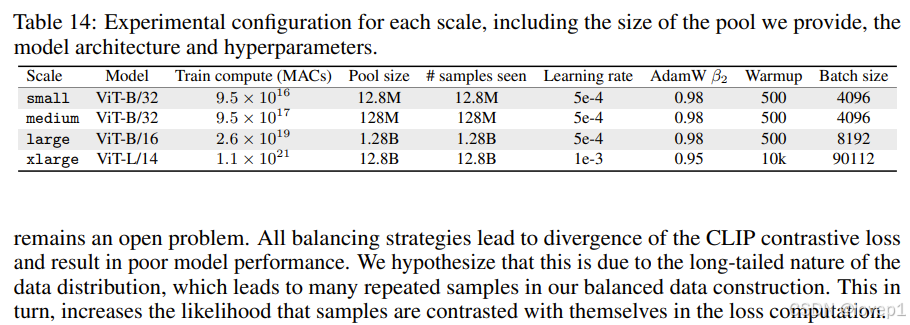
上面这个是具体训练的超参数,可以看到非常详细的说pool size
4.4 测试细节
五、Baseline(常见的样本集选用方式)
5.1 从池子中筛选子集的baseline建立
作者选取了6种基线方式对数据集进行筛选,如下所示(我们设计消融实验的时候可以进行参考):
- 无筛选:
- 直接使用整个数据池子作为子集使用,不进行任何筛选,则datsest_size == seen_size,则只需要对完整的数据进行一次遍历,epoch=1
- random 子集:
- 为了区分增加训练资源和增加数据集的影响(由于是random),选择1%、10%、25%、50%和75%的子集
- 基本筛选:
- 选用上文提到的经典的一些基于图像的做法,
- CLIP分数和LAION筛选:
- 使用CLIP分数筛选,并使用open-ai的VIT-B/32和VIT-L/14的模型,并且选用了不同的clip的分数配置
- 使用CLIP分数筛选,并使用open-ai的VIT-B/32和VIT-L/14的模型,并且选用了不同的clip的分数配置
- 基于文本的筛选:
- 选择与Imagenet类别名称重叠的文本的样本
- 基于图像的筛选(最佳做法):
