







图预训练自监督:Strategies for Pre-training Graph Neural Networks(GINEConv)
主要参考文章:https://zhuanlan.zhihu.com/p/475998142
做了很小很小的修改
0. ABSTRACT
少训练集对于一些特定机器学习任务是一个挑战,不过通过预训练(在数据丰富的情况下对相关任务的模型进行预训练,然后对感兴趣的下游任务进行微调)的方法,version和language领域已经有效解决了这一问题,但对于图数据集,仍是悬而未决的。本文提出了一种新的用于GNNs预训练的自监督方法。该方法成功的关键在于:同时在单节点和全图的层级上预训练以获得一个同时学习了局部和全局表现的富有表现力的GNN。团队系统的研究了大量图分类数据集的预训练,一些初始策略仅在单节点或全图层级预训练,导致了在下游任务中出现负迁移(negative transfer)。而本文工作则避免了负迁移且提高了模型的泛化能力,相对于未预训的模型,ROC-AUC(衡量算法性能的指标,具体见
1. INTRODUCTION
迁移学习(Transfer learning)指的是一个初始时在一些任务上训练,之后重新目的化到不同但相关的任务上的模型。深度迁移学习(Deep transfer learning)在计算机视觉和自然语言处理上已证明是一个有效的迁移学习方法,但推广到图数据的预训练的研究仍然很少。
图数据的预训练在下述2个基本挑战上具有潜力:
- 特定任务的标签数据可能极其稀缺。这一问题在科学研究领域的重要图数据上更加严重,如:化学、生物;
- 现实世界的图数据总是包含out-of-distribution(=Non-I.I.D.。相对I.I.D.假设下的模型学习,训练环境和测试环境的数据分布不同的问题称为Non-I.I.D.或者OOD)的样本(OOD样本也叫异常样本:outlier,abnorma,即训练集中的图数据在结构上和测试集的相异)。Out-of-distribution预测的一个例子是:当想预测一个全新的、刚合成的分子(和以前合成的所有分子都不同)的性质,其和训练集的所有分子都是不同的。
不过,图数据集上的预训练还面临着严重的挑战。一些关键研究指出:成功的迁移学习不仅仅是增加和下游任务同领域的标签过的预训练数据集的数量,相反,其需要大量的邻域专业知识去仔细选择与感兴趣的下游任务有关的样本和目标标签。此外,将知识从相关的预训练任务转移到新的下游任务可能是不利于泛化的,即负迁移。
Present work
文章将重点放在:将预训练作为”用于graph-level性质预测的图神经网络“中迁移学习的一种方法。本位工作的两大关键贡献是:
- 进行了首次系统的对预训练GNN策略的大规模科学调查。为此,团队新建了2个大型的预训练数据集并与社区共享。团队还发现,大型数据集对于研究特定领域的预训练至关重要,现有的下游任务基准数据集太小,无法以统计学上可靠的方式评估模型;
- 开发了一种有效的GNN预训练策略,并证明了该策略在难迁移学习问题上out-of-distribution泛化的有效性和能力。
原始的预训练策略可能在很多下游任务上都会导致负迁移,或一个看起来强劲的预训练策略可能只带来了marginal performance提升【补充1:这里有两种译法:a. 微小的性能提升; b.边际性能提升。个人倾向后一种。结合概率论中边缘分布(Marginal Distribution)的概念,i.可能指只带来了有限方面的性能提升; ii. 可能指上/下界性能的提升。还可参考“Predicting the Generalization Gap in Deep Networks with Margin Distributions”[5]一文和博客[6]理解】。
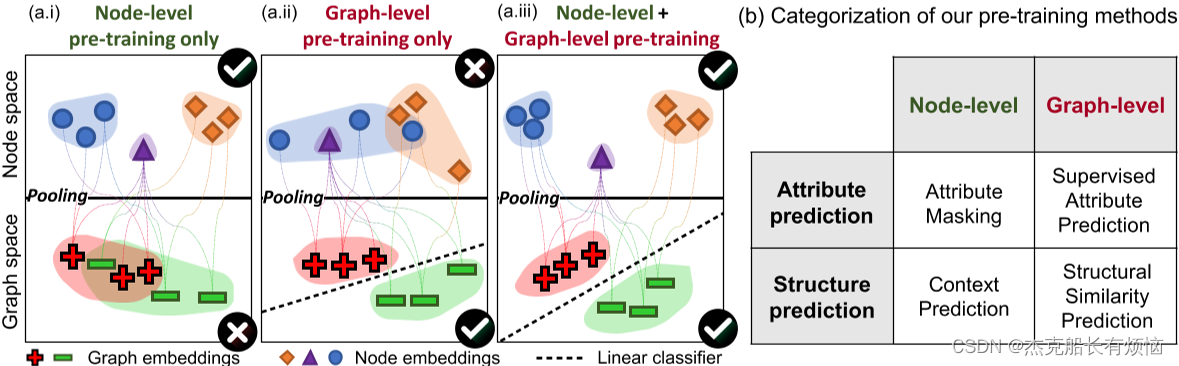
图1:(a.i)当只使用节点级预训练时,不同形状的节点(语义上不同的节点)可以很好地分离,然而,节点嵌入是不可组合的,因此池化节点级嵌入创建的图嵌入(由它们的类表示,+和-)是不可分离的。(a.ii)仅使用图级预训练,图嵌入被很好地分离,然而单个节点的嵌入不一定捕获其特定领域的语义。(a.iii)高质量的节点嵌入是指不同类型的节点能够很好地分离,同时嵌入空间也具有可组合性。这允许对整个图进行准确和健壮的表示,并支持将预先训练的模型健壮地转移到各种下游任务。(b) gnn训练前方法分类。至关重要的是,我们的方法,即上下文预测、属性掩蔽和图级监督训练前(监督属性预测),都可以实现节点级和图级的监督训练前。
