







一、TL;DR
- 模型训练上,设计了一种渐进式的训练方法,将掩码视频建模、跨模态对比学习和下一个token预测统一起来,
- 数据质量上,强调时空一致性,通过语义分割视频并生成视频-音频-caption,改善了视频和文本之间的对齐
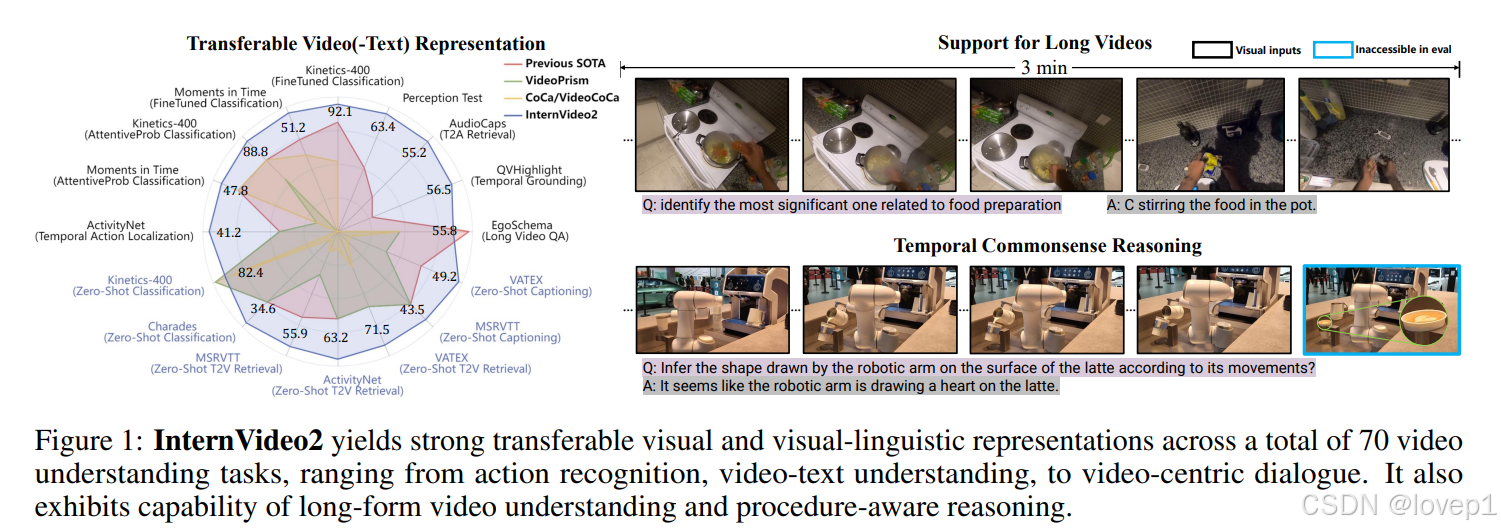
- 将参数量扩展到了60亿,视频识别、视频-文本任务、音频和以及视频中心对话取得sota
二、方法与训练
2.1 渐进式对齐训练
Internvideo2是通过渐进式训练方案构建的(小公司的人看看就行了,我是直接tune head),具体如下所示:
- 通过未掩码重建捕捉时空结构(only video)
- 与其他模态的语义对齐(text/autio/img)
- 通过下一个video token预测来增强模型的开放式对话能力(LLMs/MLLMS)
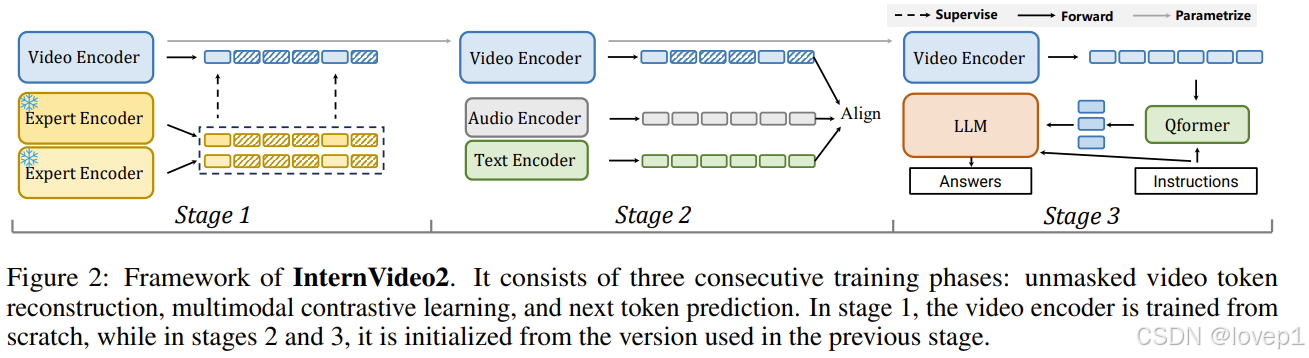
2.1.1 stage1:Reconstructing Unmasked Video Tokens
本阶段,模型学习重建unmasked的video token,使视频编码器能够发展基本的时空感知能力。为了估计已经存在的tokens,采用不同方式训练的视觉编码器InternVit作为代理。此时只有单模态:
具体怎么做?
- 使用InternVL-6B和VideoMAEv2-g的方法,通过简单的投影层将未掩码的知识传递给模型。
- 训练时,我们将完整视频输入到不同的教师模型中,并在多模态模型InternVL和运动感知模型VideoMAEv2的语义指导下逐帧mask掉掉80%的标记。只对齐未掩码的标记,通过最小化学生模型和教师模型之间的均方误差(MSE)来实现。学习目标是重建剩余的token,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1843
1843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