- 视觉内容与ImageNet类别有重叠的示例子集,具体做法:使用fasttext和标题长度筛选后,利用VIT-L/14的模型提取向量,并聚类成10万个个组,然后为每个Imagenet训练样本找到最近邻的组,并保留这些组的样本,分别使用Imagenet21K和Imagenet-1K来应用这一流程,从而形成2个子集
5.2 benchmark分析和结论
如下所示,基本可以看到无论是small、large等级别filter的有效方式是一样的,与前文的结论一致,其中Image-based的方法是没有引入文本模态的情况下的最佳做法,引入文本模态以后,可以发现是image-based和CLIP的组合方法效果是最好的,但是在small情况下,可以发现效果是比较差的,这里我认为是clip的多模态数据本身其实是需要一定规模的,1.4M的数据可能存在对比学习难以收敛等情况,但总体跨级别这个趋势是对的
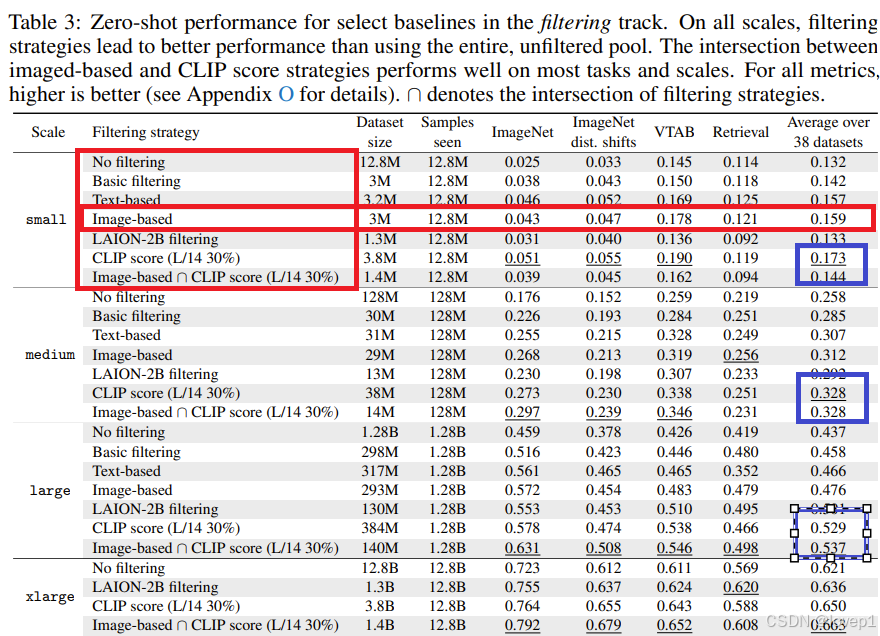
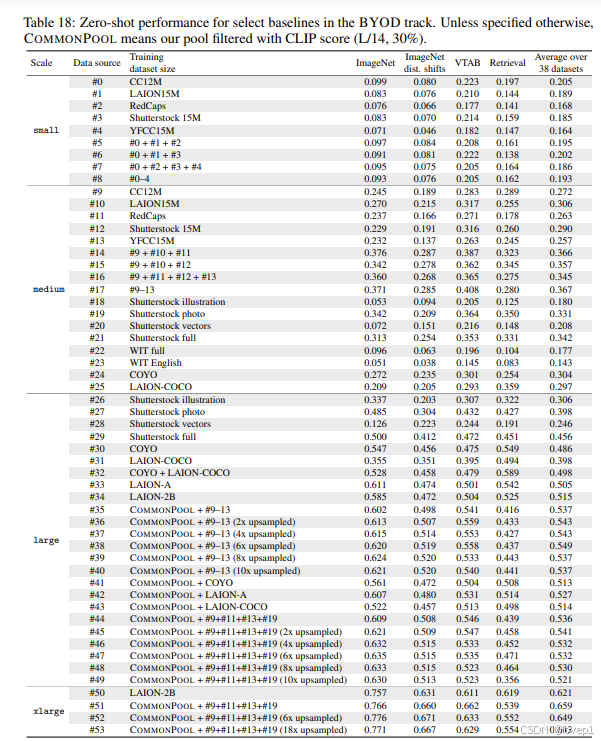
5.2 BYOD的baseline建立
使用了外部数据源的四个中等规模的数据集(样本数量在1000万到5800万之间)——CC12M、YFCC15M、RedCaps和Shutterstock,以及规模更大的LAION-2B(略-不是博客的重点):
5.3 进一步结论和讨论
