






环境:ubuntu20.04+ros noetic
参考了《ROS机器人开发实践》,由胡春旭老师所著,里面也有配套源码
https://github.com/huchunxu/ros_exploring.git
一、播放语音
让机器人说话
1、sound_play功能包
ROS中的元功能包audio-common提供了文本转语音的功能包sound_play。使用以下命令安装:
sudo apt-get install ros-noetic-audio-common
sudo apt-get install libasound2
sudo apt-get install mplayer2、语音播放测试
通过以下命令运行sound_play主节点,并进行测试:
roscore
rosrun sound_play soundplay_node.py1)测试播放内置声音:
我们使用系统内置的声音进行播放,运行如下命令:
rosrun sound_play playbuiltin.py 2如果听到两声锣声则表示运行成功。
2)测试播放 WAV 或 MP3 等声音:
使用 play.py 这个例子即可,后面的是我的 wav 路径,你可以修改成你自己的:
rosrun sound_play play.py /home/fym/Music/666.wav或者播放 MP3 文件:
rosrun sound_play play.py /home/fym/Music/666.mp33)在另一终端中输入需要转化成语音的文本信息: 文本转语音 测试语音合成
rosrun sound_play say.py "Greetings Humans. Take me to your leader."sound_play识别输入的文本,并使用语音读了出来,发出这个声音的人叫kal_diphone,你也可以换成另外的人:
sudo apt-get install festvox-don
rosrun sound_play say.py "Welcome to the future" voice_don_diphone
二、让机器人听懂语言
ROS中集成了CMU Sphinx和Festival开源项目中的代码,发布了独立的语音识别功能包——pocketsphinx,可以帮助我们的机器人实现语音识别功能。播放语音,只Plays an .OGG or .WAV file
本节实现了语音识别的基本功能,可以成功将英文语音指令识别生成对应的字符串
1、pocketsphinx功能包
sudo apt-get install ros-noetic-audio-common
sudo apt-get install libasound2sudo apt-get install gstreamer1.0
sudo apt-get install libsphinxbase3
sudo apt-get install libpocketsphinx3
sudo apt-get install libgstreamer-plugins-base1.0
sudo apt-get install gstreamer1.0-pocketsphinx
其实,可以直接
sudo apt-get install gstreamer1.0-*
sudo apt-get install gstreamer1.0-pocketsphinx
# 无需单独再安装依赖 上一条语句已经给安装期间报错:
Index of /debian/pool/main/p/pocketsphinx
可加入软件源:sudo gedit /etc/apt/sources.list
Index of /debian/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
or deb http://ftp.de.debian.org/debian bookworm main
加入公钥:sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 0E98404D386FA1D9
(后面的数字为NO_PUBKEY 后的一串)
然后
sudo apt-get update
或者 依赖问题修复
sudo apt-get -f install或者缺少依赖包multiarch-support(下载对应版本)http://launchpadlibrarian.net/416685704/multiarch-support_2.19-0ubuntu6.15_amd64.deb
sudo dpkg -i multiarch-support_2.19-0ubuntu6.15_amd64.deb依赖库安装完成后,使用如下命令从github上下载pocketsphinx功能包的源码:
git clone https://github.com/mikeferguson/pocketsphinx.git下载完成后就可以在工作空间下使用cakin_make命令编译功能包了。
pocketsphinx功能包的核心节点是recognizer.py文件。这个文件通过麦克风收集语音信息,然后调用语音识别库进行识别并生成文本信息,通过/recognizer/output消息进行发布,其他节点可以通过订阅该消息获取识别结果,并进行相应处理。
2、语音识别测试
首先,插入麦克风设备,并在系统设置里测试麦克风是否有语音输入。输入音量不能太小,也不能太大。
注:需先安装科大讯飞语音识别SDKlibmsc.so,才行。见第五节
然后,运行pocketsphinx包中的测试程序:
roslaunch pocketsphinx robocup.launch需要Python3
pocketsphinx功能包提供一种离线的语音识别模型,默认支持的模型有限,在下一节我们将学习如何添加自己的语音模型。
出现错误:SyntaxError: Missing parentheses in call to 'print'. Did you mean print(data_path)?
