








✨点击这里✨:🚀原文链接:(更好排版、视频播放、社群交流、最新AI开源项目、AI工具分享都在这个公众号!)
你可以直接和数据库对话了!DB-GPT 用LLM定义数据库下一代交互方式,数据库领域的GPT、开启数据3.0 时代
🤖️ DB-GPT 是一个 开源的AI原生数据应用开发框架 。 让围绕数据库构建大模型应用更简单,更方便。

Hello,大家好。今天介绍DB-GPT,这是一个11.8k Star的开源项目,挺精彩的! DB-GPT
目的是构建大模型领域的基础设施,通过开发 多模型管理(SMMF) 、 Text2SQL 效果优化、 RAG框架 以及优化、
Multi-Agents 框架协作、 AWEL (智能体工作流编排)等多种技术能力,
在开始介绍这个项目之前,首先我想提个问题: 通用模型 真的能解决所有问题吗?我们是否需要 领域模型 ?展望未来, 多模型
之间将如何协作与交互呢?
我们也许需要3层的大模型交互架构:
● 通用大语言模型(> 100B)● 领域大语言模型(10~70B)● 工具类模型(<10B)
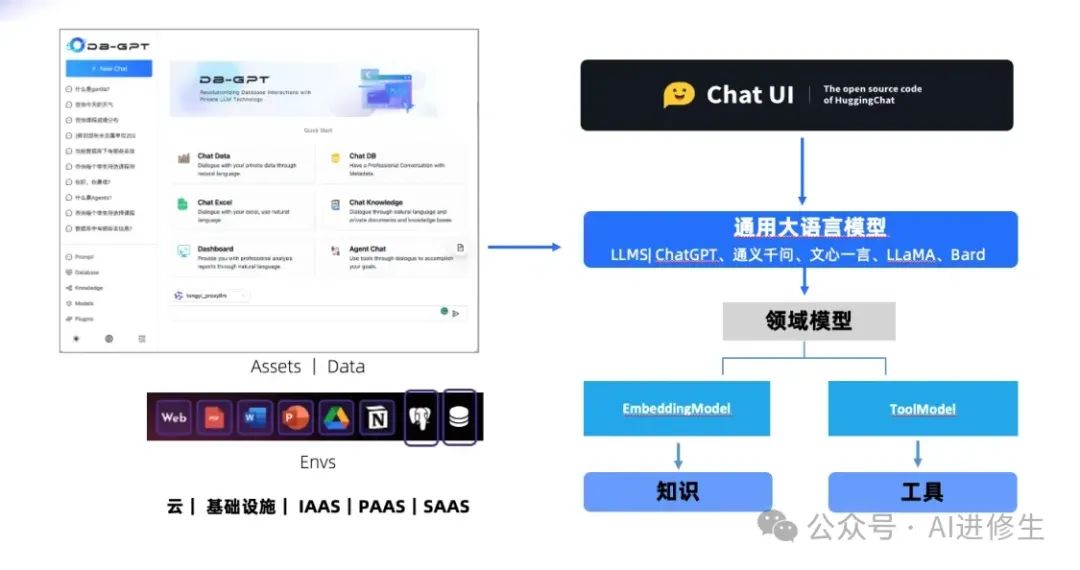
在深入思考 自然语言理解和语义分析 时,我们意识到其复杂性远超我们的想象。尽管如今有许多开源模型可以进行自然语言对话,但能够通过明确的
提示词(Prompt) 获得确定结果的模型却寥寥无几。只有像ChatGPT和 GPT-4
