







1. 背景介绍
目前大模型的时代已经如火如荼了, 模型越做越大,但是目前主流的训练推理卡确实一直刀来刀去没什么长进, 说的就是你NVIDIA。
由于众所周知的原因, 老黄的卡一直显存都不大, 贴一下主流显存,在消费级,也就是买的最多,“普通人”最能affordable的price, 3090和4090都是24G, 跑一个大一点的LLM推理都得考虑下要做几Bit量化,而稍微大点的A100, H100, H200呢, 也没大多少,40G, 80G, .... 。
在模型推理和训练的两个过程中, 显存的需求是不一样的, 其中在训练的过程要把梯度, 优化器参数这些也放到显存上, 所需要的显存也比推理时大一些了。
但是现在动辄几十B,几百B的大模型,光想用单卡训练, 甚至于推理都不太可能了, 当然也有Lora, 量化这样的策略, 不过都是以损失性能作为compromise的。那么避无可避的, 肯定会设置并行这个问题, 或许很多场景你都听说过Tensor parallel, pipeline parallel这些词, 但是很多博客的质量都难以恭维, 很多都模棱两可。这里我尽量说出自己的理解。
为了对说的东西有一个basic understanding, 简单说一下他们的特点, 在后面的section中在具体介绍:
-
• Pipeline parallel(PP): 将一个模型分成不同layer, 不同的layer在不同的gpu上
-
• Data parallel(DP): 并行处理dataloader里面的batch, 分为Distributed Data parallel(DDP), DP, ZeRO(Zero redundancy Optimizer)
-
• Tensor Parallel(TP): 把一个矩阵乘法分块计算
在下面的文章里面, 默认情况我都用简写代表了, 不做special case说明的情况下。
2. PP
这里还是以一个最简单的case分析, 假设一个GPT模型(这里指的是GP2里面实现的GPT模型), 假设其存在8层transformer layer,我们要用PP把其运行在(可能运行这个词不太appropriate)两个GPU上(后文中, GPU默认id从0开始, 也就是GPU0和GPU1)。