报错是由于Python3和Python2版本不同,print函数语法也不同造成的。这样的原因很可能是用Python3跑了Python2 的程序。所以这种问题有两种方法解决。
第一种:更换Python版本(默认ubuntu终端)
首先输入Python查看Python版本,如果是Python3,则将语句改成Python2+执行的命令即可。以古月居的程序为例
for a in range(5, 10):
if a < 10:
print 'a = ', a
a += 1
else:
break
当输入python python_for.py时报错:SyntaxError: Missing parentheses in call to 'print'. Did you mean print('a = ', a)?
当输入:python2 python_for.py时可以顺利跑出来
第二种方法:修改程序
将程序print变成print()如
for a in range(5, 10):
if a < 10:
print ('a = ', a)
a += 1
else:
break
也可以顺利跑通
建议用第二种方法,python3
出现python import错误,试试以下:
import pygtk
ModuleNotFoundError: No module named 'pygtk'
pip install --upgrade pip -vvv
pip install -U setuptoolspip install pyGObject
pip install Pygtk
pip install --upgrade PyGObject
pip install --upgrade Pygtksudo apt-get install python-gtk2-dev python-gtk2-tutorialsudo apt-get install python-gtk2sudo apt-get install libgtk2.0-devsudo apt install libgirepository1.0-dev gcc libcairo2-dev pkg-config python3-dev gir1.2-gtk-3.0pip3 install PyGObjectsudo apt install python3-gi python3-gi-cairo gir1.2-gtk-3.0pip install gtk -i https://mirror.baidu.com/pypi/simplepip install pygobject -i https://mirror.baidu.com/pypi/simplepip install pygst-0.10 -i https://mirror.baidu.com/pypi/simple主要是python版本问题
比如:commands是python2版本里的,在python3.0以上已经没有commands模块了,使用subprocess代替commands
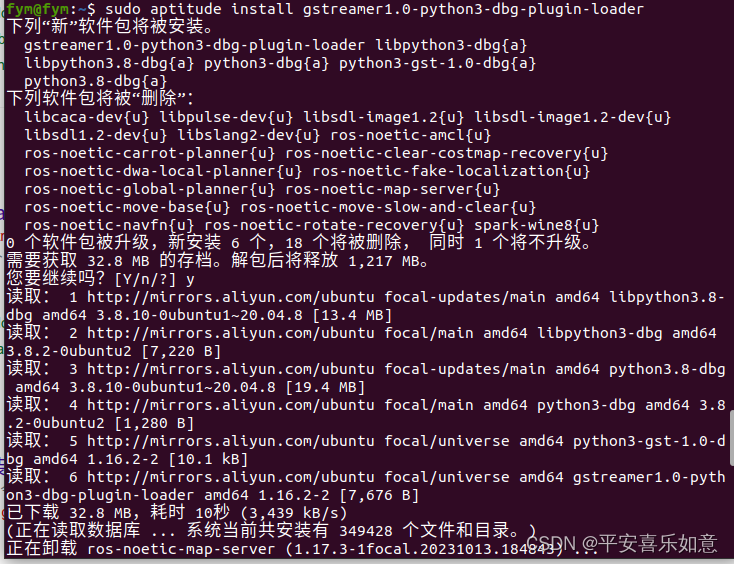
或者可以修改如图recognizer.py文件
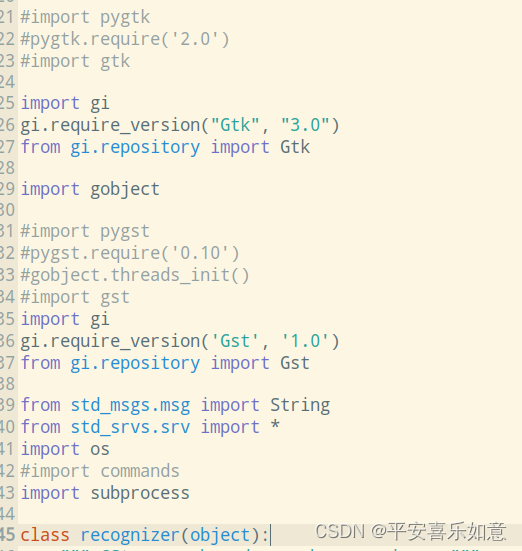
报错
gi.repository.GLib.Error: gst_parse_error: no element “gconfaudiosrc” (1)
这句是因为没有添加mic_name在robocup.launch文件,添加上就行了
请确保有麦克风(只有扬声器不行),可以在settings-sound,测试麦克风
pacmd list-sources # 显示设备列表

找到Microphone对应的device名称,我这里黄色的部分是名称
在demo/robocup.launch文件中添加mic_name,
<param name="mic_name" value="alsa_input.pci-0000_02_02.0.analog-stereo"/>
