










上海AI Lab联合商汤科技以及国内多所顶尖高校,最近发布了一个新的开源VLM——InternVL3。
- 它的核心创新在于采用了「原生多模态预训练」(
native multimodal pre-training) 范式。 - 不同于以往先训练好一个纯文本大模型,再想办法让它能处理图像等多模态信息的「后期改造」(
post-hoc) 方式,InternVL3 在预训练阶段就同时学习处理文本和多模态(如图像、视频)数据。 - 这种统一的训练方法能更有效地整合不同模态的信息,解决了传统方法中常见的对齐难题和流程复杂性。
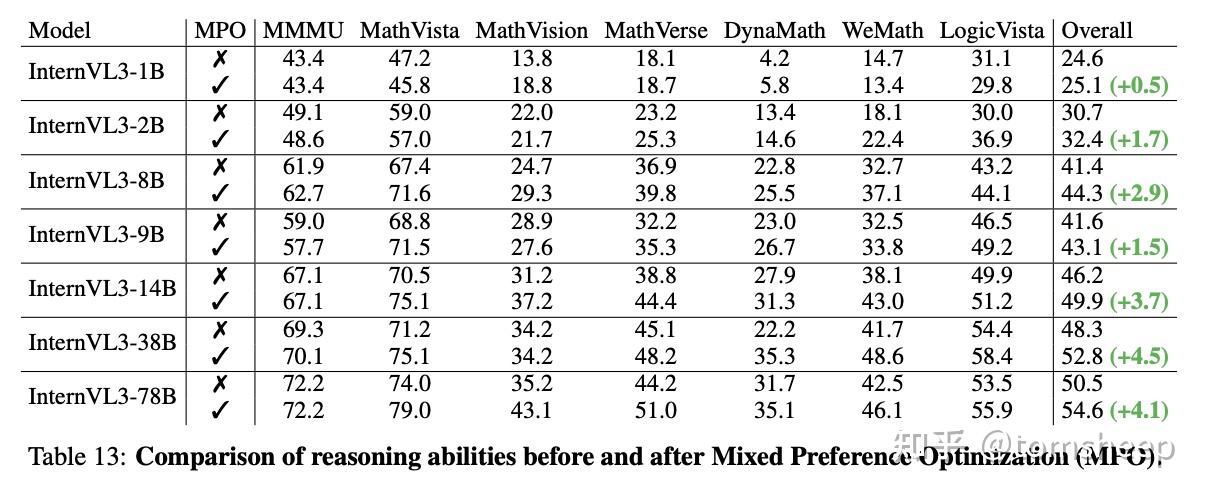
- InternVL3 还结合了**可变视觉位置编码 (V2PE)** 来支持更长的多模态上下文,运用了监督微调 (SFT) 和混合偏好优化 (MPO) 等先进的后训练技术,并采用了测试时扩展策略和优化的训练架构。
- 实验证明,InternVL3 在众多多模态任务上表现优异,其中 InternVL3-78B 在 MMMU 基准测试上达到了 72.2 分,成为开源模型的新标杆,并能与顶尖的闭源模型(如 ChatGPT-4o, Claude 3.5 Sonnet, Gemini 2.5 Pro)相媲美,同时保持了强大的纯文本处理能力。
论文:https://arxiv.org/abs/2504.10479
一、 传统 MLLM 方法的「后期改造」之痛
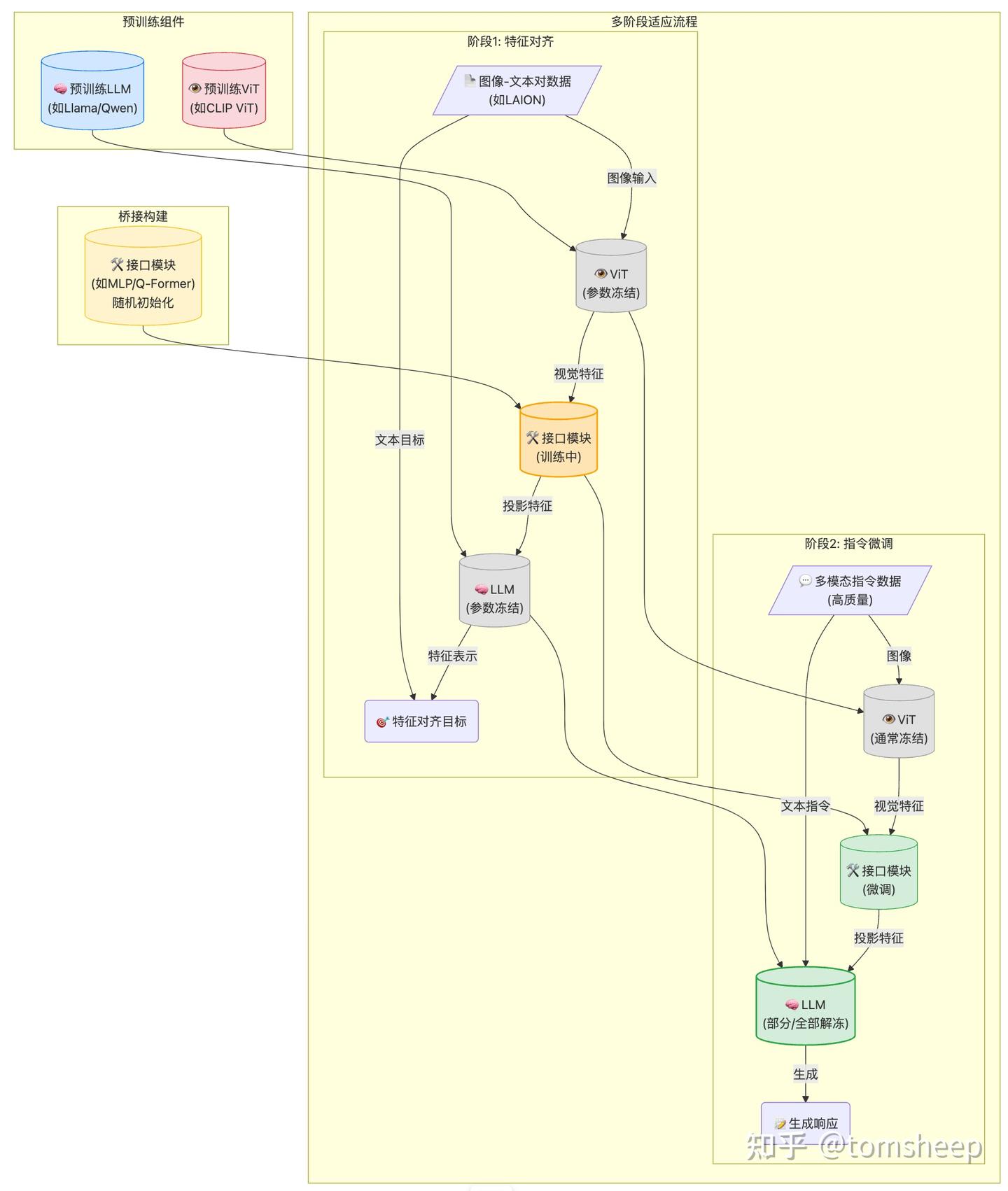
目前主流的MLLM (比如LLaVA、Qwen-VL等)都采用了「后期改造」 (Post-hoc Adaptation)的训练范式。大概的套路是:
-
强大的基石:首先,需要一个性能卓越的纯文本大语言模型 (LLM),比如 Llama、Qwen、GPT-4 等。这是模型理解和生成能力的基础。
-
敏锐的眼睛:其次,需要一个强大的视觉编码器 (Vision Encoder),通常是 Vision Transformer (ViT) 或其变种,负责从图像或视频中提取视觉特征。这些 ViT 通常也在海量图像数据上预训练过(例如 CLIP)。
-
沟通的桥梁:然后,需要一个接口模块 (Interface Module),通常是一个轻量级的网络(如多层感知机 MLP 或 Q-Former),它的作用是将视觉编码器输出的「视觉语言」翻译成文本大模型能够理解的「嵌入表示」。
-
多阶段的磨合:最后,通过多个训练阶段将这三者「捏合」在一起:
- 阶段一:特征对齐预训练:使用大量的图像-文本对数据 (比如 LAION 数据集),主要训练接口模块,让它学会如何将视觉特征映射到 LLM 的表示空间。这个阶段通常会冻结 (freeze) ViT 和 LLM 的参数,以节省计算资源并保持它们原有的能力。
- 阶段二:视觉指令微调 (Visual Instruction Tuning) :使用更高质量、更符合人类交互习惯的多模态指令数据(例如,「图片里有什么?」-「一只猫在睡觉」;「根据图片写一个故事」等),对模型进行微调,使其能够理解并遵循指令进行多模态对话和推理。这个阶段可能会解冻并微调 LLM 的部分或全部参数。
这种方法虽然在实践中取得了巨大成功,但也带来了不少「先天不足」:
- 对齐难题 (Alignment Challenges) :视觉和语言是两种截然不同的模态。ViT 和 LLM 在预训练时「各学各的」,后期仅靠一个轻量级接口和有限的对齐数据,很难让它们真正「心意相通」。如何让 LLM 深刻理解视觉细节、空间关系、隐含意义,而不是仅仅处理表层信息,是一个巨大的挑战。