根据最基础的PP, 我们直接把前四个layer放在GPU0上,后面四个放在GPU1上:
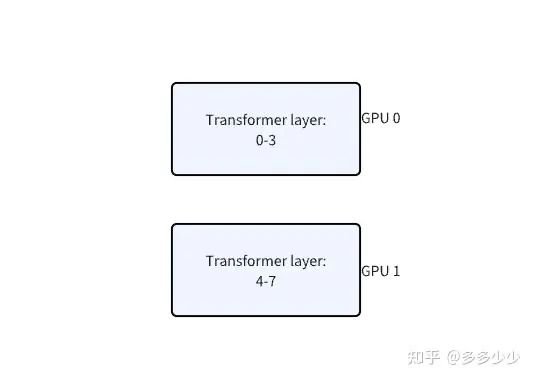
这里以一个batch来分析,那么在一次forward的情况下,一个batch首先通过0-3层,进行正常的forward计算,这个和在单卡上一模一样, 此时GPU1是idle状态, 然后输出结果给GPU1上的4-7进行计算, 此时GPU0 idle, 最后算完了后返回输出值到layer0计算loss或者传递label到layer7计算loss。不难看出,除了能够放下更大的模型以外,这种被称为Naive Model Parallelism (MP)的方法基本和在单卡上跑性能没有区别, 甚至性能会因为data在不同gpu上的传递导致overhead。
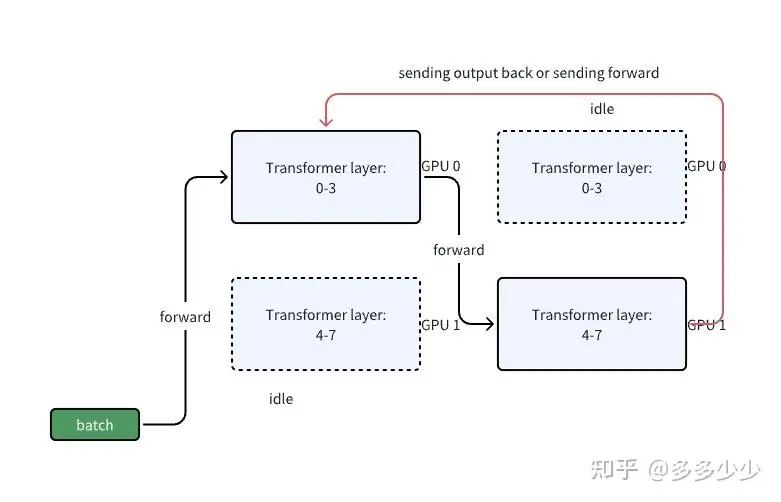
那么此时就有一个问题了,在使用MP的时候, 其中一张卡计算的时候,其他卡都是idle状态, 我们怎么减少idle呢, 对了,在计组里面学过的, 流水线。在PP里面, 一种优化的方式就是把一个batch划分成更小的batch, 这里叫做micro-batch, 而划分多少个,这个参数叫做PP里面的chunks。
参考GPipe paper[6]的实现, 和下图所示, 这里有四个GPU, 模型被成拆成了四块,每个GPU一块, 其中F代表forward,B代表backward。GPU0 在处理第 0、1、2 和 3 个块(F0,0, F0,1, F0,2, F0,3)时执行相同的前向路径,然后等待其他 GPU 完成它们的工作。只有当其他 GPU 开始完成它们的工作时,GPU0 才会继续进行反向传播路径,顺序为块 3、2、1 和 0(B0,3, B0,2, B0,1, B0,0)。
整个过程中有段空闲时间, 就是F3和B3,这是因为最后一个forward必须等待backward完成才能继续进行。
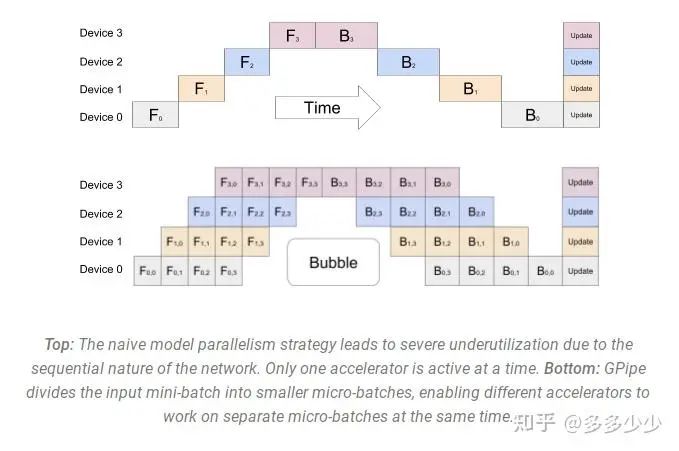
