









文章信息
文献题目:Cross-scale Multi-instance Learning for Pathological Image Diagnosis 跨尺度多实例学习用于病理图像诊断关注wx公众号:欣欣影像科研懒人包
研究人员:Ruining Deng, et al.
发表时间:2024.07
期刊名称:Nature Medicine
影响因子:10.70
公开源码:https://github.com/hrlblab/CS-MIL
1. 前言:
炎性肠病(如克罗恩病)是临床诊断中的一个重要问题,病理学作为诊断这一疾病的金标准,长期以来依赖病理学家通过显微镜对组织切片进行多尺度的形态学分析。然而,这一过程不仅繁琐,而且高度依赖于病理学家的经验和直觉,容易受到主观因素的影响。随着数字病理学的发展,借助全切片图像(Whole Slide Images, WSI)和深度学习技术,计算机辅助病理诊断的潜力日益显现,为提高诊断效率和准确性提供了新的可能。
尽管如此,现有的数字病理学方法主要集中在单一尺度的图像分析上,忽略了病理图像中跨尺度信息的关键作用。病理图像通常包含从局部细节到全局结构的多种尺度,而这一信息的缺失可能会导致病理评估的局限性。为了解决这一问题,许多研究尝试采用多尺度学习策略,以便同时捕捉图像的局部特征和全局特征。然而,大多数现有的方法在多尺度信息的融合上还停留在后期融合的层面,无法充分挖掘各尺度之间的交互关系。
为此,研究旨在弥补这一不足,提出了一种创新性的跨尺度多实例学习(Cross-Scale Multi-Instance Learning, CS-MIL)算法。该算法通过引入基于注意力机制的“早期融合”策略,在特征提取的过程中显式地建模不同尺度之间的交互关系。通过跨尺度的特征融合,充分利用每个尺度的形态学特征,并在此基础上学习它们之间的相互作用,从而提升病理图像的诊断效果。
该研究做出了以下三个贡献:关注wx公众号:欣欣影像科研懒人包
-
提出了一种新型的跨尺度MIL算法,通过引导的注意力机制在特征提取过程中建模跨尺度关系,显著提升了不同尺度之间信息的利用效率。
-
创建并发布了一个具有尺度特异性形态学特征的模拟数据集,用于检验和可视化不同尺度之间的注意力差异。
-
通过实验验证,证明了跨尺度MIL策略在内部数据集和公开数据集上的优越性能,与现有的多尺度MIL方法相比,表现出了更高的曲线下面积(AUC)和平均精度(AP)评分。

图1 多尺度感知。由于在不同分辨率下组织样本呈现异质性的结构模式,病理学家需要在整张切片图像的多个尺度上仔细检查活检样本,以捕捉用于疾病诊断的形态学特征。
2. 相关文献
2.1 Multi-instance Learning in Digital Pathology
