









 本文介绍了GraphCL,一种针对图数据的自监督学习框架,提出四种增强方式并分析其在不同数据集上的适用性。实验表明,GraphCL在各种学习任务中表现出色,同时增强了模型对对抗性攻击的抵抗力。关键贡献在于对数据增强策略的深入理解和实用性评估。
本文介绍了GraphCL,一种针对图数据的自监督学习框架,提出四种增强方式并分析其在不同数据集上的适用性。实验表明,GraphCL在各种学习任务中表现出色,同时增强了模型对对抗性攻击的抵抗力。关键贡献在于对数据增强策略的深入理解和实用性评估。
Graph Contrastive Learning with Augmentations 论文解析
往期相关推送(持续更新中!):
[ICASSP 2024] CDNMF: 一个可信且高效的社区检测(社区发现,图聚类,Community Detection)方法-CSDN博客
[论文分享] DGI 图对比学习:局部-全局对比,最大化互信息-CSDN博客
Motivation
· 对于图数据集来说,同样存在缺少标签或难以标注的问题,而预训练(自监督学习)是一种可行的解决方案。只是在这一方面的研究比较少。
· 对比学习是一种通过在不同增强视图下最大化特征一致性的自监督学习方法,具有良好的表示能力,在图像表示学习方面取得了显著的成效。而图是一种复杂的离散数据结构,难以直接套用已有的模型。
Contributions
· 首次提出了图结构的四种增强方式。
· 构建了适用于图数据的通用对比学习框架GraphCL,比较了不同增强在不同数据集上的适用性并作了分析。
· GraphCL在半监督学习、无监督表示学习和迁移学习的实验中取得了最先进的性能。此外,它还增强了对抗性攻击的鲁棒性。
Proposed Method
和一般的对比学习类似,分为三部分:augmentation、representation、contrast
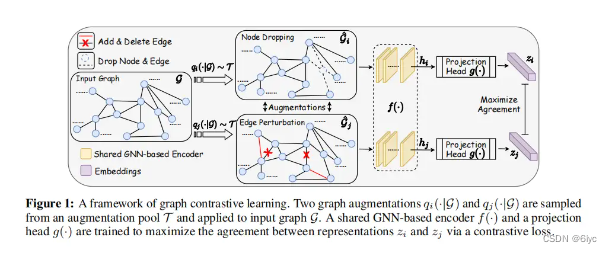
· 图增强方式以及需要的先验信息