3、创建语音库
语音库中的可识别信息使用txt文档存储。在功能包robot_voice中创建一个文件夹config,用来存储语音库的相关文件。然后在该文件夹下创建一个commands.txt文件,并输入希望识别的指令,
将该文件在线生成语音信息和模板文件,这一步需要登录以下网站操作:
http://www.speech.cs.cmu.edu/tools/lmtool-new.html根据网站提示,点击“选择文件”按钮,上传刚刚创建的command.txt文件,再点击“COMPILE KNWLEDGE BASE”按钮进行编译。
编译完后,下载“COMPRESSED TARBALL”压缩文件,解压至robot_voice功能包的config文件夹下,这些解压出来的.dic、.lm文件就是根据我们设计的语音识别指令生成的语音模板库。将这些文件全部都重命名为commands。
4、创建launch文件
接下来创建一个launch文件,启动语音识别节点,并设置语音模板库的位置。robot_voice/
launch/voice_commands.launch文件
aunch文件在运行recognizer.py节点的时候使用了之前生成的语音识别库和文件参数,这样就可以使用自己的语音库来进行语音识别了,此外,这里的hmm语音引擎参数发生了变化,改为一款支持更多语音模型的引擎。
5、语音指令识别
通过以下命令测试语音识别的效果如何,尝试能否成功识别出command.txt中设置的语音指令。
roslaunch robot_voice voice_commands.launch
rostopic echo /recognizer/output6、中文语音识别
pocketsphinx功能包不仅可以识别英文语音,通过使用中文语音引擎和模型,也可以识别中文。robot_voice/config文件夹下已经包含中文语音识别的所有配置文件,使用robot_voice/
launch/chinese_recognizer.launch即可启动recognizer节点,并且链接所需要的配置文件。
使用以下命令运行该文件,即可开始中文识别:
roslaunch robot_voice chinese_recognizer.launch中文语音模型支持的识别文本可以参考pocketsphinx-cn/model/lm/zh_CN/
mandarin_notone.dic文件中的内容,里面有近十万条识别文本,几乎包含所有常用的中文词汇,所以我们可以随便说中文,通过打印出的识别结果来测试中文识别的效果:
rostopic echo /recognizer/output中文虽然可以识别,但是识别效果不佳,后面会使用科大讯飞的中文语音识别引擎实现更加准确的识别效果。
三、通过语音控制机器人
上一节实现了语音识别的基本功能,可以成功将英文语音指令识别生成对应的字符串,本节基于以上功能实现一个语音控制机器人的小应用,机器人就使用仿真环境中的小乌龟。
1、编写语音控制节点
robot_voice/script/voice_teleop.py
通过一个Subscriber订阅/recognizer/output话题;接受到语音识别的结果后进入回调函数,简单处理后通过Publisher发布控制小乌龟运动的速度控制指令。
2、语音控制小乌龟运动
接下来就可以运行这个语音控制的例程,通过以下命令启动所有节点:
roslaunch robot_voice voice_commands.launch
rosrun robot_voice voice_teleop.py
rosrun turtlesim turtlesim_node所有终端中的命令成功执行后,就可以打开小乌龟的仿真界面。然后通过语音“go”“back”“left”“right”等命令控制小乌龟的运动。
四、与机器人对话
实现一个语音对话的机器人应用。
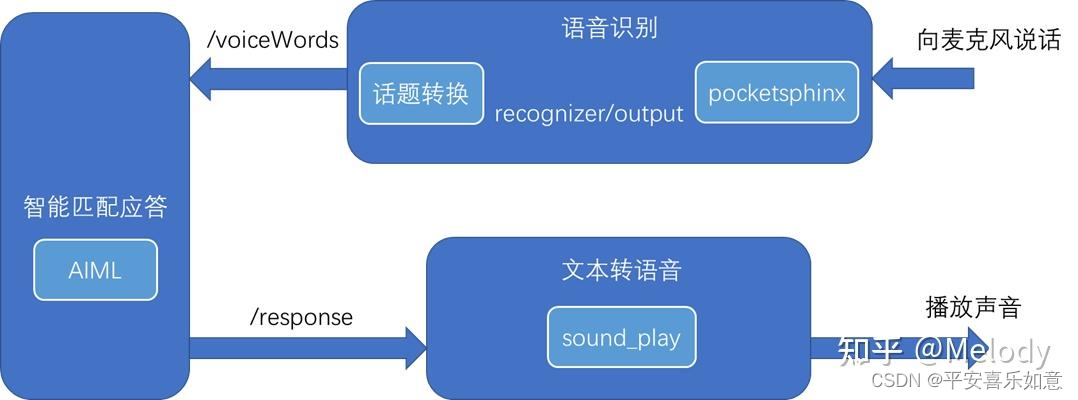
如下图所示,可以将语音对话实现的整个过程分为三个节点。