通过这样的优化, 可以减少idle时间(bubble),这就是PP的主要思路, 进一步可以查看deepseed里面实现:Pipeline Parallelism - DeepSpeed[7]
3. DP
DP主要分为DDP, DP还有ZeRO DP, DP就是主要和数据相关了。DP最初需要解决的问题是, 对于一个dataloader, 我们一般在一张卡训练一个模型, 这是很universal的case,但是如果我们一个模型在一张卡上可以训练,这完全OK,但是如果我们机器上有多张卡,我们希望以不同的batch同时并行迭代这个dataloader然后同时训练模型, 当训练某个epoch完成后再同步loss更新模型, 这就是DP需要解决的问题, 其中这三种实现主要的不同就是数据和数据和模型的复制方式。
还是用最简单的情况来说明, 一个模型在一张卡上可以训练, 假设我们现在有四张卡,其中DDP是在开始, 我们把模型复制四份, 每个卡上放一份, 然后以不同的遍历顺序并行获取Dataloader的batch(其实也可以是获取一个大的batch然后拆分成mini batch分配),当所有卡的模型copy都完成自己对应的minibatch的forward的时候, 我们把每个卡的loss平均求和(这里也可以用accumulate grad进行大batch训练),使用average grad进行反向传播。然后更新模型, 在这个DPP里面, 每个模型的对于其mini batch的数据的consume都是并行的。
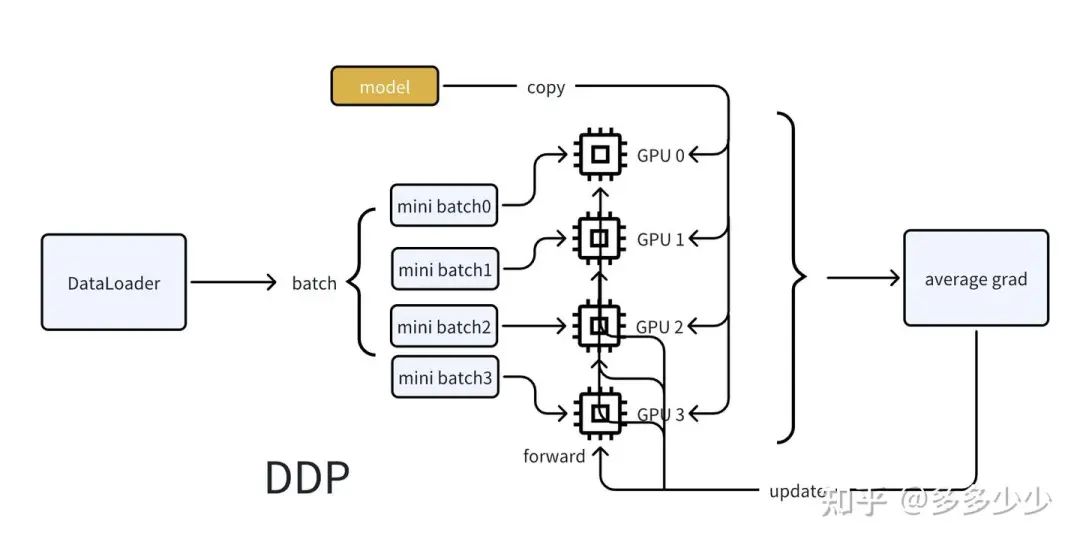
还是使用上面的例子, 对于DP呢, 首先是GPU0 获取整个batch的数据然后把mini batch 分发到其他的GPU上, 然后当前的模型从GPU0上复制到其他的卡上, 在forward后,其他卡的输出结果都reduce到GPU0上计算loss, 计算完loss后再分发到其他GPU上分别计算梯度, 计算完梯度后再reduce到GPU0上进行反向传播,相比DDP, DP在整个计算过程中GPU0和其他卡的通信较多, 整体上慢于DDP。对比上面的DPP的图不难想象DP的过程,这里我就不画了。