必要的先验信息:例如丢失部分顶点和边不会影响图的语义。
· 一个基于GNN的编码器(shared)提取图级表示向量
· 对比:正例互信息最大化(分子),负例互信息最小化(分母)
第n个图的NT-Xent:
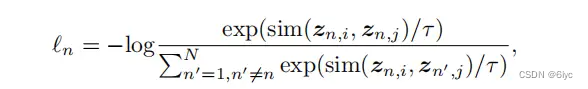
注:
1、这里的Projection head g(·)一般取MLP,其可以提升模型的性能(ACC)。
在文章A Simple Framework for Contrastive Learning of Visual Representations 中,作者实验验证了该结论。
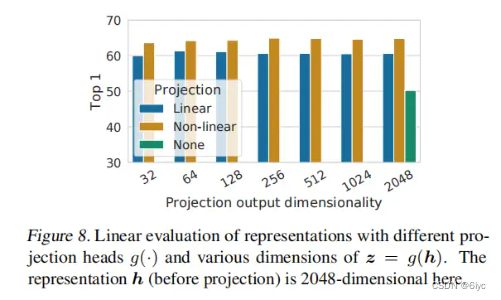
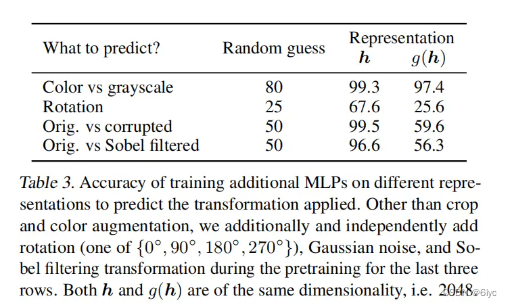
2、其次,在下游任务中所使用的representation是取Projection head之前的,这是因为经历了Projection head(MLP)之后,representation损失了部分利于下游任务的信息,导致模型准确率下降。
Experiments
· 与当前最先进的模型的性能比较
半监督学习:
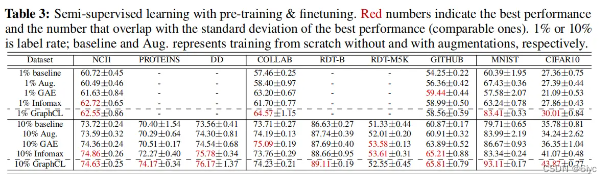
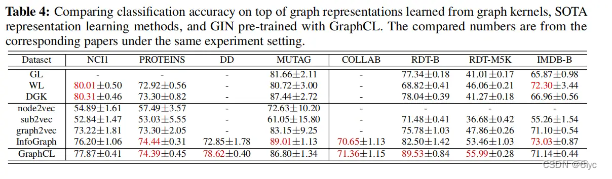
无监督学习,下游任务:分类
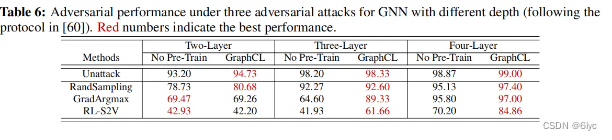
· 对比学习框架提升了模型的鲁棒性
Conclusions:
· 该文不仅提出了一个图对比学习框架GraphCL,重点还在于其通过实验,系统地分析了数据增强的影响,揭示了增强的基本原理以及指导了增强的选择。
(1)数据增强的必要性
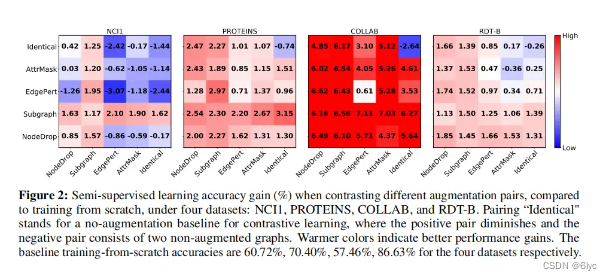
(2)不同增强在不同数据集上的适用性
比如,边缘扰动(一种增强)适用于社交网络数据集,不适于生物、化学分子数据。直观来说,一个生化分子损失某些边后,其性质或类型可能发生巨大改变,这不满足语义鲁棒性的先验条件。相对而言,社交网络的语义对边的变化不敏感。
无论增强强度如何,边缘扰动都会恶化NCI1(biomolecule data)的性能。
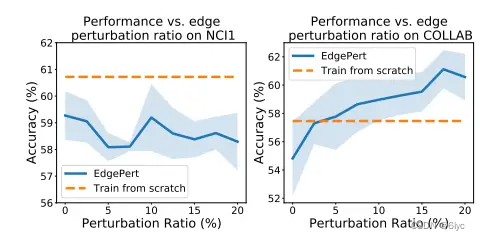
· 从论文中也不难看出,要经过大量实验,才能对给定的图数据选出合适的数据增强方式(组合)以及增强强度。而且,某些增强方式会破坏图的语义结构,反而降低下游任务的性能。这时,不妨考虑通过学习的方式自动从数据集中提取出合适的增强方式。
Reference
[0] You Y, Chen T, Sui Y, et al. Graph contrastive learning with augmentations[J]. Advances in neural information processing systems, 2020, 33: 5812-5823.
[1] Li Y, Chen J, Chen C, et al. Contrastive Deep Nonnegative Matrix Factorization for Community Detection[J]. arXiv preprint arXiv:2311.02357, 2023.
[2] Li Y, Hu Y, Fu L, et al. Community-Aware Efficient Graph Contrastive Learning via Personalized Self-Training[J]. arXiv preprint arXiv:2311.11073, 2023.


















 2940
2940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