在临床数字病理学领域,疾病相关的组织区域通常仅占整个组织样本的一小部分,这就导致了大量不包含疾病的图像块(patch)。病理学家利用显微镜在不同放大倍数下仔细检查组织,寻找与疾病相关的区域,并随后分析其形态学特征。
然而,由经验丰富的病理学家对疾病相关区域进行图像块级别的标注是一项繁琐的任务,且在大规模的Giga级像素图像上扩展时面临挑战。为了解决这一问题,近年来有多项研究(Hou 等,2016;Campanella 等,2019;Hashimoto 等,2020b;Wang 等,2019;Skrede 等,2020;Lu 等,2021b,a)展示了弱监督技术——多实例学习(MIL)的前景,MIL是一种广泛应用于图像块级分析的弱监督学习范式,其中基于图像块的分类器(例如,患者级诊断)仅依赖于切片级别的标签进行训练。
在MIL的框架下,每个全切片图像(Whole Slide Image, WSI)被视为一个包含多个图像块的袋(bag)。如果该图像中的任何图像块(即实例)展示出与疾病相关的特征(例如,病变、肿瘤、异常组织),则该切片袋被标记为疾病相关。分类器通过提取和聚合图像块的特征或得分,来预测切片级别的标签(Li 等,2021)。基于MIL的方法近年来在特征提取和聚合方面大大受益于深度神经网络(Ilse 等,2018;Wang 等,2016;Oquab 等,2015)。例如,Yao 等(Yao 等,2020)采用了基于袋的策略,将图像块聚类为不同的“袋”,以建模并聚合多样的局部特征,从而进行患者级诊断。类似地,Hou 等(Hou 等,2016)提出了一种决策融合模型,该模型聚合了由图像块级CNN生成的图像块级预测。Hashimoto 等(Hashimoto 等,2020b)提出了一种新的基于CNN的技术,通过有效地融合多实例、领域对抗和多尺度学习框架,在图像块级别进行癌症亚型分类。关注wx公众号:欣欣影像科研懒人包
2.2 Multi-scale in Digital Pathology
数字病理学处理的是金字塔结构的千兆像素图像。不同的分辨率呈现出组织样本的异质性结构模式,因此病理学家需要在多个尺度下仔细检查活检样本,以捕捉用于疾病诊断的形态学特征(Gordon等,2020)。这一过程非常耗时,并且通过逐步放大/缩小的操作会导致空间相关性的丧失。使用AI模型在多个尺度上分析图像不仅通过利用尺度感知的知识提高模型性能,而且还能利用模型学习到的跨尺度关系,保持空间一致性。
早期的研究考虑了多个尺度下的形态学特征。Hashimoto等(2020a)提出了一种创新的基于CNN的方法,用于癌症亚型分类,通过有效整合多实例学习、领域对抗学习和多尺度学习框架,将来自不同尺度的知识结合在一起。Li等(2021)采用了特征拼接策略,将来自不同尺度的每个区域的高层特征合并,以融入通过CNN特征提取器获得的跨尺度形态学模式。Barbano等(2021a)提出了一种多分辨率方法,用于异常增生分级。视觉变换器(ViTs)作为一种从大规模图像中学习特征的有前景的方法,因其能够利用位置注意力而备受关注。Chen等(2022)最近提出了一种新型的ViT架构,利用WSI的固有层次结构,通过两级自监督学习来学习高分辨率的图像表示。