- 语音识别节点:将用户语音转换成字符串。
- 智能匹配应答节点:在数据库中匹配应答字符串。
- 文本转语音节点:将应答字符串转换成语音播放。
1、语音识别
语音识别节点基于pocketsphinx功能包。按上述方法生成一个语音库,包括以下常用的交流语句,也可以添加更多自己需要的语句。
语音库生成后,将所有库文件命名为chat,并与之前的commands文件放置到同一路径下。再创建一个launch文件robot_voice/launch/chat_recognizer.launch,运行pocketsphinx语音识别节点,并设置语音库的路径
pocketsphinx功能包将识别得到的文本使用/recognizer/output话题进行发布,所以再创建一个话题转换的节点/recognizer/srcipts/aiml_voice_recognizer.py,将语音识别结果发送到voiceWords话题。语音文本通过String类型发布,
现在就可以测试语音识别部分的功能了,在终端输入以下命令:
roslaunch robot_voice chat_recognizer.launch
rosrun robot_voice aiml_voice_recognizer.py
rostopic echo /voiceWords对着麦克风说话,可以在终端看到识别到的语音字符串。
2、智能匹配应答
语音已经可以被识别成字符串了,接下来基于AIML实现应答文本的匹配。实现节点robot_voice/scripts/aiml_voice_server.py
该节点在运行过程中需要加载AIML数据库的路径,创建robot_voice/launch/
start_aiml_server.launch进行参数加载:
在终端运行如下命令进行测试:
roslaunch robot_voice start_aiml_server.launch
rostopic echo /response
rostopic pub /voiceWords std_msgs/String "data: 'what is your name'"可以在终端看到匹配的应答信息
3、文本转语音
现在我们已经可以匹配得到应答的文本了,使用前面学习的sound_play功能包就可以把文本转换成语音播放出来。文本转语音节点的实现在robot_voice/scripts/aiml_tts.py中完成,
在终端使用以下命令进行测试:
roscore
rosrun sound_play soundplay_node.py
rosrun robot_voice aiml_tts.py
rostopic pub /response std_msgs/String "data: 'what is your name'"运行成功后,很快就可以听到“what is your name”这段文本的语音了。
4、智能对话
我们将上述三个过程集成到一起,就制作成一个完整的智能语音对话应用了。
创建robot_voice/launch/start_chat.launch文件启动以上所有节点
通过以下命令启动语音识别、智能匹配应答、文本转语音等关键节点:
$ roslaunch robot_voice chat_recognizer.launch
$ roslaunch robot_voice start_chat.launch启动成功后,就可以开始和这款机器人进行对话了。
五、让机器人听懂中文
前面的内容中,我们已经创建了一个类似于Siri的语音对话机器人,如果我们想使用中文与机器人进行交流,我们就要用到科大讯飞的语音识别SDK。
1、科大讯飞语音识别SDK
- 首先登陆科大讯飞开放平台的官网(http://www.xfyun.cn/),使用个人信息注册一个账户。
- 登录账户后,创建一个新应用,这里为应用取名为your_name_ros_voice
- 创建完成后,在“我的应用”可以看到刚刚创建完成的语音应用
- 点击,在列表中选中“语音听写”