这样的模型才能表现得相对稳定。这也揭示了一个事实:通用大语言模型的体量巨大、入门门槛高,因此注定这一层的市场会呈现 寡头垄断
的局面,最终只会有少数效果最佳的模型存活。
通用大模型的迭代符合 数据飞轮理论
:效果越好,先发优势越明显,模型便能获得更好的训练数据,形成增长飞轮。因此,拥有强大效果的模型将吸引更多用户,进而通过用户反馈不断优化自身,进一步拉大与其他模型的差距。
那么,为什么需要 领域模型层
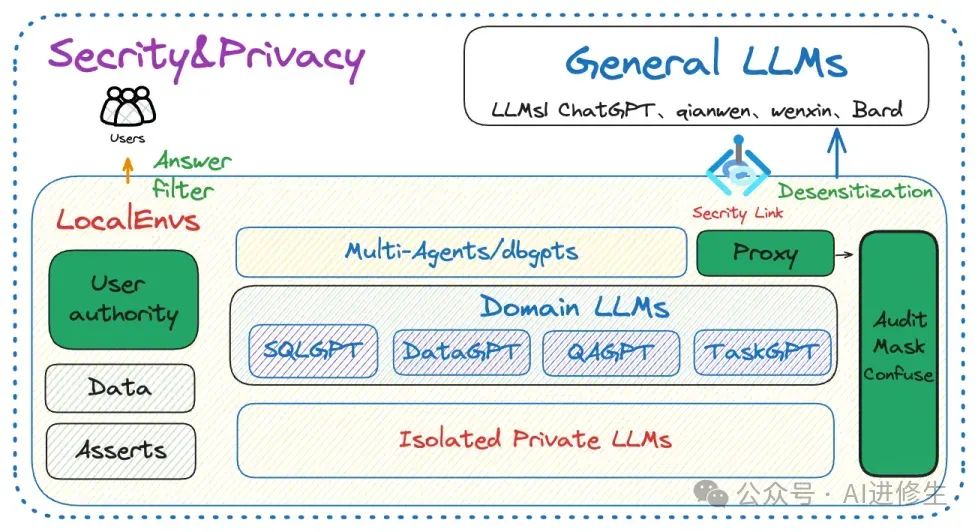
(或垂直模型层)呢?尽管通用大模型强大,但它们无法涵盖所有领域的专业知识。而且企业也不会将核心数据资产交给通用大模型,因为在模型层内进行数据加密与隐私保护几乎是个伪命题。那么,如何在保护数据的同时兼顾效果呢?我的答案是引入领域模型层,将其与通用模型在
私有数据资产上解耦 。内部核心业务交互由领域模型层处理,而交互层通过通用模型进行下发,并在通用模型层与领域模型层之间设置
安全与隐私防护机制 。
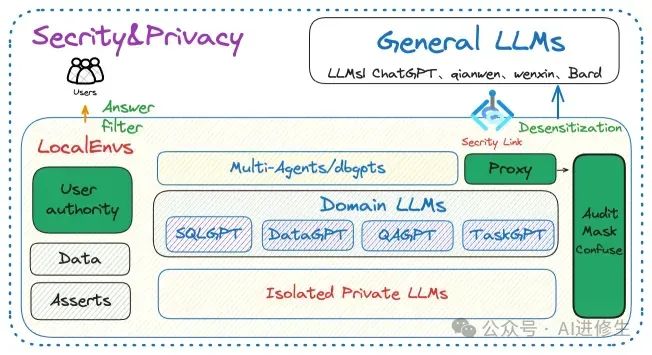
那么领域层都有了,为什么还要有 第三层工具模型
?这个主要是高精度与成本。针对非常细分的场景去做任务的时候,我们其实不太需要模型掌握太多的泛化或者推理的能力。恰恰相反,我们需要的是最低成本确定性完成某一任务的能力。比如生产线上的工人,你需要让他去理解与推敲公司的战略方向吗?嗯,高质量完成执行就行了。