- 流程复杂,调优困难 (Sophisticated & Hard to Tune) :多阶段训练引入了大量的超参数和设计选择(冻结哪些层?何时解冻?用什么数据对齐?),整个流程像一个精密的仪器,牵一发而动全身,调试和优化非常困难。
- 能力权衡与损失 (Compromised Capabilities) :为了在多模态任务上表现良好,有时不得不牺牲一部分 LLM 原有的语言能力。比如,在指令微调阶段过度拟合多模态数据,可能导致模型在纯文本任务上的性能下降。或者,为了保持语言能力而过度冻结 LLM,又会限制其在多模态任务上的学习潜力。这是一个两难的权衡。
- 资源消耗巨大 (Resource-Intensive) :每个阶段都需要大量的计算资源和精心策划的数据集。特别是为了弥补模态鸿沟,往往需要收集和标注针对性的数据(如 OCR 数据、图表数据、细粒度描述数据等),成本高昂。
有没有一种更自然、更统一的方式来培养 MLLM 呢?
二、 InternVL3 :原生多模态预训练
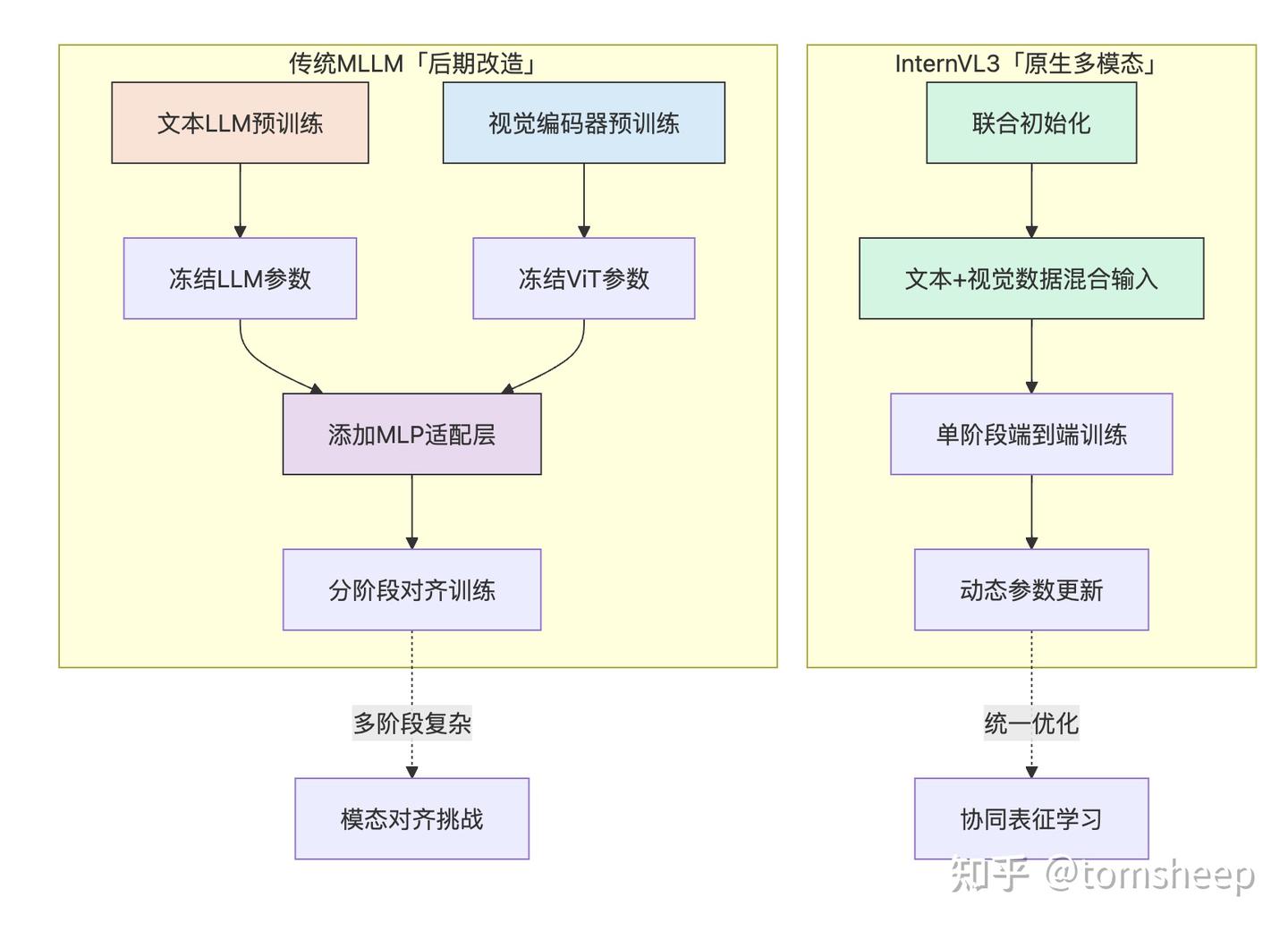
InternVL3 的想法其实也很直白,架构其实仍然是 ViT-MLP-LLM这一套,只是选用了 原生多模态预训练 (Native Multimodal Pre-training):
- 统一的训练阶段 (Unified Pre-training Stage) :取消了传统方法中独立的特征对齐预训练阶段。在一个统一的、大规模的预训练阶段中,模型同时接触纯文本语料库和多模态数据。
- 共同优化所有参数 (Joint Parameter Optimization) :在这个统一的预训练阶段,模型的所有核心组件——视觉编码器 (ViT)、接口模块 (MLP) 和语言模型 (LLM)——的参数都同时参与优化。没有谁是「旁观者」或「被冻结者」。大家一起学习,一起调整。
- 以文本为中心的预测目标 (Text-centric Predictive Objective) :尽管输入包含了视觉信息,但训练的目标仍然是经典的自回归预测 (Autoregressive Prediction),即预测序列中的下一个 token。但关键在于,损失函数 (L\mathcal{L}) 只计算文本 token 的预测损失。
用公式表达就是:对于一个包含文本和视觉 token 的序列 x=(x1,x2,…,xL)\mathbf{x} = (x_1, x_2, \ldots, x_L),其损失为:
Ltext−only(θ)=−∑xi∈Texti=2Lwi⋅logpθ(xi∣x1,…,xi−1){\mathcal{L}}_{\mathrm{text-only}}(\theta) = -\sum_{\stackrel{i=2}{x_{i}\in\mathrm{Text}}}^{L} w_{i} \cdot \log p_{\theta}(x_{i} \mid x_1, \ldots, x_{i-1}) \\
其中,xi∈Textx_i \in \mathrm{Text} 表示只对序列中是文本 token 的 xix_i 计算损失,pθ(xi∣…)p_{\theta}(x_i \mid \dots) 是模型预测第 ii 个 token 的概率,wiw_i 是该 token 的损失权重(InternVL3 采用了 1l0.5\frac{1}{l^{0.5}} 的平方平均权重,l 为计算损失的文本 token 总数)。
对比一下「原生训练」和「后期改造」:
这样有什么好处呢?