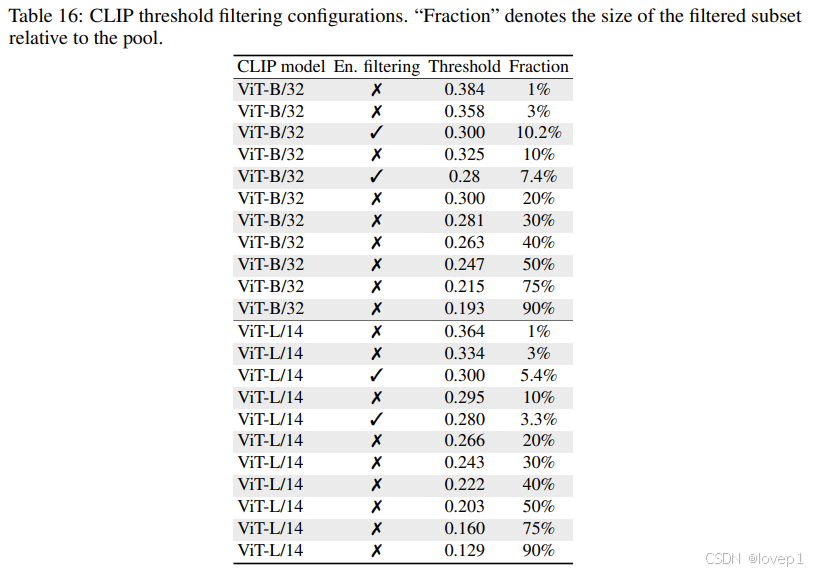
数据多样性和重复之间的权衡。在下图中,我们看到随机选择池的子集几乎没有效果,并且当只使用小部分时,性能会显著下降。当使用CLIP分数进行筛选时,最佳训练集来自选择池中约30%分数最高的样本。随机子集与CLIP分数筛选之间的性能趋势差异突显了筛选策略在选择样本时的重要性。
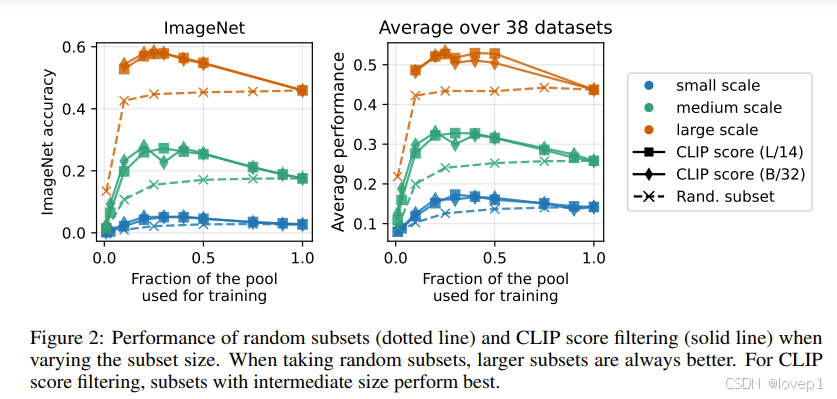
5.4 跨规模和训练变化的一致性
-
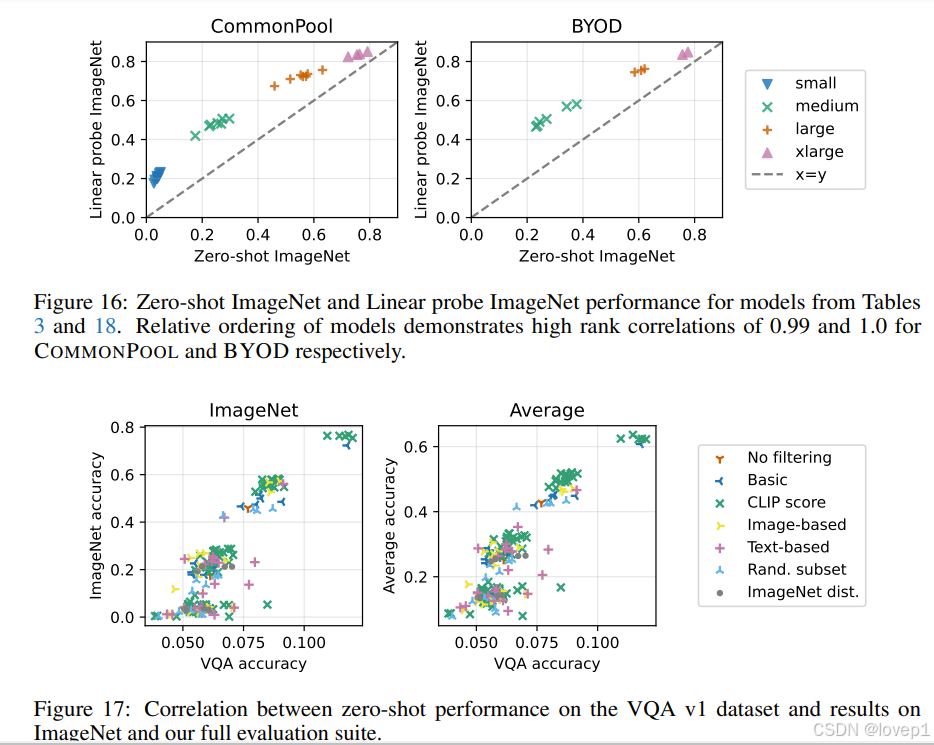
跨规模一致性:不同筛选策略在不同规模下的排名通常是一致的。例如,小规模和大规模的ImageNet准确率之间的排名相关性为0.9。
-
跨训练变化的一致性:即使在不同的模型架构(如ViT-B/16和ViT-B/32)上进行训练,DataComp-1B的性能仍然优于其他数据集
六、其他(附录)
data filter在小规模数据集上也是可行的:
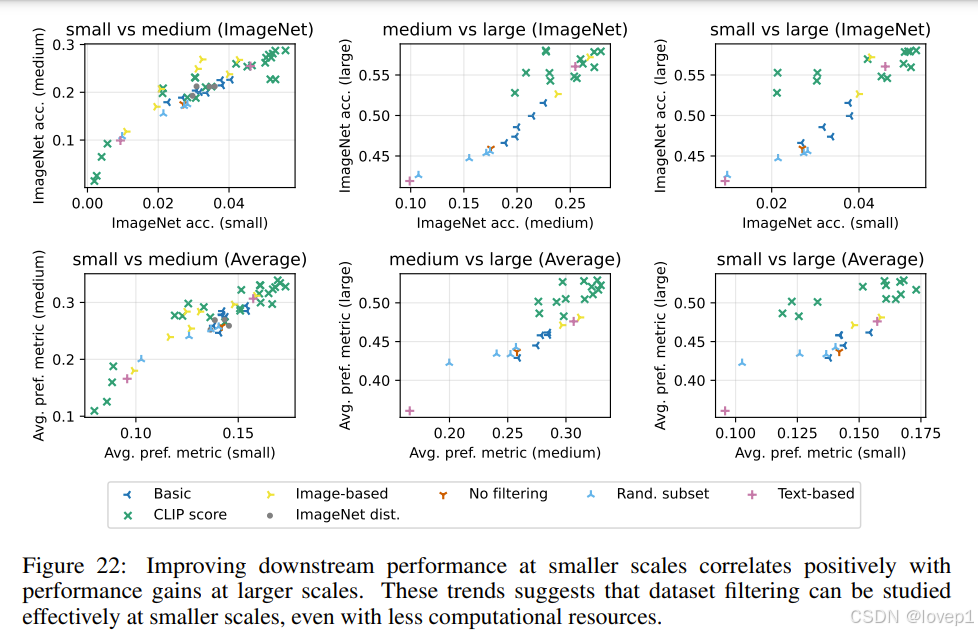

















 1387
1387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