然而,以上方法都未能全面学习来自多个尺度的知识,即未能考虑跨尺度关系。为了解决这一限制,作者提出了一种基于注意力的“早期融合”范式,提供了一种有前景的方式,用于在早期阶段建模跨尺度关系。关注wx公众号:欣欣影像科研懒人包
3. 方法
作者所提出的CS-MIL的整体流程如图2所示。作者提出了一种基于注意力的“早期融合”范式,旨在以整体方式捕捉跨尺度关系。首先,从WSI中联合拼接具有相似中心坐标但来自不同尺度的图像块。然后,使用自监督模型提取每个图像块的表型特征。对每个WSI应用基于局部特征的聚类,将表型模式分配到每个MIL包中。接下来,进行跨尺度注意力引导的MIL,以在多尺度和多聚类设置中聚合特征。最后,生成跨尺度注意力图供人工肉眼检查。
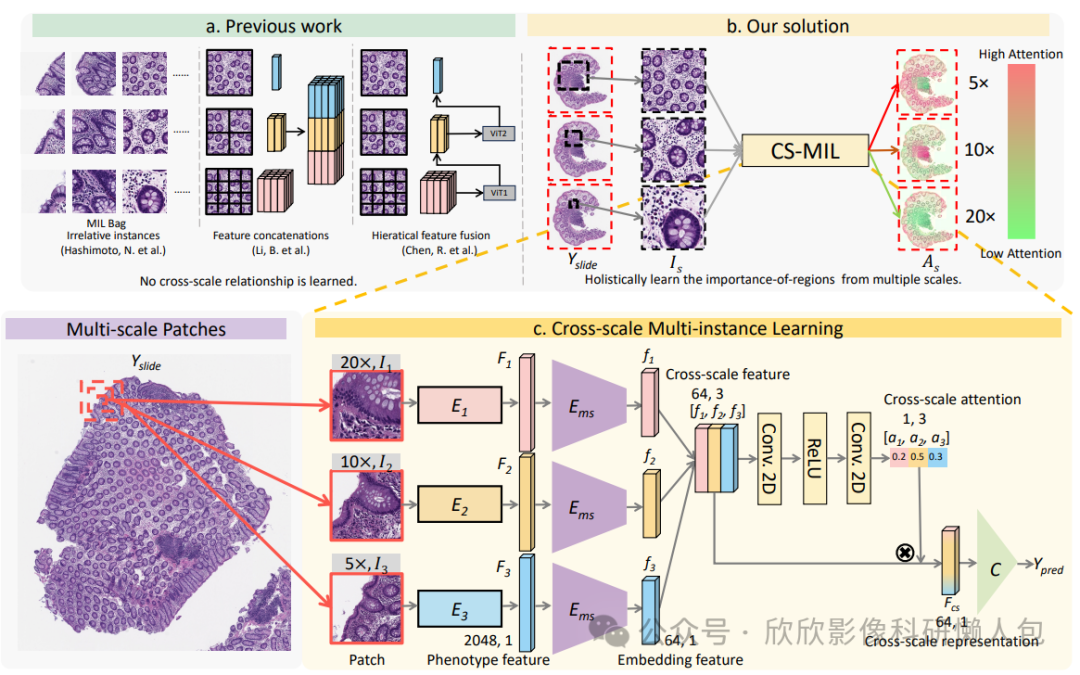
图2 多尺度MIL设计。
a. 以往的研究没有考虑不同分辨率之间的跨尺度关系。
b. 作者的解决方案通过跨尺度注意力图识别重要区域,并通过乘以跨尺度注意力得分将跨尺度特征聚合为跨尺度表示,用于病理图像的诊断。
c. 跨尺度注意力机制用于合并具有不同注意力得分的跨尺度特征。来自不同聚类的跨尺度表示被拼接用于病理分类。
3.1 特征嵌入和表型聚类
在MIL(多实例学习)领域,大多数组织病理图像分析方法被分为两个阶段(Schirris et al., 2021;Dehaene et al., 2020):(1) 自监督特征嵌入阶段,(2) 基于弱监督的特征学习阶段。作者的方法采用了类似的设计,通过利用数据集训练一个对比学习模型SimSiam(Chen and He, 2021),作为表型编码器(Es),从图像块(Is)中提取高层次的表型特征(Fs),如公式1所示。SimSiam通过最大化不同图像增强之间的样本内相似性,在没有标签的情况下,展示了比其他骨干网络更优的特征提取性能。关注wx公众号:欣欣影像科研懒人包
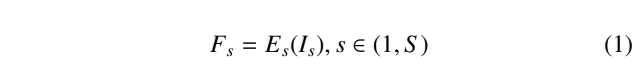
其中,S是WSI图像的尺度数量。作者分别使用来自不同尺度的图像块训练了三个预训练的编码器(Es)。这一自监督学习阶段对于有效特征提取至关重要,在后续的弱监督特征学习阶段之前。所有的图像块随后都被嵌入到低维特征向量中,用于第二阶段的分类。