- 接着界面会跳转到应用语音听写的数据统计界面,在界面有“SDK下载”选项,点击它,随后出现下载选项界面,默认已经根据应用的属性进行了配置,直接点击页面下方的“下载SDK”即可。
- 接下来将科大讯飞SDK的库文件拷贝到系统目录下,在后续的编译过程中才可以链接到库文件。进入SDK根目录下的libs文件夹,选择相应的平台架构,64位系统是“x64”,32位系统是“x86”,进入相应文件夹后,使用如下命令完成拷贝:我是64
sudo cp libmsc.so /usr/lib/libmsc.so科大讯飞的SDK带有ID号,每个人每次下载后的ID都不相同,更换SDK之后需要修改代码中的APPID,运行教程包的话,你需要修改一下自己下载SDK中的ID。我们需要更改里面cpp文件里面的APPID号:ctrl+f可以对其进行搜索。你也可以使用rrobot_voice/libs/x86/libmsc.so文件。
主要修改robot_voice/src/下里的APPID号
2、语音听写
要让机器人听懂我们说的中文,这个功能节点基于科大讯飞SDK中的“iat_online_record_sample”例程。将该例程中的代码拷贝到功能包robot_voice中,针对主要代码文件iat_online_record_sample进行修改,添加需要的ROS接口,修改完成后重命名文件为robot_voice/src/iat_publish.cpp
编译完成后,使用以下命令进行测试:
roscore
rosrun robot_voice iat_publish
rostopic echo /voiceWords
rostopic pub /voiceWakeup std_msgs/String "data: any 'string'"发布唤醒信号(任意字符串)后,可以看到“Start Listening...”的提示,然后就可以对着麦克风说话了,联网完成在线识别后会将结果进行发布。
3、语音合成
机器人已经具备基础听的能力,接下来让机器人具备说的功能。该功能模块基于科大讯飞SDK中的tts_sample例程,同样把示例所需的代码拷贝到功能包中,然后修改主代码文件,添加ROS接口,并重命名为robot_voice/src/tts_subscribe.cpp
main()函数中声明了一个订阅voiceWords话题的Subscriber,接受输入的语音字符串,接收成功后,在回调函数voiceWordsCallback()中使用SDK接口将字符串转换成中文语音。
然后再CMakeLists.txt中添加编译规则:
编译完成后,使用以下命令进行测试:
roscore
rosrun robot_voice tts_subscribe
rostopic pub /voiceWords std_msgs/String "data: '你好,我是机器人'"如果语音合成成功,终端会显示如下信息
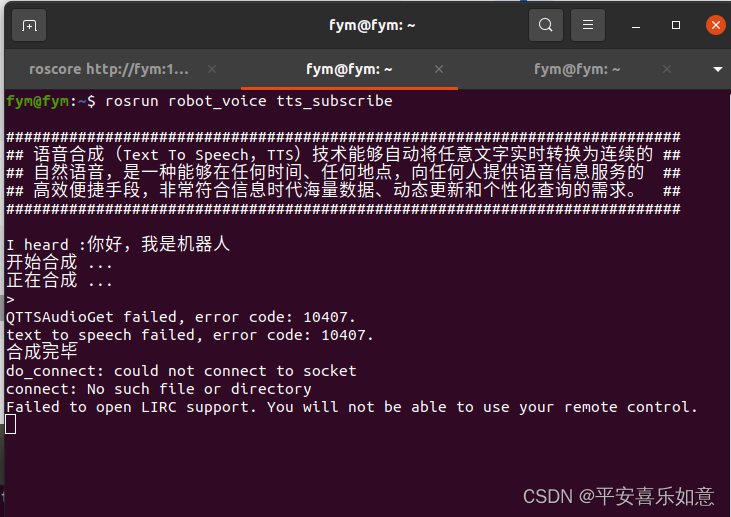
机器人用标准的普通话说出了“你好,我是机器人”这句话。这里可能会出现错误提示,但不影响语音输出效果。

这是由于mplayer配置导致的问题,解决方法是再/etc/mplayer/mplayer.conf文件中添加如下设置:
sudo gedit /etc/mplayer/mplayer.conf加入
lirc=no
另:若出现mplayer
sudo apt-get install ldb-tools
sudo apt-get install yasm
源码安装mplayer
若出现AO OSS /dev/dsp问题
则
sudo gedit ~/.mplayer/config写入
ao=alsa
4、智能语音助手
现在机器人已经会听说了,但还没有智能化的数据处理能力,下面我们可以在以上代码的基础上添加一些数据处理,赋予机器人简单的智能,让机器人可以进行简单的中文对话。
我们可以在tts_subscribe.cpp代码的基础上进行修改。在voiceWordsCallback()回调函数中添加一些功能代码,并命名为robot_voice/src/voice_assistant.cpp
