






 文章介绍了一种新的Text2Street框架,通过大语言模型解析文本,生成遵守交通法规的道路拓扑和对象布局,结合车道感知生成器、位置依赖的对象布局生成器以及多条件图像生成器,实现对街景图像的可控生成,包括车道线、交通状态和天气条件。
文章介绍了一种新的Text2Street框架,通过大语言模型解析文本,生成遵守交通法规的道路拓扑和对象布局,结合车道感知生成器、位置依赖的对象布局生成器以及多条件图像生成器,实现对街景图像的可控生成,包括车道线、交通状态和天气条件。
Text2Street:街景的可控文本到图像生成
摘要
提出可控文本到图像框架Text2Street
1.提出感知道路拓扑生成器 实现了文本到地图的生成,,实现了可控的道路拓扑生成。
2.提出基于位置的对象布局生成器 实现可控的交通对象布局
3.多个控制图像生成器 整合道路拓扑、对象布局,实现可控街景图像生成。
介绍
挑战
1.生成遵守交通法规的道路拓扑 是一个挑战
2.生成既符合交通法规又匹配文本中指定的技术的车道线
3.天气 造成模糊或次优的结果
本文模型
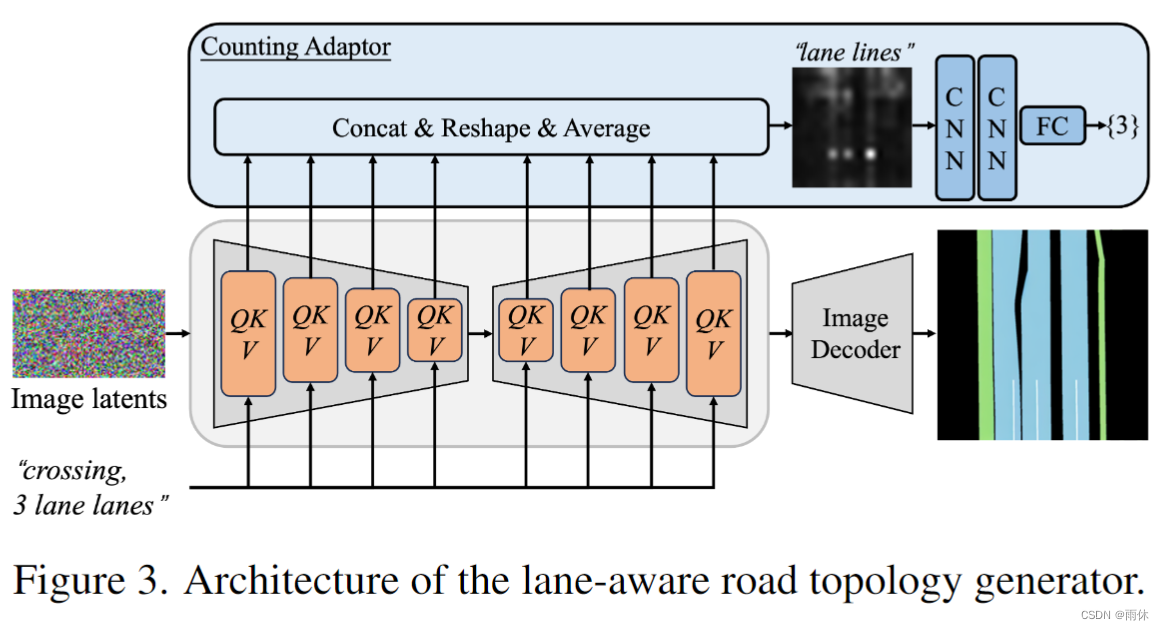
1.车道感知道路拓扑生成器,它利用文本描述来创建表示复杂道路拓扑的局部语义映射。该生成器还通过计数适配器在语义图中产生符合指定数量和交通法规的车道线。
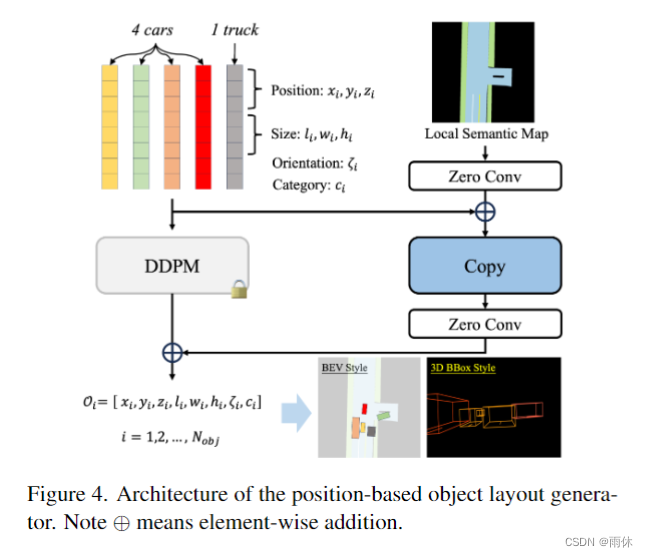
2.基于位置的对象布局生成器来捕获不同的流量状态。通过使用对象级边界框扩散策略,它根据遵循指定数量和流量规则的文本描述生成流量对象布局。
3.通过姿态采样将道路拓扑和物体布局投影到相机的成像角度。
4.使用多个控制图像生成器集成投影的道路拓扑、对象布局和文本天气描述,生成最终的街景图像。
贡献