受到(Yao et al., 2020)的启发,作者使用k-means聚类方法对第一阶段中20×放大倍数的自监督嵌入进行患者级别的图像块聚类。需要注意的是,高层次的特征比低分辨率缩略图在表征表型方面更为全面(Zhu et al., 2017)。这些图像块从不同的聚类中平衡地收集到每个包中,随后根据WSI上稀疏分布的独特表型模式组织出具有更好泛化性的包。另一方面,相似的高层次特征图像块被聚合用于分类,且没有空间限制。
3.2 跨尺度注意力机制
作者的方法基于MIL(多实例学习)相关文献的前期工作,加入了一个跨尺度注意力机制,用于捕捉整个幻灯片图像(WSIs)中的尺度模式。具体来说,其利用基于CNN的编码器对来自相应表型聚类的图像块嵌入进行精炼。然后,实例级别的特征被聚合以实现患者级别的分类,从而在WSIs上的生存预测中取得了更好的性能。
虽然在之前的研究中,已有提出注意力机制来增强模型对WSI中空间位置模式的利用(Ilse et al., 2018;Lu et al., 2021b),但这些方法并未充分利用WSI中跨尺度的模式。其他一些方法则将多尺度特征聚合进深度学习模型(Hashimoto et al., 2020a;Li et al., 2021),但在利用同一位置的多个分辨率之间的相互作用上存在局限性。
为了解决这个问题,作者提出了一种新颖的跨尺度注意力机制,在骨干网络中表示对不同尺度的感知。
首先,来自表型编码器(Es)的跨尺度特征(fs)通过一个多尺度编码器(Ems)进一步处理,其中使用了来自DeepAttnMISL(Yao et al., 2020)的孪生多实例全卷积网络(MI-FCN)进行处理,如公式2所示:
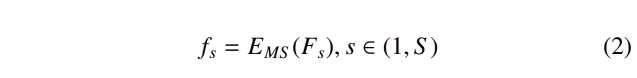
其中,S是WSI中尺度的数量。所有的多尺度编码器(EMS)在不同尺度之间共享权重。接下来,应用跨尺度注意力机制,考虑每个尺度在同一位置中的重要性。跨尺度特征(fs)同时输入到跨尺度多实例学习网络(CS-MIL)中,CS-MIL包含两个大小为1×1的全卷积层和ReLU激活函数。CS-MIL的输出是通过将跨尺度特征作为整体来计算的跨尺度注意力分数(as),其计算公式为公式3:
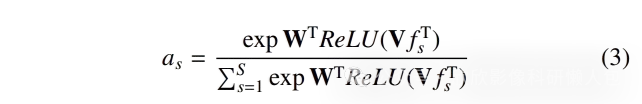
其中,W ∈ R^(L×1),V ∈ R^(L×M) 是CS-MIL中的可训练参数,L是EMS输出特征(fs)的大小,M是CS-MIL第一层的输出通道数,tanh(.)是逐元素的非线性激活函数,S是WSI中尺度的数量。
然后,将跨尺度注意力分数(as)与跨尺度特征相乘,得到融合后的跨尺度表示(如公式4所示):
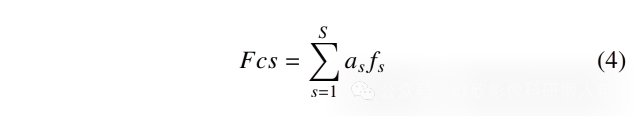
最后,使用(Yao et al., 2020)提出的基于注意力的实例级池化操作符(C),通过跨尺度嵌入实现患者级别的分类,如公式5所示,n为包的大小:
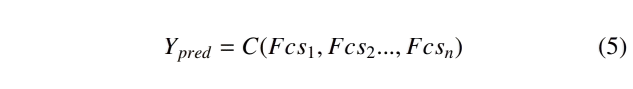
3.3 跨尺度注意力可视化跨尺度注意力机制
根据来自CS-MIL的跨尺度特征(fs)为每个区域(Is)生成注意力分数(as)。这些注意力分数反映了在融合跨尺度表示(Fcs)以进行最终分类(C)时,不同尺度的表型特征对诊断的相对重要性。通过将这些分数填充回对应的WSI位置,获得了一个注意力图(As),它结合了尺度和位置信息。该图为在不同上下文中进行疾病引导的探索提供了见解,展示了跨尺度机制的多样性和实用性。
4. 实验
4.1 数据
In-house CD(Crohn's Disease,克罗恩病)dataset:
-
样本来源:从20名克罗恩病(CD)患者和30名健康对照者收集了50例H&E染色的升结肠(AC)病理活检样本用于训练。
-
染色与扫描:染色组织在20×放大倍数下进行扫描。
-
病理诊断:20张CD患者的切片被评分为正常、静止、轻度、中度或重度,而其余健康对照者的切片被评分为正常。
-
测试数据:使用相同的程序扫描了116个AC活检样本进行测试,来自72名与训练数据中患者无重叠的CD患者。
TCGA-GBMLGG dataset:
-
样本来源:从癌症基因组图谱(TCGA)获得的胶质瘤数据集(GBMLGG),包含613个患者样本。
-
突变情况:330个患者具有异柠檬酸脱氢酶(IDH)突变,其余患者为正常。
4.2 实验设置关注wx公众号:欣欣影像科研懒人包
In-house CD dataset:
-
图像处理:
-
所有WSI被裁剪成大小为4096 × 4096像素的区域。
-
三个尺度(20x 10x和5x)上分别对这些区域进行256×256像素的图像块切割。
-
使用ResNet-50,训练了三个独立的模型,每个模型使用504,444个256 x 256的前景图像块。
-
-
训练设置:
-
训练过程进行了200个epoch,批次大小为128,使用SimSiam的官方设置。
-
所有图像块的嵌入向量的通道数为2048。
-
表型聚类在三个分辨率下的单尺度特征中进行,使用k-means聚类法,类别数为8,并生成跨尺度特征,涵盖每个患者的所有分辨率。
-
使用HIPT进行特征提取时,采用官方预训练实现,使用1650个4096 × 4096的区域进行处理。
-
-
数据拆分:
-
训练数据集使用“留一法”策略随机组织成10个数据拆分。
-
测试数据集按相应比例划分为10个拆分。
-
-
模型训练:
-
MIL模型用于收集每个患者的每个包,每个包选取了来自不同表型聚类类别的图像块,并用临床医生标注的切片标签(Yslide)标记。
-
训练的超参数与DeepAttnMISL的设置一致。
-
采用负对数似然损失来比较包的切片预测(Ypred)和弱标签(Yslide), 其中θ代表模型参数,如公式6所示。