在以上代码中,添加了一系列if、else语句来判断中文语音输入的含义,当我们说出“你是谁”“你可以做什么”“现在时间”等问题时,机器人可以获取系统当前时间,并且回答我们的问题。
然后再CMakeLists.txt中添加编译规则:
编译完成后,使用如下命令进行测试:
roscore
rosrun robot_voice iat_publish
rosrun robot_voice voice_assistant
rostopic pub /voiceWakeup std_msgs/String "data: 'any string'"语音唤醒后,我们就可以向机器人发问了。
这里仅以中文语音交互为例实现了一个非常简单的机器人语音应用,重点是学习科大讯飞SDK与ROS系统的集成,以辅助我们实现更为复杂的机器语音功能。
六、人工智能标记语言
人工标记语言(Artificial Intelligence Markup Language,AIML)是一种创建自然语言处理软件代理的XML语言。AIML主要用于实现机器人的语言交流功能,用户可以与机器人说话,而机器人可以通过一个自然语言的软件代理,也可以给出一个聪明的回答。
Python有针对AIML的开源解析模块——PyAIML,该模块可以通过扫描AIML文件建立一颗定向模式树,然后通过深度搜索来匹配用户的输入。首先对该模块进行简单介绍。
sudo apt-get install python-aiml检查是否安装成功:
cd /path_to/robot_voice/data
python3
>>> import aiml若无报错,则说明安装成功。
我是用的这个
pip install python-aimlpython-aiml-0.9.3.zip (2.1 MB)版本

不好下的话,可以添加镜像源:
sudo pip install -r tools/pip-requires -i https://mirrors.aliyun.com/pypi/simple
AIML原本不支持中文,程序员yaleimeng(https://github.com/yaleimeng)移植到中文语境上。可以直接到他的仓库(https://github.com/yaleimeng/py3Aiml_Chinese)里git下来,该项目运行于python3环境。不需要安装,把源码放到项目目录下即可运行。
pip install python-aiml 0.9.1版本,核心代码可用。可使用英文模板库
pip install aiml 不能直接用。但带有Alice的英文模板库。
查找相关资源可以:pip search aiml
众所周知,python2的文字编码问题是个万人坑,所以py3是文字处理的最佳选择。所以通读支持中文的py2版本aiml整个项目之后,着手进行py3.
显示错误:
显示//usr/bin/env: “python”: 没有那个文件或目录
解决:
要么没有安装Python,安装Python3.8
sudo apt-get install python3.8如果安装了Python3.8,则配置Python软连接:
#找Python3.8位置
whereis python3.8 #配置软连接
cd /usr/bin
ln -s /usr/bin/python3.8 python🕕refrence: ROS进阶(四):机器语音项目实战 - 知乎
七、本章小节
通过本章学习,我们了解了以下内容:
- pocketsphinx功能包:用于实现英文语音的识别。
- sound_play功能包:用于实现英文字符语音的功能。
- 人工智能标记语言(AIML):用于实现机器人的语言交流功能。
- 科大讯飞SDK:中文语音识别、合成的重要开发工具。

















 1409
1409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