- 深度协同,消除鸿沟 :视觉和语言表示从一开始就在统一的模型内部共同学习、相互塑造。这有助于模型学习到更深层次、更本质的跨模态关联,而不是后期「强行」对齐。模态之间的「鸿沟」在学习过程中就被自然地填平了。
- 简化流程,提升效率 :将多个分离的训练阶段整合为一个统一的预训练阶段,大大简化了 MLLM 的构建流程,减少了中间环节的调优复杂性。虽然这个统一阶段可能很长,但整体上可能更高效。
- 释放潜力,减少妥协 :所有参数共同优化,使得视觉和语言能力可以同步发展,减少了因冻结参数而导致的能力瓶颈,模型可以更充分地学习如何结合多模态信息。
- 更强的泛化能力 :在混合数据上进行联合训练,可能促使模型学习到更通用、更鲁棒的表示,从而在未见过的任务或数据上表现更好。
三、 InternVL3 的核心技术
3.1 灵活处理长序列:可变视觉位置编码 (V2PE)
当 MLLM 需要处理包含大量图像(比如一个相册)或高分辨率图像(拆分成很多小块)或长视频时,输入的视觉 token 数量会急剧增加。传统的 Transformer 位置编码是给每个 token (无论文本还是视觉) 分配一个递增的整数索引 (0, 1, 2, 3…)。视觉 token 一多,序列长度可能轻松超过 LLM 的处理上限,导致无法处理或信息丢失。
InternVL3 的解决方案是:给视觉 token 分配更小的位置增量。称之为V2PE (Variable Visual Position Encoding)。
文本 token 的位置索引仍然是 pi=pi−1+1p_i = p_{i-1} + 1。但视觉 token 的位置索引则变为 pi=pi−1+δp_i = p_{i-1} + \delta,其中 δ\delta 是一个小于 1 的分数 (例如 1/4, 1/16, …, 1/256):
pi=pi−1+{1,if xi is a textual token,δ,if xi is a visual token,p_{i}=p_{i-1}+{\left\{\begin{array}{l l}{1,}&{{\mathrm{if~}}x_{i}{\mathrm{~is~a~textual~token}},}\\ {\delta,}&{{\mathrm{if~}}x_{i}{\mathrm{~is~a~visual~token}},}\end{array}\right.} \\
关键点在于,对于同一张图像(或同一个视频片段)内的所有视觉 token,δ\delta 的值是相同的,这样保证了图像内部的相对空间关系得以保留。
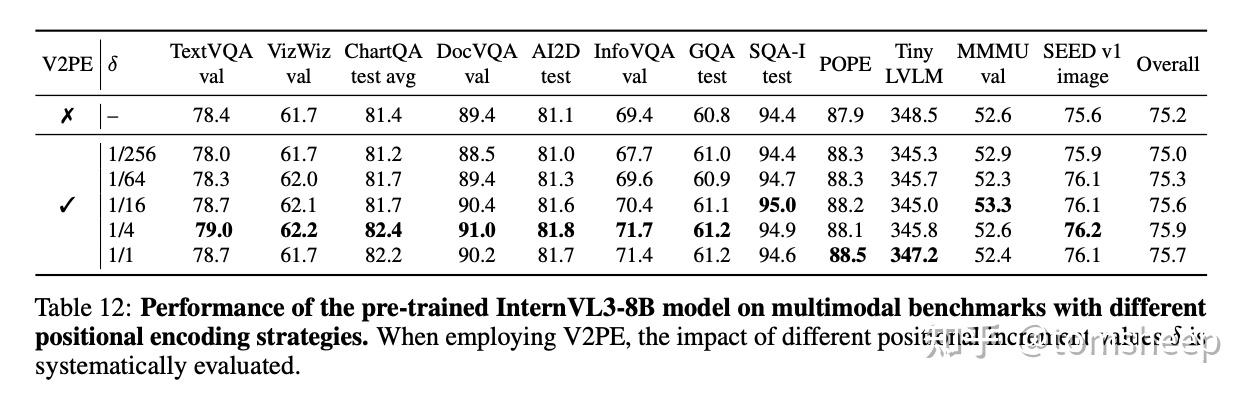
在训练时,δ\delta 的值从一个预定义的集合(如 {1,1/2,1/4,…,1/256}\{1, 1/2, 1/4, \dots, 1/256\})中随机为每张图片选择。这使得模型学会适应不同「压缩程度」的位置编码。
而在推理时,可以根据输入序列的实际长度灵活地选择一个合适的 δ\delta 值,以在性能和不超过上下文窗口之间取得平衡。