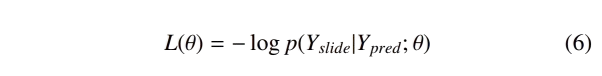
-
所有模型每4个epoch更新一次,以平稳收敛损失,并且总共训练100个epoch。
-
-
模型评估:
-
根据验证损失选择每个数据拆分上的最佳模型,然后使用10个数据拆分的平均性能评估测试结果。
-
在测试阶段,随机生成100个图像包,每个包的大小为8,以覆盖每个整体切片图像(WSI)上的大多数图像块,最终通过计算包得分的平均值得到切片级别的预测。
-
每个模型的性能使用接收者操作特征(ROC)曲线的曲线下面积(AUC)得分、精确度-召回(PR)曲线的平均精确度(AP)得分以及分类准确率进行评估。
-
所有模型在NVIDIA RTX5000 GPU上进行训练。
-
TCGA-GBMLGG dataset:
-
图像处理:
-
由于计算限制,从每个WSI中随机选择了10%的区域,得到了一个包含5132个4096 × 4096区域的数据集。
-
在预训练阶段,仅使用其中15%的区域(582,666个256 × 256前景图像块,来自755个4096 × 4096区域)来训练SimSiam模型,使用ResNet-50骨干网。
-
-
测试设置:
-
测试阶段使用了HIPT的官方预训练参数和超参数,因为HIPT在其预训练阶段已经包含了TCGA-GBMLGG数据集(包括54158个区域)。
-
训练、验证和测试样本按患者级别分割,比例为6:1:3。
-
-
模型训练:
-
在测试阶段,随机生成500个图像包,每个包的大小为32,最终通过计算包得分的平均值得到患者级别的最终预测。
-
所有模型使用NVIDIA RTXA6000 GPU进行训练。
-
5. 实验结果
5.1 实证验证
作者实现了三种相同的单尺度DeepAttnMISL (Yao et al., 2020) 模型,用于相应尺度的图像块。同时,作者还训练了以下几种模型:关注wx公众号:欣欣影像科研懒人包
-
-
门控注意力(GA)模型(Ilse et al., 2018)
-
基于多尺度图像块的DeepAttnMISL模型,不区分尺度信息
-
多尺度特征聚合(MS-DA-MIL),将来自不同尺度的相同位置的嵌入特征加入到每个MIL袋中(Hashimoto et al., 2020a)
-
不同尺度的特征拼接(DS-MIL)(Li et al., 2021)
-
双层特征蒸馏(Zhang et al., 2022),结合多尺度和多位置特征聚合
-
具有自监督学习的层级图像金字塔变
-
压器(HIPT)(Chen et al., 2022)
-
层级注意力引导的MIL(HAGMIL)(Xiong et al., 2023)
-
所提出的方法(CS-MIL)
-
根据上述多尺度融合方法,将特征输入到DeepAttnMISL网络中,以评估基线的多尺度MIL模型和作者所提出的方法。所有模型都在相同的超参数设置和数据划分下进行训练和验证。