** 🚀 数据3.0 时代,基于模型、数据库,企业/开发者可以用更少的代码搭建自己的专属应用。 **
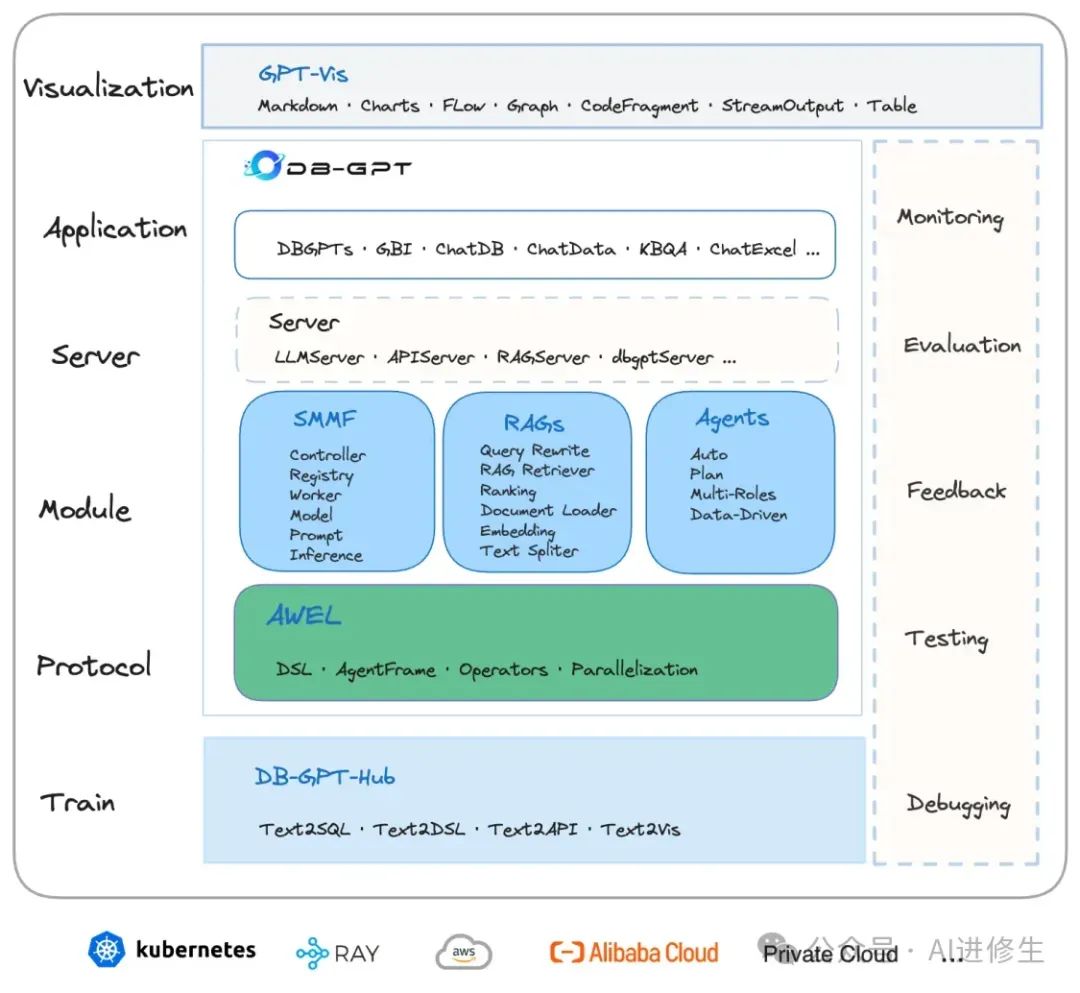
DB-GPT的架构与特点
该框架专为文本到 SQL 任务而设计,允许使用开源数据集轻松对各种 LLM 进行微调。
作为一种开源AI原生数据应用开发框架,配有代理工作流表达语言以及代理功能。简单来说,这个框架托管了所有功能,是大型语言模型领域的基础设施。使用DB-
GPT,你可以应用 RAG算法、本地与文件和语言模型(LM)聊天 ,确保数据100%私密。此外,它还包含多代理创建框架及其他多种功能。
这个解决方案的本地化功能允许你与模型和各种插件进行交互,确保数据私密且安全。自上次介绍以来,DB-GPT已经推出了许多新更新,包括DB-GPT
3.0,引入了AI原生数据应用程序和新的Drag and Drop UI,使你可以构建多AI代理框架,并与 数据解释器交互
,创建各种AI应用程序及代理。
多代理协作与应用创建 DB-GPT提供了多代理协作系统和应用创建功能。你可以在主面板中选择预创建的代理,如 Chat Data、Chat
DB、Chat Knowledge和Chat Excel