有趣的是,这种设计还有意外收获:论文的消融实验表明,V2PE 不仅在处理长序列时有用,即使在处理普通长度序列的标准基准测试上,使用较小的 δ\delta (如 1/4, 1/16) 相比于 δ=1\delta=1(即传统编码)也能带来性能提升。这似乎暗示,V2PE 可能不仅仅是解决了长度问题,或许还对模型学习视觉-语言对齐有更深层次的好处,值得进一步研究。
3.2 数据策略
InternVL3 采用了纯文本数据和多模态数据的混合喂养。
- 多模态数据 (约 1500 亿 tokens):不仅包含了 InternVL 2.5 使用的覆盖广泛领域(图像描述、问答、数学、图表、OCR、文档、对话、医疗等)的数据,还新增了更多真实世界应用场景的数据,如图形用户界面 (GUI) 操作、工具使用、3D 场景理解、视频理解等。这大大扩展了模型的应用范围。
- 纯文本数据 (约 500 亿 tokens):主要基于 InternLM 2.5 的预训练数据,并加入了其他开源文本数据集,特别强化了知识密集型任务、数学和推理方面的语料。这是为了确保模型在进行多模态学习的同时,保持甚至增强其核心的语言理解和生成能力。
通过实验确定了 语言数据 : 多模态数据 ≈ 1 : 3 的比例效果最佳。这个比例是在总训练量约 2000 亿 (200B) tokens 的预算下找到的平衡点。太少的语言数据可能削弱基础能力,太多的语言数据则可能冲淡多模态学习的效果。
除了数量和比例,InternVL3 团队也非常注重数据的质量。在后续的 SFT 和 MPO 阶段,都使用了更高质量、更多样化的数据集。
3.3 后训练策略 (SFT & MPO)
原生多模态预训练打下了一个坚实的基础,但要让模型成为能理解复杂指令、进行流畅对话、做出可靠推理的「全能选手」,还需要进一步的后训练 (Post-Training)。InternVL3 采用了两阶段策略:
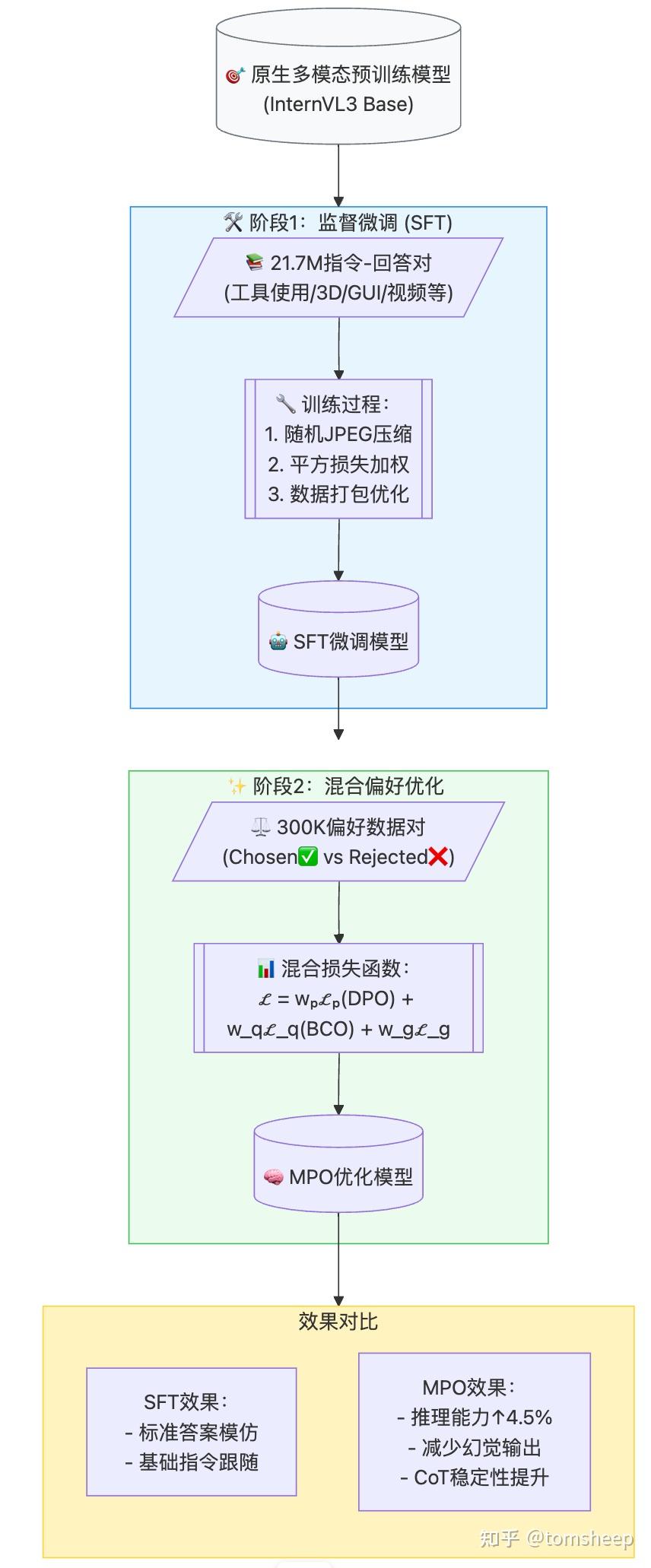
阶段一:监督微调 (SFT)
使用大量高质量的「指令-回答」数据对进行训练,模型学习模仿这些「标准答案」。 沿用了 InternVL 2.5 的一些有效技术(如随机 JPEG 压缩增加鲁棒性、平方损失加权、多模态数据打包提高效率)。
关键在于数据升级:SFT 数据集从 16.3M 样本扩展到 21.7M 样本,并且显著增加了新领域的数据,如工具使用、3D 场景理解、GUI 操作、长上下文任务、视频理解、科学图表、创意写作和多模态推理。这使得模型的能力更加全面。
阶段二:混合偏好优化 (MPO)
如果说 SFT 是教模型「模仿」标准答案,那么 MPO 就是教模型「分辨好坏」并朝着「更好」的方向优化,尤其是在需要复杂推理和判断的场景下,MPO 的作用更加突出。
SFT 时模型是基于「标准答案」预测下一个词,而推理时模型是基于「自己之前生成的词」来预测。这种差异被称作训练与推理的偏差 (Train-Test Discrepancy),在高难度的、需要一步步推理的任务(如数学题、复杂逻辑)中尤其明显,可能导致模型「一步错、步步错」,即链式思考 (CoT) 能力下降。MPO 的目标是让模型的输出更符合人类的偏好,提升推理的可靠性。
MPO 不仅仅依赖「标准答案」,还利用了「偏好数据」,即告诉模型对于同一个问题,哪个回答更好 (chosen),哪个回答更差 (rejected)。它结合了多种损失函数:
- 偏好损失 Lp\mathcal{L}_p (Preference Loss) :使用类似 DPO 的损失,让模型学习最大化「好答案」的概率,同时最小化「坏答案」的概率。
- 质量损失 Lq\mathcal{L}_q (Quality Loss) :使用类似 BCO 的损失,让模型学习判断单个答案的绝对质量(是好是坏),而不仅仅是相对好坏。
- 生成损失 Lg\mathcal{L}_g (Generation Loss) :标准的语言模型损失,用在「好答案」上,保持模型的生成能力和流畅性。
- 总损失是这三者的加权和:L=wpLp+wqLq+wgLg\mathcal{L} = w_p\mathcal{L}_p + w_q\mathcal{L}_q + w_g\mathcal{L}_g。
- InternVL3 的实践:
在数据方面,InternVL3 使用了基于 MMPR v1.2 构建的约 300K 偏好样本对,覆盖问答、科学、图表、数学、OCR、文档等多个领域。用 SFT 后的 InternVL3 模型(不同尺寸)生成候选回答,再进行偏好标注。
实验表明,经过 MPO 训练后,模型的推理能力(尤其在数学和逻辑基准上)得到了显著提升。重要的是,这些提升主要来自于 MPO 算法本身,而不是仅仅增加了数据量(MPO 数据是 SFT 数据的一个子集)。
3.4 测试时扩展 (Test-Time Scaling)
模型训练好了,在实际应用(测试)时还能不能再提升一下性能?InternVL3 使用了一种非常常见的测试时扩展策略:Best-of-N (BoN)。
首先,对于一个给定的问题(尤其是需要复杂推理的,如数学题),让训练好的 InternVL3 模型生成 N 个不同的候选答案(比如通过调整随机性参数)。然后,使用一个独立的评价模型 (Critic Model) 来评估这 N 个答案的质量,选出得分最高的那一个作为最终输出。
InternVL3 团队专门训练了一个名为 VisualPRM (Visual Process Reward Model) 的 8B 参数量的模型作为评价者。VisualPRM 的特点是,它不仅能给整个答案打分,还能评估解决方案的每一步 (step-by-step) 的正确性,然后综合得到总分。这使得它对解题过程的评估更加细致和可靠。这个模型本身也是基于高质量的、带有步骤对错标注的多模态问答数据训练得到的。
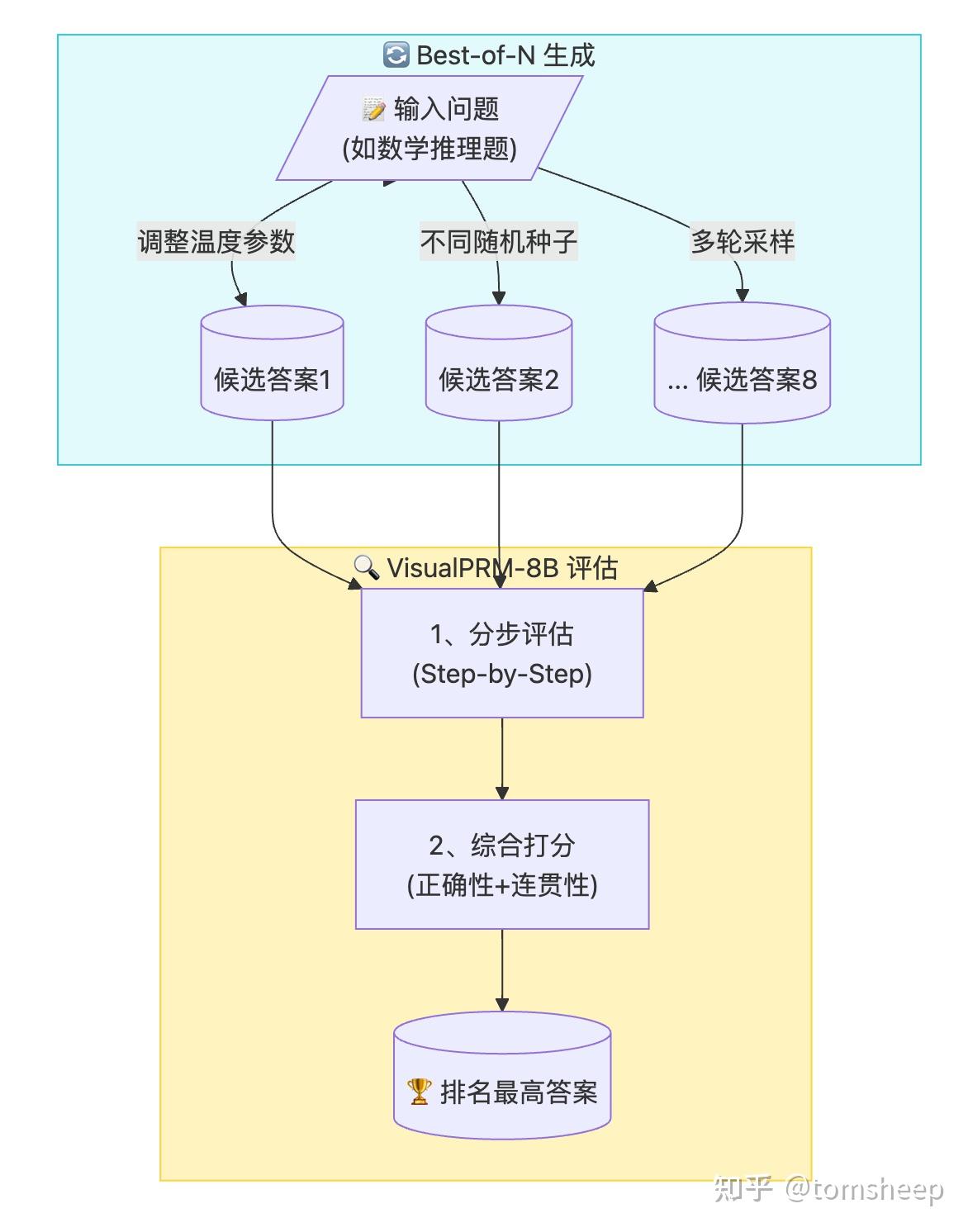
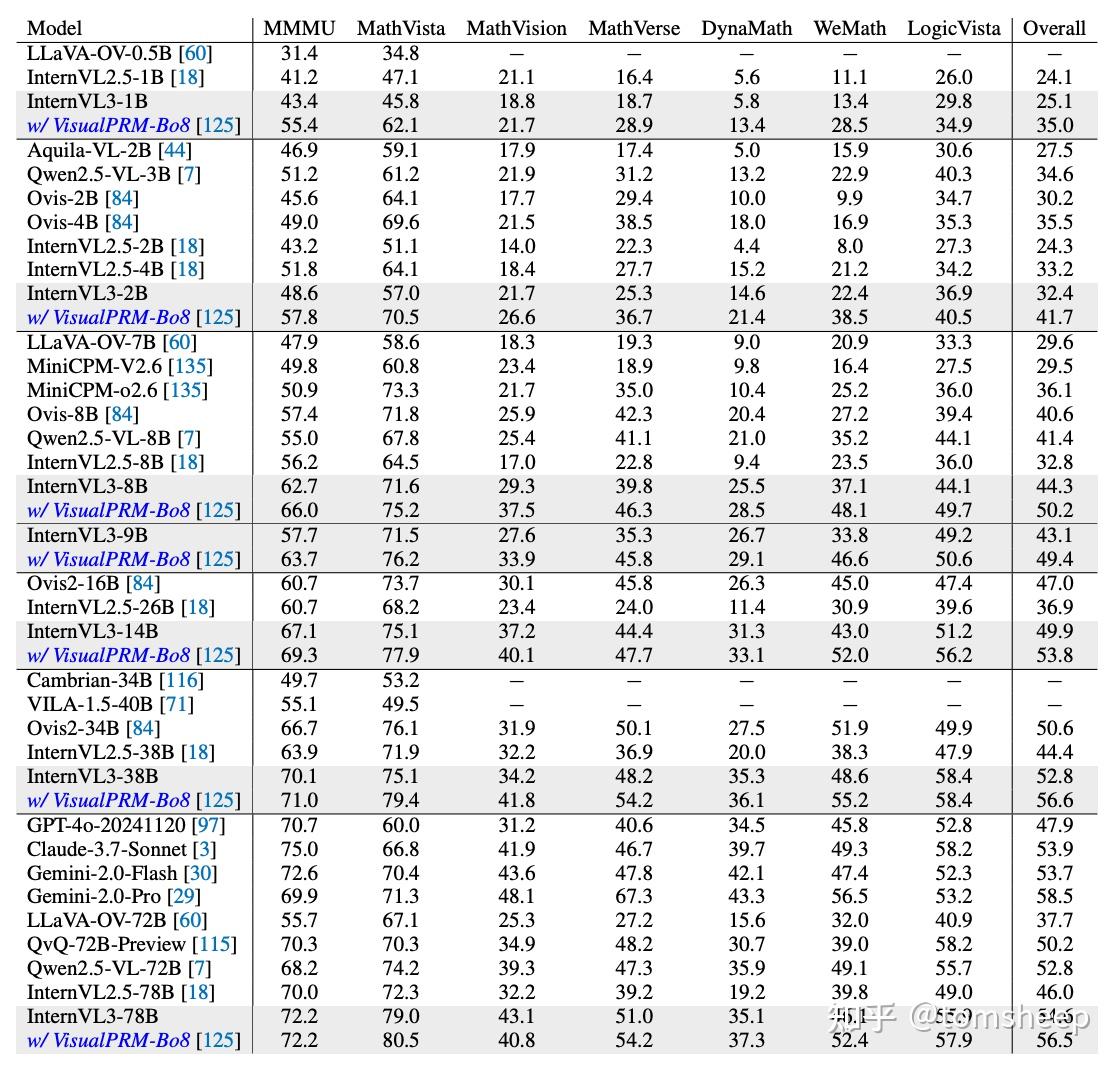
实验表明,使用 VisualPRM-8B 进行 Best-of-8 (即生成 8 个候选答案选最优) 策略,可以在多个推理基准(如 MathVista, MathVerse)上显著提升 InternVL3 的性能,即使是较小规模的模型也能从中受益。
3.5 InternEVO:优化的训练基础设施