5.1.1 分类性能
下图3显示了在CD分类任务中直接应用模型在测试数据集上的性能,而没有重新训练。同时还显示了在TCGA-GBMLGG数据集上的IDH状态分类。在一般情况下,所提出的CS-MIL在大多数评估指标上取得了更好的成绩,证明了跨尺度注意力机制的优势,它探索了MIL中不同尺度之间的相互关系。
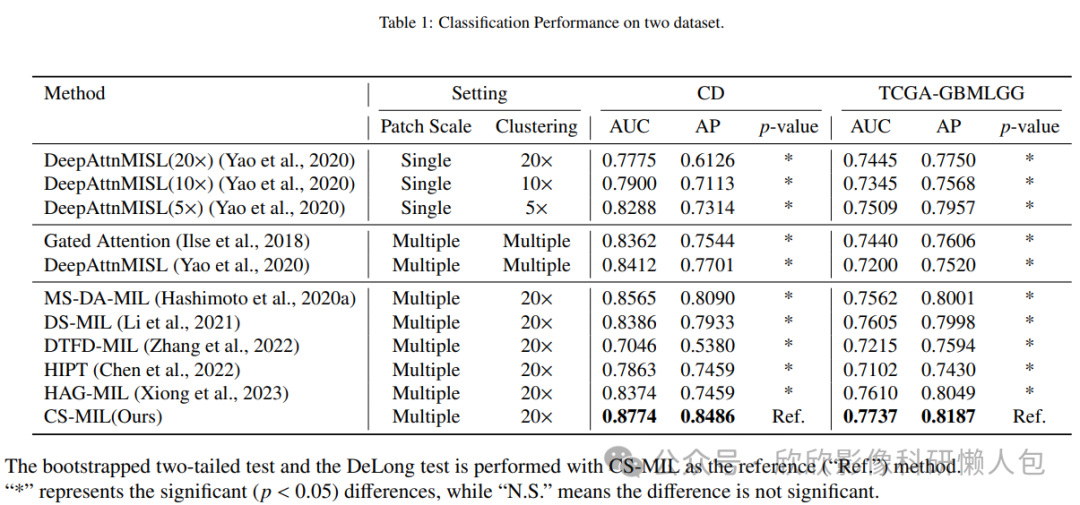
图3 两个数据集分类效能比较表
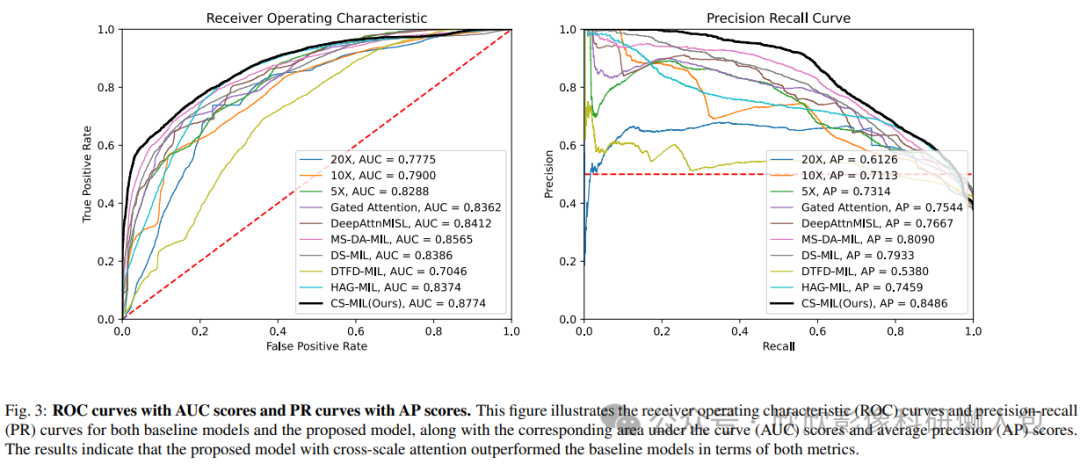
图4 ROC曲线和PR曲线及其AUC和AP得分
5.1.2 跨尺度注意力可视化
图5展示了所提出的CS-MIL在CD WSI(全切片图像)上生成的跨尺度注意力图。所提出的CS-MIL在不同尺度上展示了不同区域的重要性,融合了多尺度和多区域的可视化结果。因此,20×的注意力图突出了慢性炎性浸润区域,而10×的注意力图则集中在隐窝结构上。这些感兴趣区域解释了跨多个尺度在CD诊断中的判别性区域。
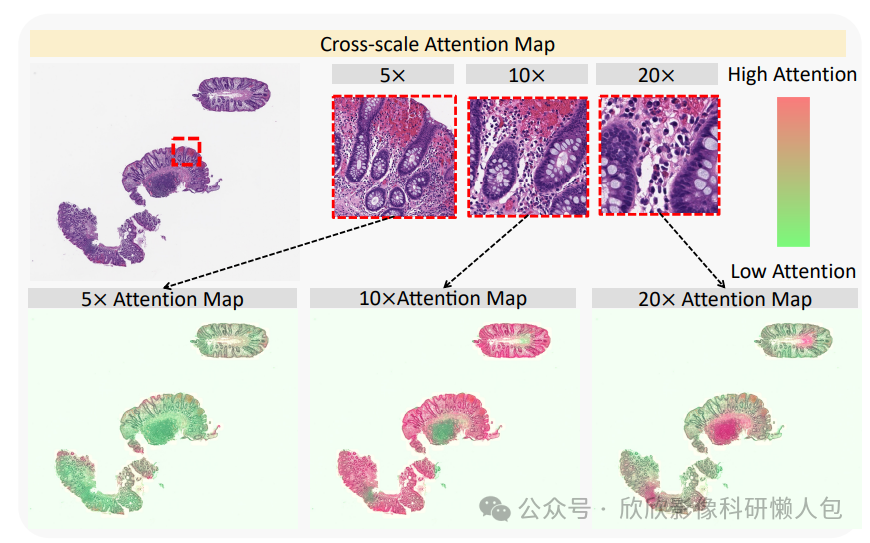
图5 注意力图可视化。该图展示了所提出模型生成的CD全切片图像(WSI)的跨尺度注意力图。20×的注意力图突出显示了慢性炎性浸润区域(The chronic inflammatory infiltrates),而10×的注意力图则聚焦于隐窝结构(The crypt structures)。这些关注区域标示了在多个尺度下可识别的、对CD诊断具有区分性的特征区域。
6. 结论
作者提出了一种新颖的跨尺度多实例学习(CS-MIL)方法,该方法有效地整合了多尺度特征与尺度间知识。此外,所提出的方法利用跨尺度注意力分数生成重要性图,从而增强了CS-MIL模型的可解释性和可理解性。从实验结果表明,所提出的方法在性能上优于现有的多尺度多实例学习基准方法。跨尺度注意力的可视化生成了尺度特定的重要性图,这可能有助于临床医生解读基于图像的疾病表型。关注wx公众号:欣欣影像科研懒人包
文章来源:
Deng, R., Cui, C., Remedios, L. W., Bao, S., Womick, R. M., Chiron, S., ... & Huo, Y. (2024). Cross-scale multi-instance learning for pathological image diagnosis. Medical image analysis, 94, 103124.

















 47
47

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