,设置自定义提示词,连接数据库,上传各种文件类型,创建知识库和集成第三方插件。此外,新引入的Agentic Workflow Expression
Language简化了复杂工作流和多代理框架的开发。
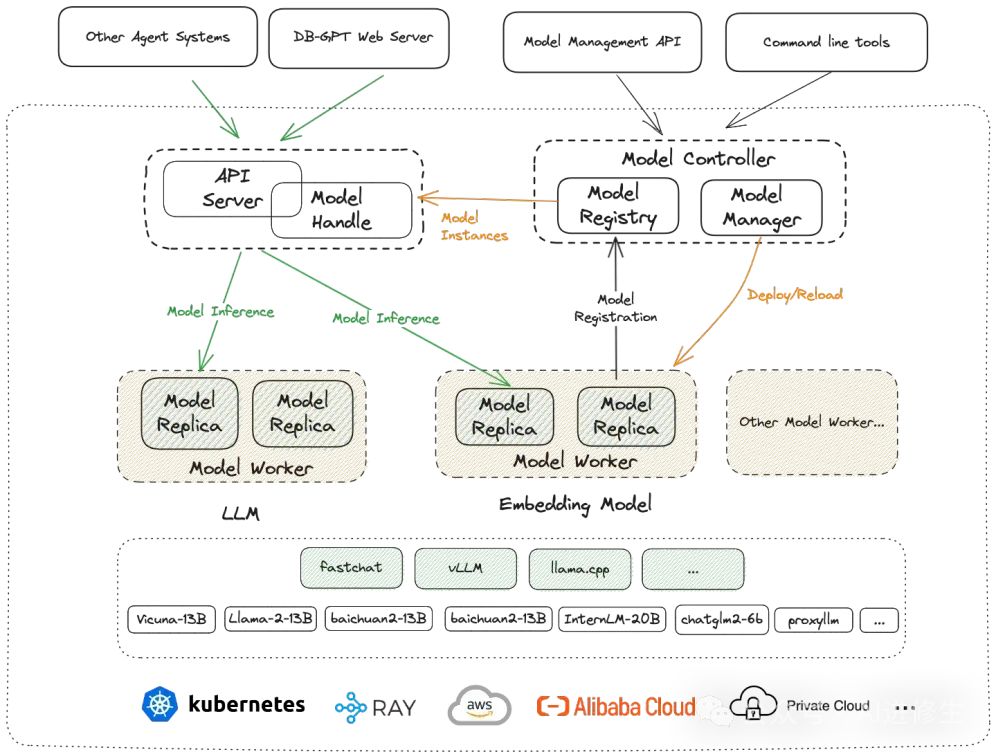
下图是DB-GPT的架构图,整体结构比较简单。 左侧是知识(RAG),右侧是工具(Agents), 中间是多模型管理(SMMF),
同时增加了向量存储这样的大模型记忆体,以及各类数据源,在往上是一层通用的交互层面。
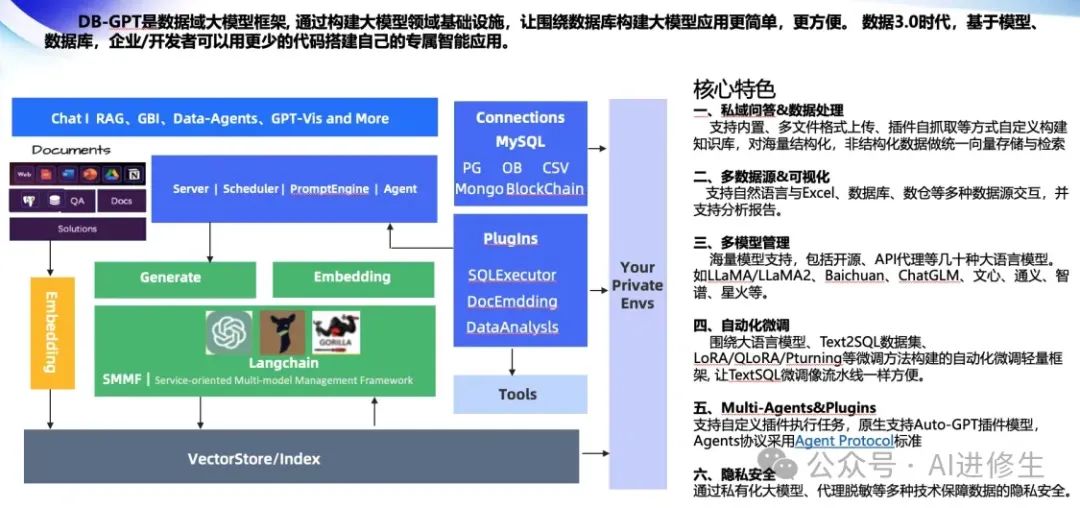
** 关键特性 **
● **私域问答 &数据处理&RAG **
支持内置、多文件格式上传、插件自抓取等方式自定义构建知识库,对海量结构化、非结构化数据做统一向量存储与检索。
● **多数据源 &GBI **
支持自然语言与Excel、数据库、数仓等多种数据源交互,并支持分析报告。
● 多模型管理
海量模型支持,包括开源、API代理等几十种大语言模型,如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通义、智谱、星火等。
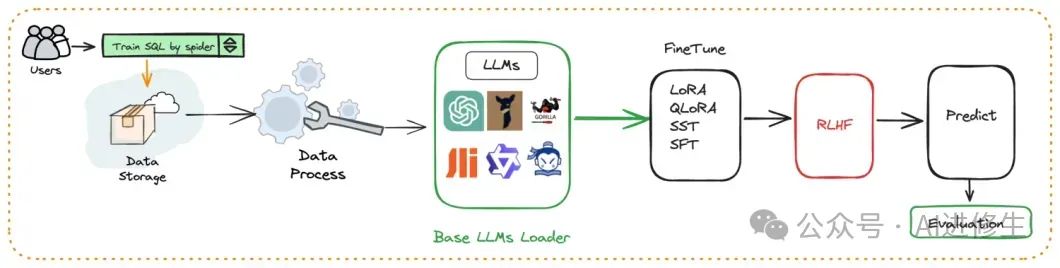
● 自动化微调
围绕大语言模型、Text2SQL数据集、LoRA/QLoRA/Pturning等微调方法构建的自动化微调轻量框架,让TextSQL微调像流水线一样方便。