训练 MLLM 比训练纯 LLM 更复杂,因为涉及到 ViT、MLP、LLM 三个不同计算特性的模块,以及视觉和文本两种不同长度和类型的 token,很容易出现计算负载不均衡、通信瓶颈等问题。InternVL3 的高效训练得益于团队扩展和优化的 InternEVO 框架。
InternEVO 的优化:
- 灵活解耦的分片策略 (Decoupled Sharding) :允许为 ViT、MLP、LLM 分别设置最优的并行策略(数据并行、张量并行、流水线并行等),更好地平衡负载。
- 全面的并行支持:支持各种并行方式及其任意组合,适应不同模型规模和硬件环境。
- 动态负载均衡 (Dynamic Load Balancing) :缓解因视觉/文本 token 比例变化导致的计算倾斜。
- 长序列优化 :结合头并行 (Head Parallelism) 和序列并行 (Sequence Parallelism),有效支持高达 32K 的长序列训练。
- 通信优化 :通过计算和通信的重叠 (Overlap) 等技术减少等待时间。
相比于训练 InternVL 2.5 时使用的基础设施,InternEVO 带来了 50% 到 200% 的训练速度提升(在同等计算预算下)。
四、 实验效果
4.1 综合能力
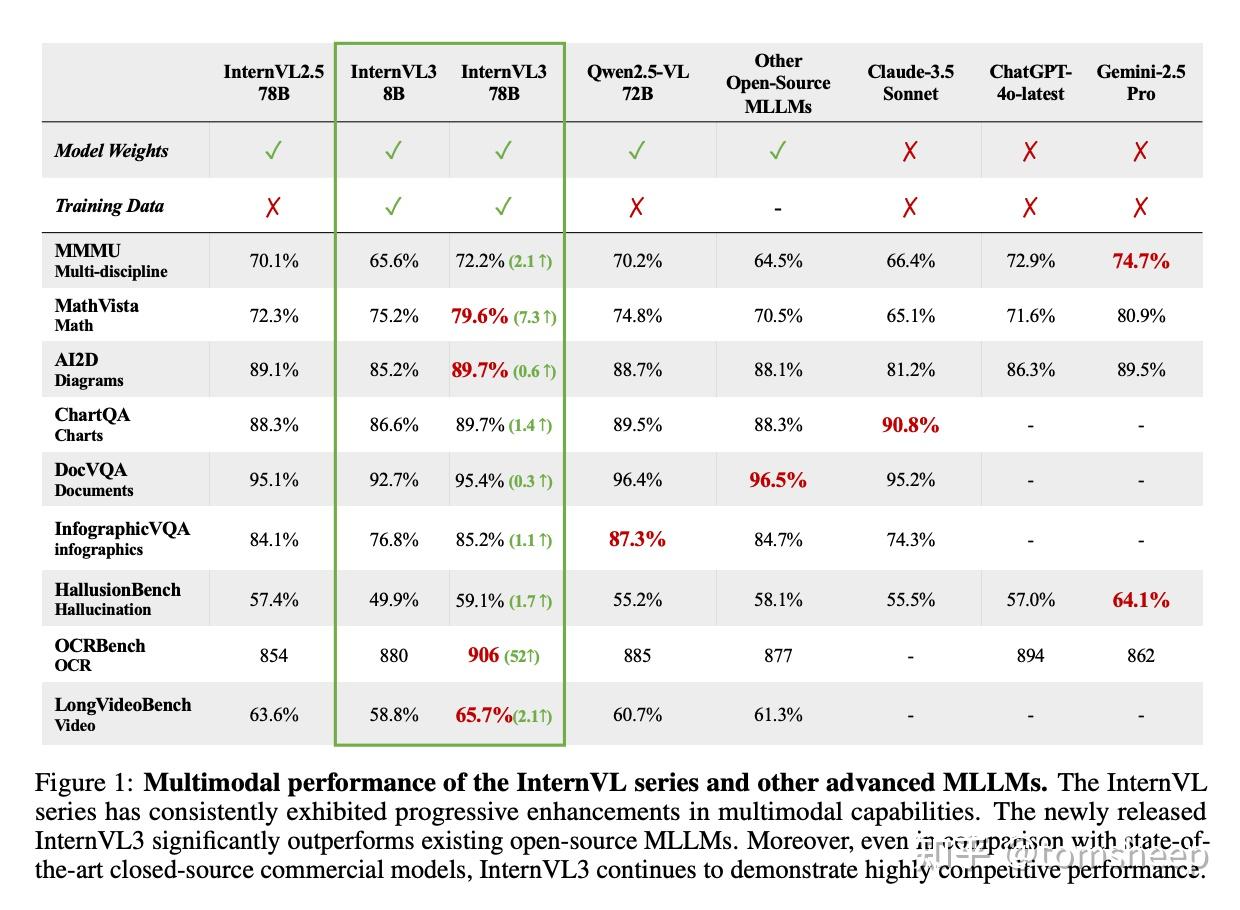
- MMMU (大规模多学科多模态理解与推理基准):这是衡量 MLLM 综合认知能力的一个高难度基准。InternVL3-78B 取得了 72.2 分,不仅刷新了开源 MLLM 的记录,而且显著超过了之前的 SOTA 开源模型(如 InternVL 2.5 的 70.0,Qwen2.5-VL 72B 的 70.2)。
- 与商业模型比肩:InternVL3-78B 的 72.2 分已经非常接近甚至超过了一些顶尖商业模型(如测评时的 ChatGPT-4o 最新版 72.9%,Claude 3.5 Sonnet 66.4%)。虽然与 Gemini 2.5 Pro (74.7%) 仍有差距,但已经将性能鸿沟大大缩小。
4.2 专项能力
| 能力维度 | 关键指标 | 78B模型表现 | 对比标杆 |
|---|---|---|---|
| 多模态推理与数学 | MMMU/MathVista/MathVerse | MMMU 72.2 (SOTA) | 超Qwen2.5-VL,近GPT-4o |
| OCR/图表/文档理解 | ChartQA/DocVQA/OCRBench | OCRBench 906 (↑52 vs 2.5-78B) | 显著优于GPT-4o |
| 多图像理解 | BLINK/MMT-Bench/MuirBench | MMT-Bench 73.2 | MuirBench弱于Qwen2.5-VL |
| 真实世界理解 | RealWorldQA/WildVision | WildVision 73.6 | 多项超GPT-4o |
| 综合多模态评估 | MME/MMBench/MMVet | MMBench 88.7 (EN) | 全面领先开源模型 |
| 幻觉控制 | HallusionBench/POPE | HallusionBench 59.1 | 落后Gemini 2.5 Pro(64.1) |