而对于ZeRO DP呢, 在上面的情况里面, 我们假设一张卡可以训练一个模型,使用DP or DDP都是希望并行consume数据集做到多卡并行加速, 而使用ZeRO DP的case来说, 更希望解决的问题还是比如说一个卡放不下整个模型, 而是只能放一个模型的一部分情况, 按照HF所说的, 就是每个卡只是存储模型参数, 权重,以及优化器的一部分。
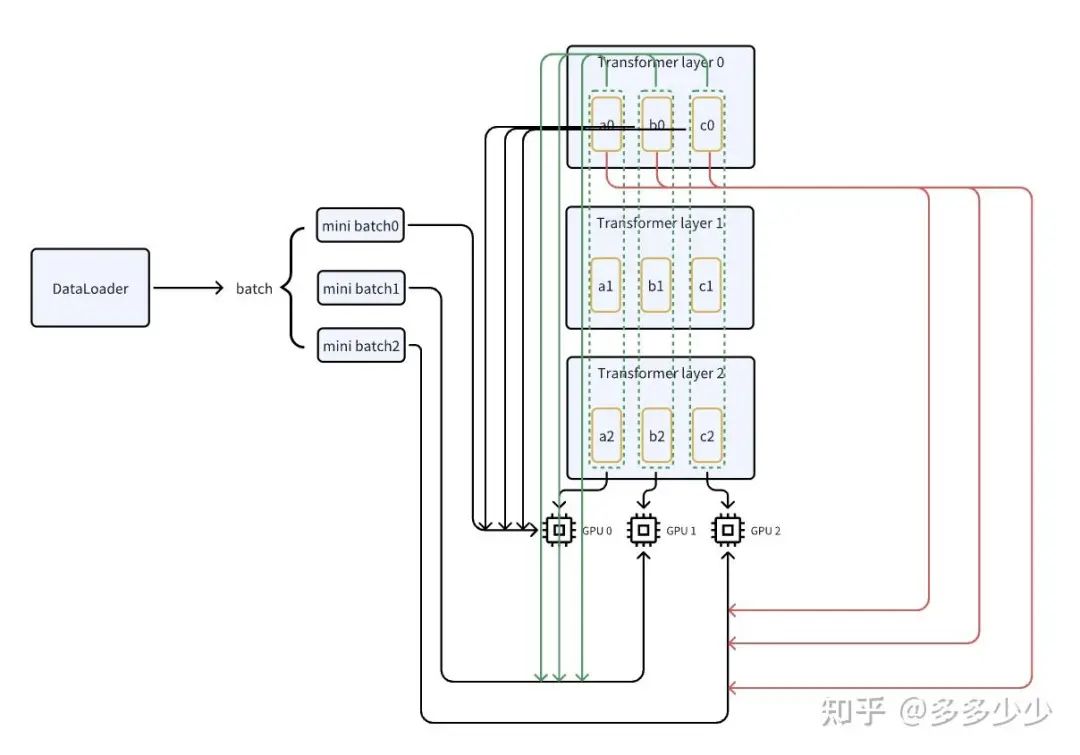
还是以模型为例, 假设有一个三层transformer layer的一个模型, 其包含三组参数a, b, c, 我们把三层中的a参数(a0, a1, a2)放在GPU0 上, b放在GPU1上以此类推。同样的,这里输入采用前面的DPP来说明, 并行consume一个batch里面多个mini batch, 以mini batch0为例,当其开始forward的时候, 也就是来到layer0的时候, 在GPU0上进行处理,但是GPU0上只有a0, 还需要b0和c0
此时GPU0从GPU1和GPU2上获取b0和c0然后进行计算, 对于mini batch1就是在GPU1上获取来自GPU0的a0和GPU2的c0, 对于mini batch2也是一样的,这几个minibatch也都是并行的
当完成第1层的计算后,来到第二层操作依旧类似, 通过把模型同一层的参数存储到不同卡上,然后在forward计算的时候从其他的GPU获取其他的参数,这就是ZeRO的一种DP方式,其实有点类似TP的一种slice方式。
4. TP
好的, 终于写到Tensor Parallel(TF), 我想这不会是博文的终结,抑或是LLM 相关的终结, 最近有点忙于工作的事情了。
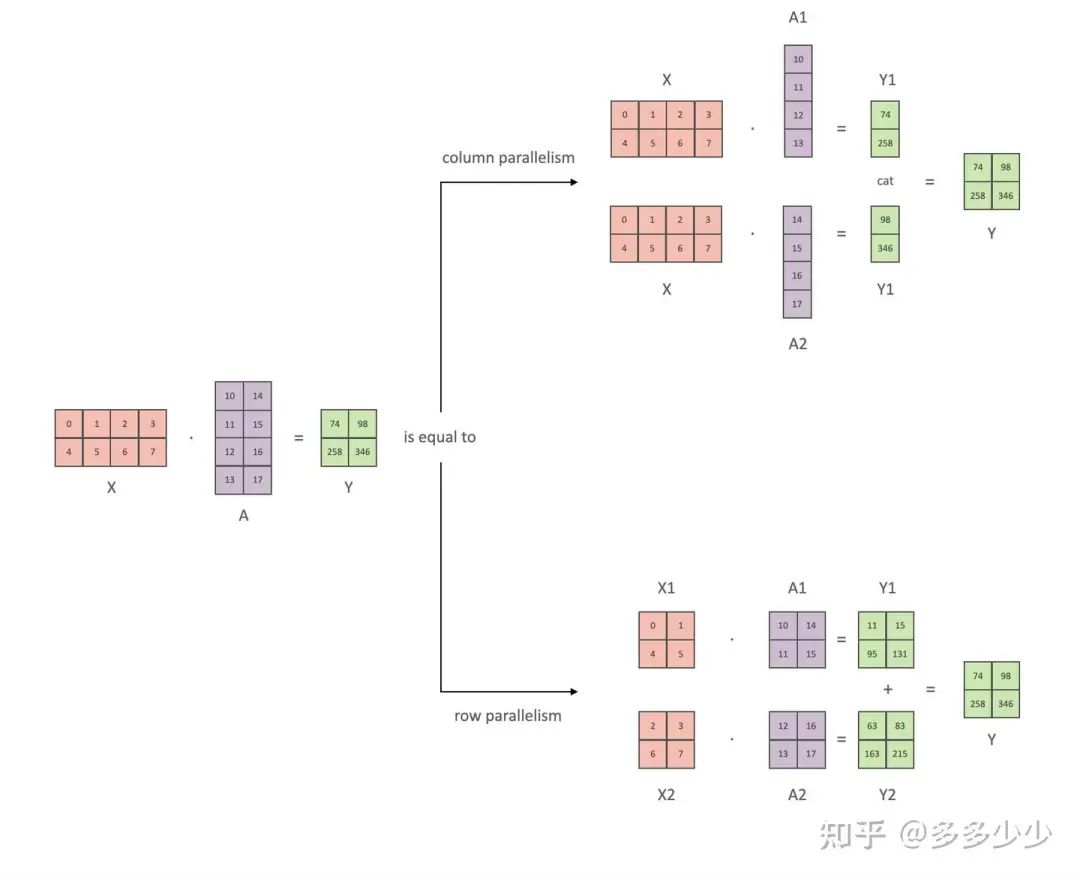
TP的思路很简单也很trivial, 是基于朴素的线性代数的优化, 也就是线性代数里面的分块矩阵, 如果学过线性代数应该很了解这个部分, 遗忘了也没关系, 下图是我从NV的megatron摘的一个图片, 按照下面的所示,TF有两种一种是Column paralle, 另一种是Row