







工作流
首先你得有所有paper的pdf文件库吧,然后这些文件都是这么命名的:

故而需要把文件全都重命名,要包含标题/年份/会议/作者这些信息,然后按照机构分类,在机构下再重编号,比如"IMEC001_IEDM2017_Ge stained metal stack FinFET xxxxxxxxx_Mark harley yyyyyyyy.pdf" 。
这里我们以比利时的IMEC为例进行处理整理,看看我们怎么来做这件事吧。

文献整理(mendeley)
首先我们在WOS上获得了论文数据表格,非常详尽哈。

基于这个表格,我们要筛选出IMEC的paper的所有行,就用查找/筛选这两项就可以了,然后添加一列内容为year-conf-title的格式,便于排序形成检索的依据。

用mendeley desktop软件进行初步的重命名,便于形成检索,这个很好用,
批量拖拽未合法命名的论文pdf文件,进入mendeley,可自动抓取pdf的论文标题/作者/出版会议/年份/摘要/DOI等信息,并对pdf文件自动重命名为”年份-会议-标题-作者.pdf”。
-
批量拖拽,生成论文列表


-
抓取年份/作者/标题等信息,自动重命名

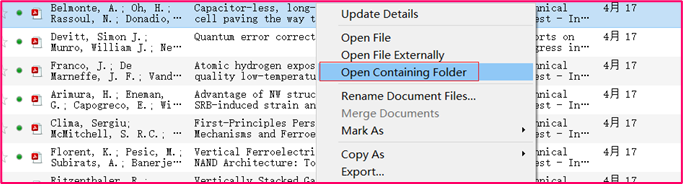
-
打开文件所在路径,导出命名好的pdf

批量序列化重命名(advanced_renamer)
advanced_renamer这个软件也是神奇嗷,但是你编订的命名列表里不要含有“/ \ : ! & ”这些字符,会报错,在excel里把他们替换掉吧。
-
在excel中使用筛选工具选出IMEC机构一作的全部文献后,按“年份-标题”进行排序,粘贴进advanced_renamer。

-
导入pdf文件的顺序要与表格的内容顺序一致,且不重不漏。
-
批量重命名
研究机构提取(matlab/python)
接下来需要提取一些第二第三第四单位等信息,提进表格里。写了一个小脚本
- 找出所有]和[之间的字符串,即为机构名


在我的下一篇博客里 Matlab脚本分享:字符串列表的正则检索、分割提取

表格信息录入
这些就是需要一篇一篇读文章来获取的内容了。

简单的数据统计分析

卡尔斯鲁厄大学跟IMEC是深度绑定的两个单位,这里就看看这两个的paper的数量关系。其中2018年的KULV的paper我这应该是不太全的,抱歉。

















 2664
2664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