| 视觉定位 | RefCOCO系列 | RefCOCOg 91.5 | 78B略低于2.5-78B |
| 多语言能力 | MMMB/Multilingual MMBench | 平均67.4 (6语言) | 超Claude-3.5 |
| 视频理解 | VideoMME/LongVideoBench | LongVideoBench 65.7 | 接近Gemini 1.5 Pro |
| GUI/空间推理 | ScreenSpot/VSI-Bench | ScreenSpot-V2 90.9 (↑6.5 vs GPT-4o) | 显著优于商业模型 |
关键发现:
-
规模优势:78B模型在80%任务上达到SOTA
-
新领域突破:GUI定位(ScreenSpot)和3D推理(VSI)表现突出
-
待改进项:
- 幻觉控制(落后Gemini 2.5 Pro 5分)
- 多图像理解(MuirBench差距明显)
- 视觉定位(大规模模型反降)
4.3 意外发现:多模态训练反哺语言能力
这个结果很有意思。研究者们对比了 InternVL3 模型(基于 Qwen2.5 base LLM 构建)和 Qwen2.5 Chat 模型(同样基于 Qwen2.5 base LLM,但专门进行语言指令微调)在纯语言任务上的表现。发现能力不但没有损害,而且分数还涨了。
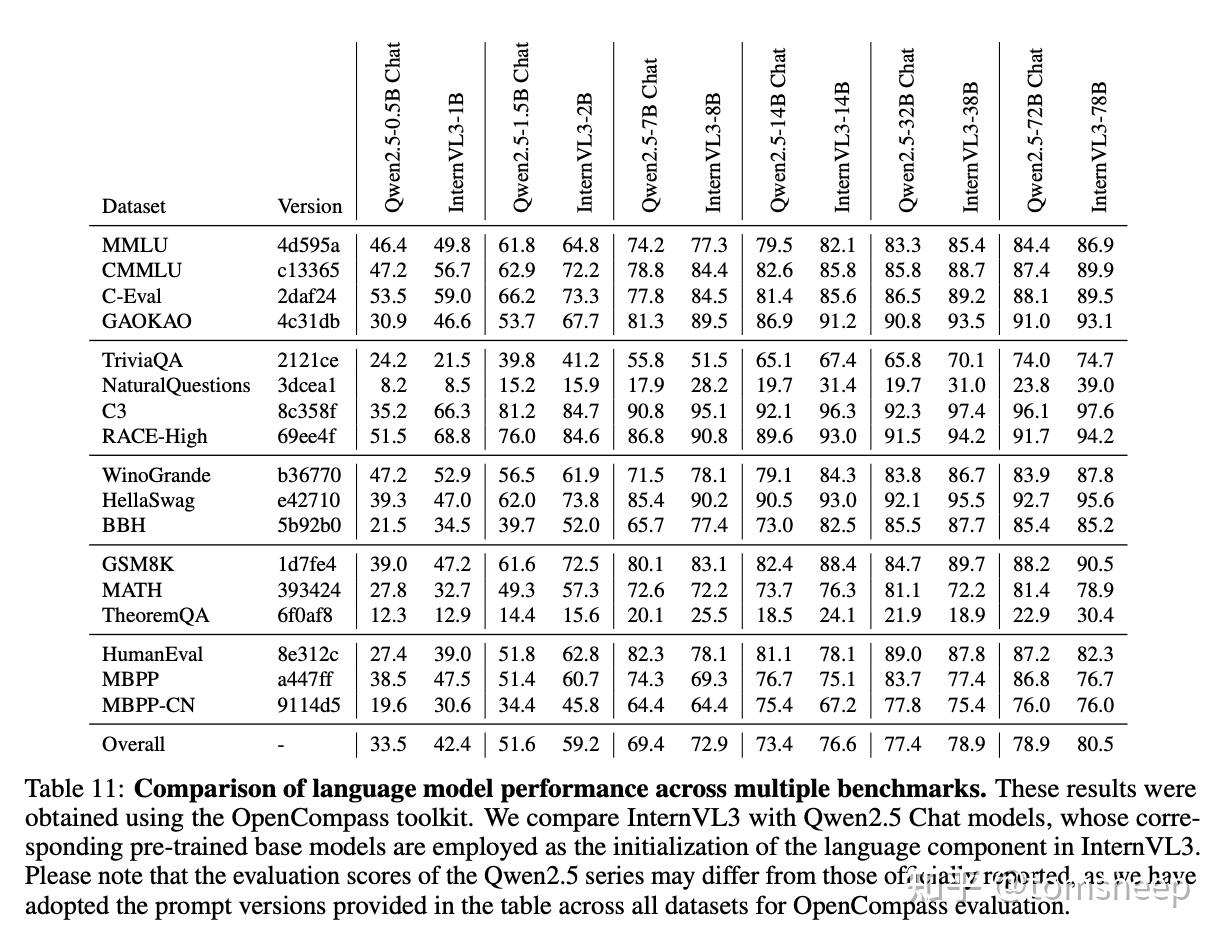
这有可能说明,让模型接触和理解视觉世界,建立起语言符号与真实世界实体的联系,可能反过来促进了模型对语言本身更深层次的理解、常识推理和知识运用能力。视觉信息可能为语言学习提供了宝贵的「锚点」和「具身经验」。
但目前还不能下结论,这是一个值得继续研究的点。
4.4 技术有效性验证:消融研究
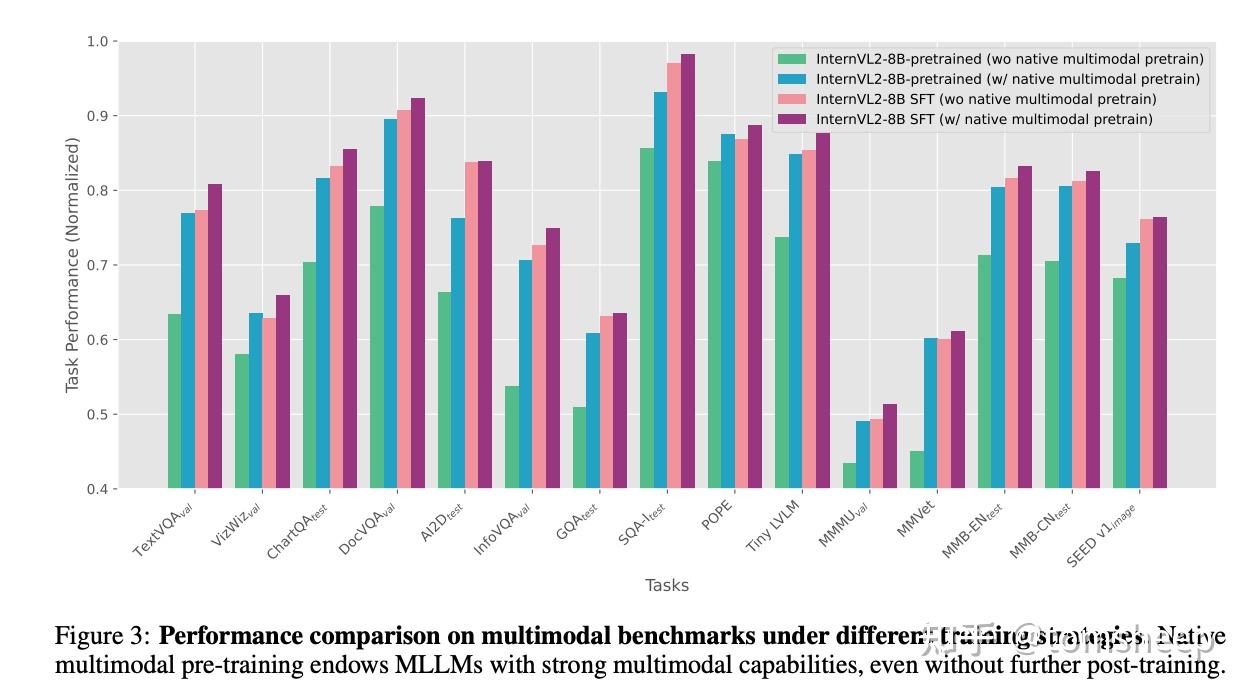
为了证明各项技术确实有效,研究者们做了消融实验:
- 原生预训练的价值:单独将 InternVL 2-8B 的 MLP 预热阶段替换为原生预训练,发现仅此一步就能达到接近完整多阶段训练的性能。这证明了原生预训练范式本身的有效性和高效性。
- V2PE 的作用:如前所述,V2PE 不仅解决了长序列问题,在标准任务上也能带来提升,且较小的 δ\delta 效果不错。
- MPO 的威力:MPO 显著提升了模型的推理能力,尤其是在数学和逻辑任务上,证明了偏好学习在提升 MLLM 可靠性方面的重要性。
五、贡献
- 范式转变的可能性:InternVL3 成功验证了「原生多模态预训练」的可行性和优越性。这可能会引领 MLLM 训练范式从「后期改造」向更统一、更原生的方向转变。未来的 MLLM 可能会越来越多地采用类似或更彻底的联合训练策略。
- 开源贡献:团队不仅发布了模型权重,还公开了训练数据 (InternVL-Data) 和代码。InternVL3 的性能表现,缩小了开源模型与顶级闭源模型之间的差距。这无疑会推动开源 MLLM 生态的发展,为学术研究和产业应用提供更高质量、更易获取的基础模型。
- 能力边界的拓展:InternVL3 在 GUI 理解、空间推理等新领域的出色表现,展示了 MLLM 在更广泛、更实用的场景中落地的潜力,例如 AI Agent、人机交互、机器人视觉等。