parallel, 两者不同就是切分的方式, 第一种按照column进行切分,分别计算被column切分的两个分块矩阵的乘法, 然后把结果concatenate起来, 第二种就是按row切分, 里面是利用了分块矩阵的一个公式, 具体分块矩阵的计算可以参考博文4.3 矩阵分块运算|《线性代数》 - 知乎[8]。在目前大火的开源模型llama3以及deepseek3中都有使用这两种TP, 具体可以查看对应github的model.py。
已经理解他的原理,他的用途也就很明显了, 在transformer的计算过程中,主要有Q,K,V的投影以及Attention计算的两个矩阵乘法, 我们可以把其中的输入的tensor X以及权重都采用TF的方法来存储, 依靠和上面类似的gather以及reduce的方法在不同的GPU之间传递所需要的数据, 最后进行concatenate或者是相加得到最后的结果,这样的话, 可以减少单卡的负载了。
5. 组合
其实在实际使用的过程中,TP, PP, DP 都不是单一使用的, 是可以两两或者三者一起组合的。下面以两种case为例分析:
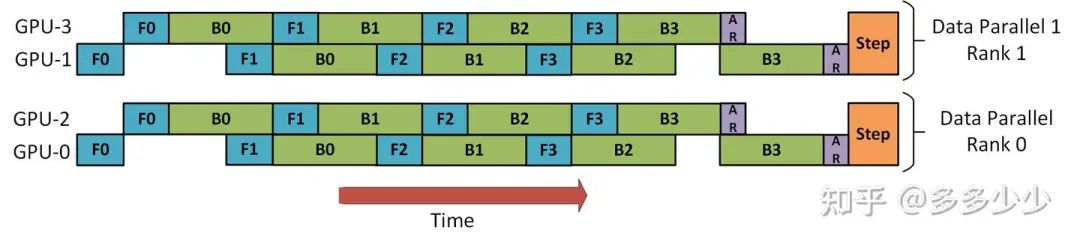
1.DP + PP
在进行分布式推理或者分布式训练的时候,对于不同batch数据,比如说两个, 这里叫做DP rank0 以及DP rank1的数据, 然后其中模型可以放在两个卡上(采用PP), 一共四张卡, 放置两个模型。如下图所示. 两个并行的DP可以同时forward通过PP在两张卡上的模型。
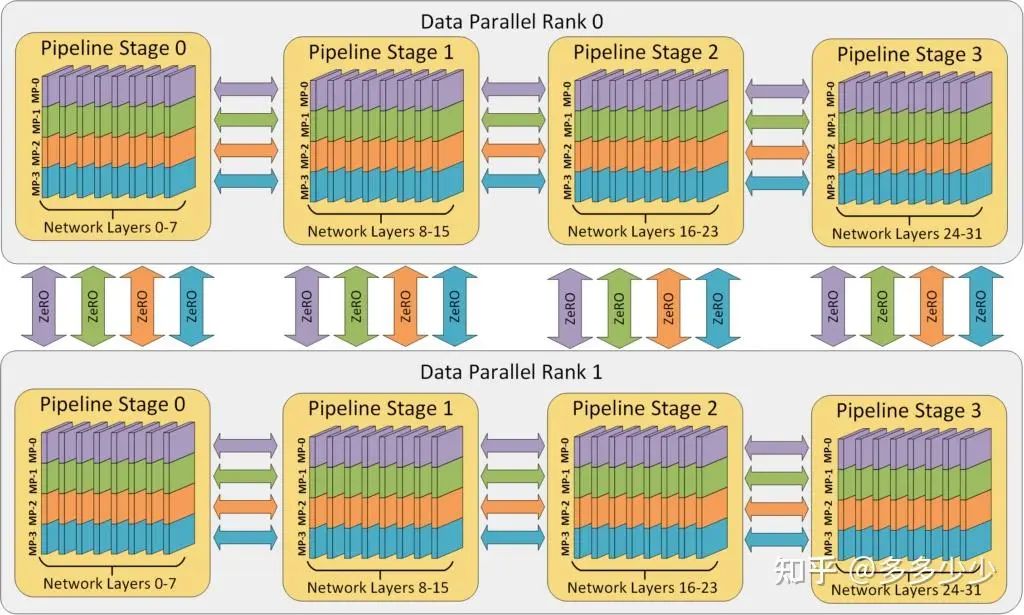
2. DP + PP + TP
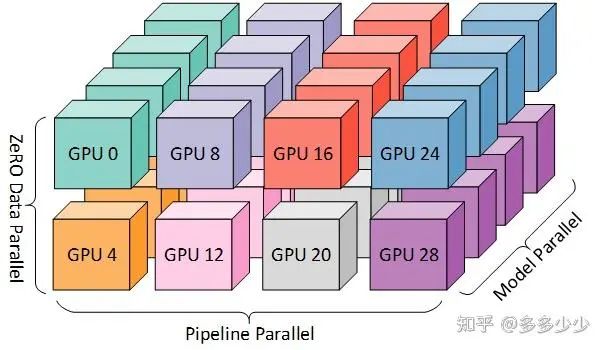
当我们把这三者组合在一起就是一个3D的parallel了, 所以MS也把其称为3D parallel, 下图(图来自MS的DS)中有32个GPU, 8个node(也就是八个节点服务, 每个节点上插4张卡), 其中把一个模型通过PP分成了四个部分, 每个部分的权重通过前面介绍的ZeRO存储在不同的卡上。
至此应该算是介绍完了, 如果后面有什么想写的内容再写吧, 比如说ZeRO的不同stage, 有什么区别以及具体是什么样的(面试常考题),以及如何hands on的实现这些并行方法
引用链接
[1]Efficient Training on Multiple GPUs:https://huggingface.co/docs/transformers/main/en/perf_train_gpu_many#tensor-parallelism
[2]Zero Redundancy Optimizer - DeepSpeed:https://www.deepspeed.ai/tutorials/zero/
[3]Tensor Parallelism:https://huggingface.co/docs/text-generation-inference/conceptual/tensor_parallelism
[4]Model Memory Utility - a Hugging Face Space by hf-accelerate:https://huggingface.co/spaces/hf-accelerate/model-memory-usage
[5]DataParallel — PyTorch 2.5 documentation:https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html
[6]GPipe paper:https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html
[7]Pipeline Parallelism - DeepSpeed:https://www.deepspeed.ai/tutorials/pipeline/
[8]4.3 矩阵分块运算|《线性代数》 - 知乎:https://zhuanlan.zhihu.com/p/422710424


















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









