








目录
摘要
较低的时间响应、较高的模型泛化性
在本文中,针对强化学习+车间调度,提出以下内容:
- 2种仿真技术;
- 2种常用架构;
- 现存方法的挑战;
- 介绍直接调度、基于特征表示的调度、以及基于参数搜索的调度;
关键字
- 强化学习应用;
- 车间调度;
- 图神经网络;
- 组合优化;
- 深度学习;
- 特征表示
引言
多数的车间调度问题属于NP完全问题,无法在多项式时间内获得全局最优解
传统方法:优点——局部最优解、较高准确度;缺点——时间响应、泛化性难以达到要求
强化学习应用在车间调度上的困难:
- 系统状态难以定义:定义不好会导致算法不好。
- 动作和奖励函数的设计:设计不好难以收敛学习。
- 哪种强化学习算法适合解决问题:选择不当导致准确度不同。
1 背景
1.1 车间调度问题
很多实际资源分配和调度问题的抽象模型
1.1.1 车间调度问题建模
- n n n 个元件,每个编号记为 i i i,其中 i = 1 , 2 , 3... n i=1,2,3...n i=1,2,3...n。
- 每个工件 i i i 具有 m m m 个有顺序的加工次序。
- 共有 m m m 台机器,每时刻每台机器只能加工 1 1 1 个。
目标:确定每台机器的工件加工顺序和每个工序的具体开工时间,以使得所有工件的总加工完成时间最短。公式表示。
L
=
min
(
max
1
<
i
<
n
C
i
)
L=\min(\max\limits_{1<i<n}C_{i})
L=min(1<i<nmaxCi)
其中
C
i
C_{i}
Ci 为工件
i
i
i 从开始加工到最后加工完毕所用的全部时间,包括了加工时间和等待时间。也就是找出这
n
n
n 个工件中时间最长的是哪个,对这个工件优化使得时间减小。
几种常见的车间调度问题:

1.1.2 仿真技术在车间调度问题中的应用
如何搭建高效、可信的仿真环境?
两种方法:
- 元胞自动机。
将机器、加工资源等制造车间元素建模为网络空间的固定格点
将加工的工件作为移动粒子 - 离散事件仿真方法。
将车间调度过程中生产环境的变化作为事件转移触发条件,并以此驱动整个工件加工的动态过程。
是主流方法。降低了计算机的运算复杂度,易于编程或建模实现。
1.1.3 车间调度问题的传统解决算法
两种方法:
- 规则式方法。
基于简单规则安排工件的调度顺序。
又称优先调度规则(Priority Dispatch Rules, PDR)
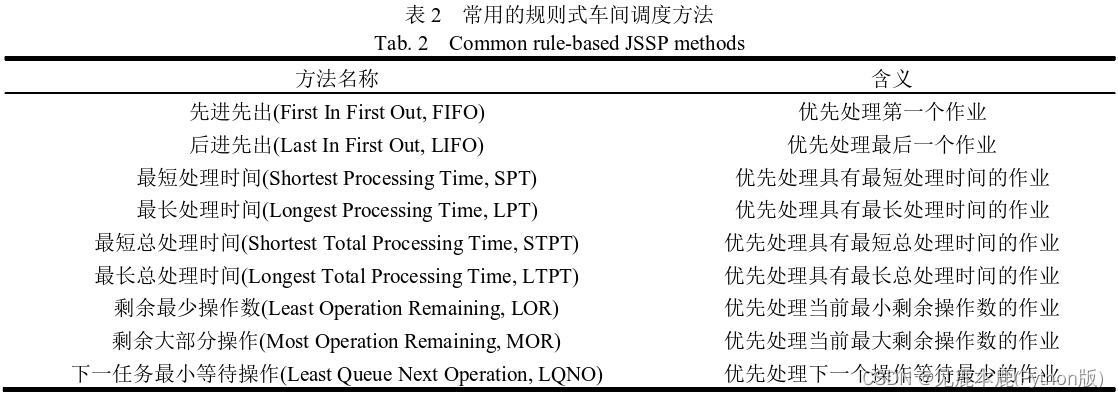
时间响应低,泛化性较高,部分问题准度高 - 元启发式方法。
通过不同的优化迭代算子在车间调度问题上搜索得到局部最优解
准度高于规则式方法
劣势:计算量大、无法进行预训练,导致时间响应差;不同问题分别调参,泛化性差。

1.2 强化学习问题
1.2.1 基本概念与定义
介绍了MDP和Q学习
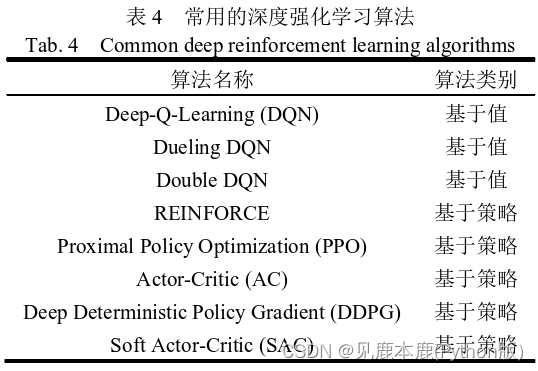
1.2.2 深度强化学习
具体而言,深度强化学习主要使用神经网络拟合2个变量,分别是值函数与策略,以此形成的2个主要的深度强化学习分支,即基于值与基于策略的算法。
2 两种主要的强化学习调度结构
利用智能体的决策能力
调度环境发生状态转移时为所有工件安排合理的加工次序
2.1 单智能体架构
将所有待加工工件的整体看作一个智能体
状态:所有工件的当前状态集合以及环境的全局状态
动作:所有工件下一步的调度动作集合
| 优点 | 缺点 |
|---|---|
| 收敛性好,易于搭建。 | 缺失工件之间的信息传输,具有信息损失;受到神经网络制约,动作输出仅保持在2维左右。 |
2.2 多智能体架构
每一个工件看作一个单独的智能体
状态:每个工件智能体以当前自身的状态及相对应的环境状态
动作:下一步各自动作
| 优点 | 缺点 |
|---|---|
| 能更加细节、更全面处理工件的信息 | 模型难收敛、多智能体之间资源冲突、环境编写困难 |
3 强化学习车间调度算法简述
3.1 直接调度
状态:直接利用调度环境产生的实时输出。比如:当前待加工工件数、工件排队时长。实现深度强化学习算法与调度环境的直接耦合。
面临的挑战:
- 状态的有效定义;
- 如何提取状态之间的隐形关系;
3.2 基于特征表示的调度
基于深度学习中的图神经网络(Graph Neural Network, GNN)、指针网络、以及注意力机制。
构建传统控制做底层,强化学习做规划,深度学习做感知的3层调度模型。
- 图神经网络:表示复杂可变的调度环境时具有很大优势
- 遗传算法等集中式优化算法:计算复杂度会随着问题规模的扩大而增加,当环境变化时需要重新计算
- 图卷积网络:充分提取调度环境的特征,整个调度模型的计算效率和训练稳定性会随着图结构的复杂而降低
优点:高响应、高泛化
缺点:低准度
3.3 基于参数搜索的调度
将元启发式算法与强化学习相结合
使用强化学习训练出元启发式算法在不同情况下的参数配置
提高元启发式算法的泛化性
缺点:调度结果依然受限于元启发式算法的非动态、响应时间长的问题;参数调节依然受限于强化学习。
3.4 三类强化学习调度算法的对比



















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