- 对语言与视觉关系的再认识:InternVL3 意外地提升了语言能力,这促使我们重新思考视觉经验对于语言理解的重要性。也许,通往更强大语言智能的道路,离不开对真实世界的感知和理解。
六、不足
一些可以深入探讨或改进的地方:
- 原生预训练的「纯粹性」:虽然称为「原生」,但仍然依赖于强大的预训练 ViT 和 LLM 进行初始化。这无疑大大降低了训练成本,但也使得我们无法完全判断这种联合训练范式相比于「从零开始」(
from scratch) 的真正效果如何。其成功在多大程度上归功于强大的初始化,多大程度上归功于联合训练本身? - 视觉定位能力的瓶颈:在超大模型(78B)上,视觉定位 (
visual grounding) 性能相比 26B/38B 版本提升有限甚至略有下降。作者推测是数据比例问题,但这表明在扩展模型时,如何平衡各种细粒度能力(如定位)与宏观理解能力是一个挑战。可能需要更精细的数据工程或模型结构设计。 - 幻觉问题仍存:虽然在 HallusionBench 等基准上表现不错,但与 Gemini 2.5 Pro 等顶尖模型相比仍有差距,表明减少 MLLM 的幻觉仍然是一个重要的开放性问题。MPO 等对齐技术有所帮助,但可能还不够。
- V2PE 的深入理解:V2PE 在标准任务上的意外提升值得进一步探究。为什么较小的 δ\delta 反而更好?这是否意味着当前模型对位置信息的利用方式还有优化空间?δ\delta 的选择策略(训练时随机 vs 推理时固定/自适应)如何影响不同类型的任务?
- 真实世界泛化性:虽然增加了一些真实世界数据(GUI、3D 等),并在相应基准上表现良好,但模型在开放、动态、交互式真实世界场景中的表现仍有待检验。静态基准测试与实际应用之间仍有差距。
- 多模态生成:当前仍然着眼于「多模态理解」,没有生成非文本的能力。
- 计算资源需求:训练和部署如此庞大的模型(尤其是 78B 版本)需要巨大的计算资源,这限制了其在资源受限环境下的应用和研究。虽然 InternEVO 优化了训练效率,但绝对门槛依然很高。
七、 未来展望
InternVL3 也为未来的研究留下了许多值得探索的方向:
- 更彻底的原生训练:能否从零开始 (from scratch) 联合训练 ViT 和 LLM?虽然计算成本极高,但这将是验证原生范式潜力的终极测试。
- 数据策略的精益求精:如何更动态、更智能地混合文本与多模态数据?如何进一步提升数据质量和多样性?如何解决特定能力(如视觉定位)在扩展中可能遇到的瓶颈?
- 更强的对齐与推理:如何进一步提升模型的复杂推理能力,减少幻觉,提高回答的可靠性和安全性?MPO 是一个好的方向,但可能还需要更先进的对齐技术。
- 效率与部署:如何让强大的 MLLM 更高效地训练和部署?模型压缩、量化、蒸馏等技术在 MLLM 上的应用仍然是重要的研究方向。
- 超越图像和文本:如何将更多模态(如音频、传感器数据、3D 点云等)更自然地融入原生训练框架?


















 152
152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









