







自上而下
- Cascaded Pyramid Network
- Stacked Hourglass Networks
- Alphapose
- Simple Baseline
- HRNet
自下而上
- openpose
simple baseline
作者看法:
姿态识别的信息特征提取的关键在于如何将小的feature map变大。obtaining high resolution feature maps is crucial, but no matter how
综述:
our method combines the upsampling and convolutional parameters into deconvolutional layers in a much simpler way, without using skip layer connections.
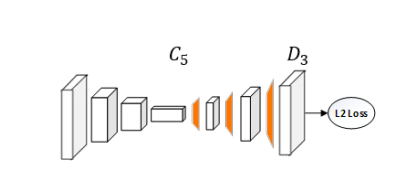
Our method simply adds a few deconvolutional layers over the last convolution stage in the ResNet, called C5.
Loss
Mean Squared Error (MSE) is used as the loss between
the predicted heatmaps and targe
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