● **Data-Driven Multi-Agents &Plugins ** 支持自定义插件执行任务,原生支持Auto-
GPT插件模型,Agents协议采用Agent Protocol标准。
● 隐私安全
通过私有化大模型、代理脱敏等多种技术保障数据的隐私安全。
视频教程
多模型支持与管理
海量模型支持,包括开源、API代理等几十种大语言模型。如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通义、智谱等。当前已支持如下模型:
-
• 新增支持模型
-
• 🔥🔥🔥 Qwen2-57B-A14B-Instruct
-
• 🔥🔥🔥 Qwen2-72B-Instruct
-
• 🔥🔥🔥 Qwen2-7B-Instruct
-
• 🔥🔥🔥 Qwen2-1.5B-Instruct
-
• 🔥🔥🔥 Qwen2-0.5B-Instruct
-
• 🔥🔥🔥 glm-4-9b-chat
-
• 🔥🔥🔥 Phi-3
-
• 🔥🔥🔥 Yi-1.5-34B-Chat
-
• 🔥🔥🔥 Yi-1.5-9B-Chat
-
• 🔥🔥🔥 Yi-1.5-6B-Chat
-
• 🔥🔥🔥 Qwen1.5-110B-Chat
-
• 🔥🔥🔥 Qwen1.5-MoE-A2.7B-Chat
-
• 🔥🔥🔥 Meta-Llama-3-70B-Instruct