1.提出了一种新的街道视图可控文本到图像框架,支持仅基于文本去脚本控制道路拓扑、交通状态和天气条件。
2.引入车道感知道路拓扑生成器,生成特定的道路结构和车道拓扑。
3.我们提出了基于位置的对象布局生成器,能够生成一定数量的符合交通规则的交通对象。
4.我们提出了多种控制图像生成器,可以集成道路拓扑、交通状态和天气条件,实现多条件图像生成。
相关工作
略
方法
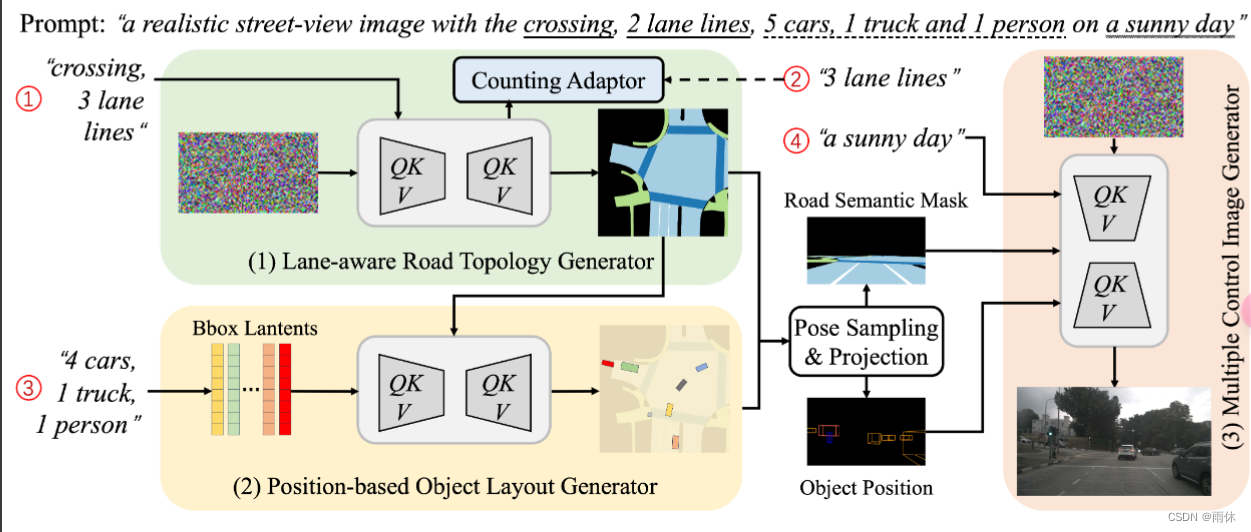
3.1 概览
输入: 文本提示:“a street-view image with the crossing, 3 lanes, 4 cars and 1 truck driving on a sunny day”
1.大语言模型(GPT4)解析提取道路拓扑
2.车道感知道路拓扑生成器 :输入道路拓扑描述“crossing, 3 lanes",输出局部语义图
3.基于位置的对象布局生成器 :输入交通对象描述"4 cars and 1 truck",输出交通对象布局
4.多控制图像生成器 :输入道路拓扑、对象布局、天气条件描述"a sunny day,输出与原始街景描述提示相匹配的图像
3.2 车道感知道路拓扑生成器
普通文本到图像的生成模型
3.3 基于位置的对象布局生成器
将一阶段的道路拓扑图作为条件,训练文本到图像的扩散模型(Controlnet)生成对象布局
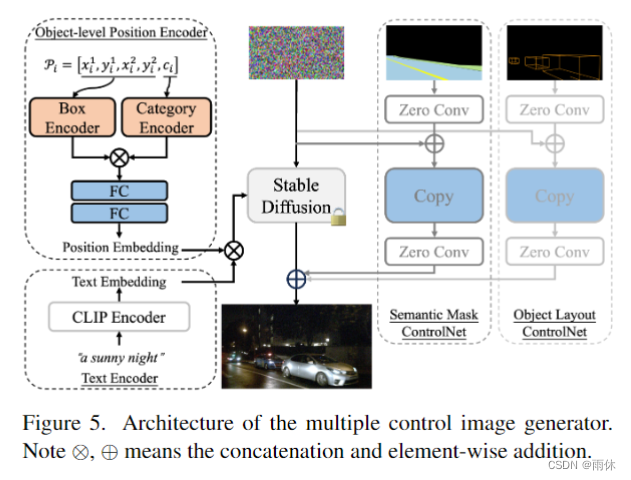
多控制图像生成器
物体级别位置编码+文本提示+道路拓扑图+对象布局控制生成图像(Stable-diffusion)

















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