-
• 🔥🔥🔥 Meta-Llama-3-8B-Instruct
-
• 🔥🔥🔥 CodeQwen1.5-7B-Chat
-
• 🔥🔥🔥 Qwen1.5-32B-Chat
-
• 🔥🔥🔥 Starling-LM-7B-beta
-
• 🔥🔥🔥 gemma-7b-it
-
• 🔥🔥🔥 gemma-2b-it
-
• 🔥🔥🔥 SOLAR-10.7B
-
• 🔥🔥🔥 Mixtral-8x7B
-
• 🔥🔥🔥 Qwen-72B-Chat
-
• 🔥🔥🔥 Yi-34B-Chat
-
-
• 更多开源模型
-
• 支持在线代理模型
-
• DeepSeek.deepseek-chat
-
• Ollama.API
-
• 月之暗面.Moonshot
-
• 零一万物.Yi
-
• OpenAI·ChatGPT
-
• 百川·Baichuan
-
• 阿里·通义
-
• 百度·文心
-
• 智谱·ChatGLM
-
• 讯飞·星火
-
• Google·Bard
-
• Google·Gemini
-
拖放式UI构建
** 看看官方是怎么说的(向上滑动) **

入门教程也实现众多功能
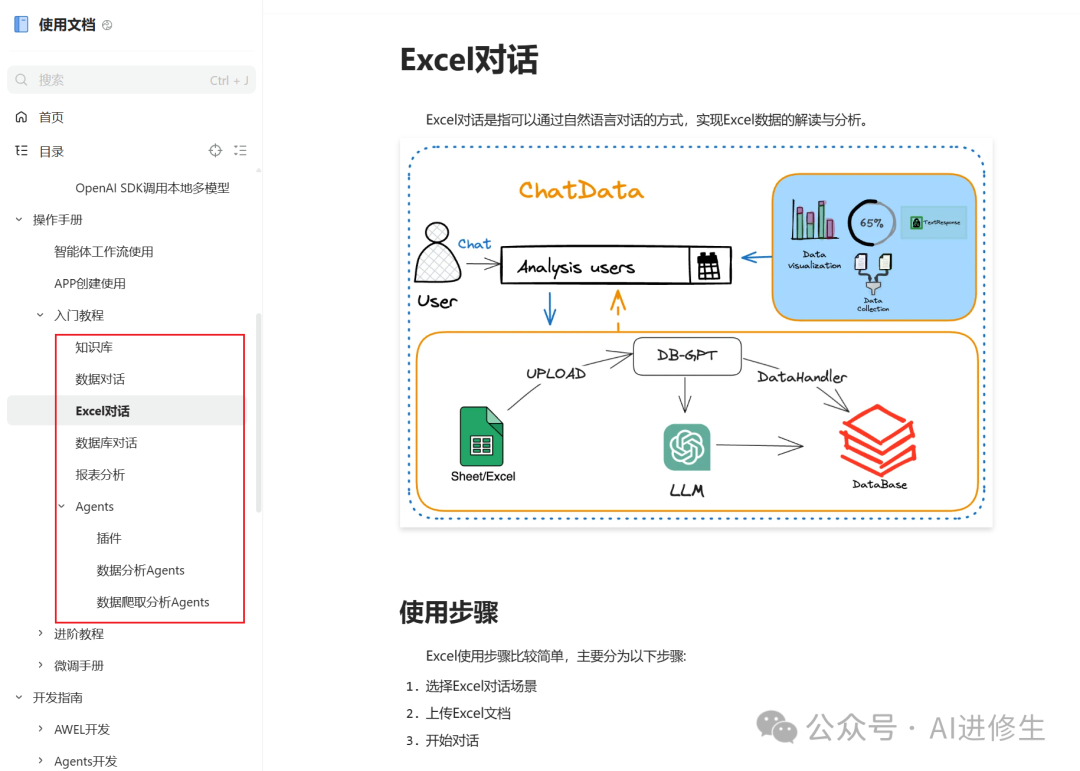
除此以外高阶教程包含可控细颗粒度操作
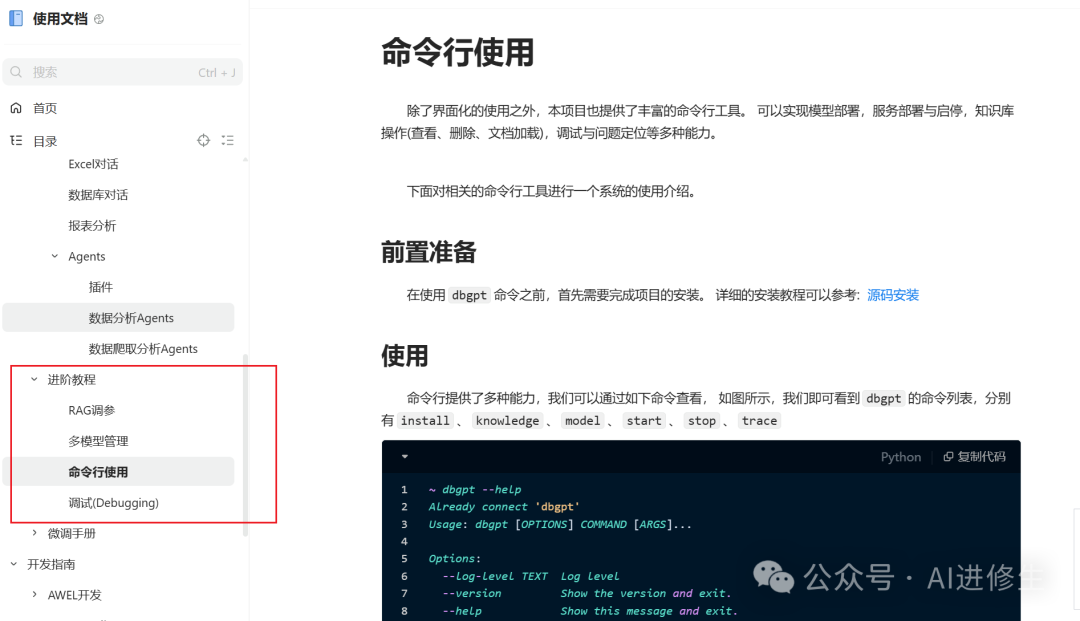
甚至还有微调教程
部署方式众多
多模型服务的调用兼容了OpenAI接口,可以通过OpenAI SDK直接调用DB-GPT中部署好的模型。
DB-
GPT支持多种开源以及闭源模型的安装使用,不同模型对环境与资源的需求也不相同。如果需要进行本地化模型部署,则需要GPU资源进行部署。通过API代理模型所需要的资源会相对较少,可在CPU机器上进行部署启动。
https://www.yuque.com/eosphoros/dbgpt-docs/qno7x8hmgyulbg80
智能体编排语言(AWEL)
** 看看官方是怎么说的(向上滑动) **

使用企业

视频教程 https://www.bilibili.com/video/BV1JW421N7T5?share_source=copy_web
知音难求,自我修炼亦艰
抓住前沿技术的机遇,与我们一起成为创新的超级个体
(把握AIGC时代的个人力量)
**
**
** 点这里 👇 关注我,记得标星哦~ **
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~

预览时标签不可点
微信扫一扫
关注该公众号
轻触阅读原文

AI进修生
收藏



















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