本文策略的关键思想是使用易于访问的node-level信息,并鼓励GNN获取关于节点和边的特定领域知识以及graph-level知识。这有助于GNN在全局和局部层级学习有用的表示(图1(a.iii)),并且能够生成对各种下游任务(图1)都鲁棒和可迁移的graph-level表示(通过池化节点表示获得)至关重要。图1(a.i)和图1(a.ii)给出了只利用node-level属性和graph-level属性的初始策略,以与本文策略形成对照。
本文的预训练策略与最富表现力的GNN结构:GIN一起使用,在基准数据集上取得了SOTA的结果表现同时避免了负迁移。另外,团队发现GIN在预训练的收益要比其他表现力较差的模型如GCN,GraphSAGE和GAT等等要多,且预训练的GNN在调参阶段的训练和收敛速度要高出一个量级(orders-of-magnitude faster)。
2. PRELIMINARIES OF GRAPH NEURAL NETWORKS 预备知识
Supervised learning of graphs
- G = ( V , E ) G=(V,E) G=(V,E)表示一个图, V 为节点集, E 为边集;
- X v X_v Xv表示节点属性, v ∈ V ; e u v v∈V ; e_{uv} v∈V;euv表示边属性, ( u , v ) ∈ E (u,v)∈E (u,v)∈E ;
- 给定图集合 G 1 , . . . , G N {G_1,...,G_N} G1,...,GN 和对应标签 y 1 , . . . , y N {y_1,...,y_N} y1,...,yN ,图监督学习的任务是学习图的向量表示 h G h_G hG 来帮助预测图 G G G的标签,其中 y G = g ( h G ) y_G=g(h_G) yG=g(hG)
- 例如:对于分子属性预测, G 就是分子图,其中节点表示原子,边表示化学键,标签可以为毒性或者酶结合。
Graph Neural Networks (GNNs)
- GNN使用图的连通性(度)和节点、边的属性,对每个节点 v ∈ G v∈G v∈G 学习一个表示向量(如:embedding) h v h_v hv,对每个每个整图 G G G 学习一个向量 h G h_G hG ;
- 现在GNNs使用一种领域聚合的方法,即:通过聚合 v v v 的邻居节点和边的表示迭代更新节点 v v v 的表示;
- k k k次聚合迭代后, v v v 的表示(representation)捕获了网络内 k-hop 邻居的结构信息;
- 第 k 层GNN定义如下: h v ( k ) = C O M B I N E ( K ) ( h v ( k − 1 ) , A G G R E G A T E ( k ) ( ( h v ( k − 1 ) , h u ( k − 1 ) , e u v ) : u ∈ N v ) ) h_v^{(k)}=COMBINE^{(K)}(h_v^{(k−1)},AGGREGATE^{(k)}({(h_v^{(k−1)},h_u^{(k−1)},e_{uv}):u∈N_v})) hv(k)=COMBINE(K)(hv(k−1),AGGREGATE(k)((hv(k−1),hu(k−1),euv):u∈Nv)) ,其中 h v ( k ) h_v^{(k)} hv(k)是节点 v v v在第K次迭代/层的表示, e u v e_{uv} euv 是 u 和 v 间边的特征向量, N ( v ) 是 v N(v) 是 v N(v)是v 的邻居集;
- 初始化 h v ( 0 ) = X v h_v^{(0)}=X_v hv(0)=Xv 。
Graph representation learning
- 为获取整图的表示 h G h_G hG, R E A D O U T READOUT READOUT函数将最后一次迭代 K K K 的节点特征池化: $h_G=READOUT(h_v^{(K)}|v∈G) ,其中 ,其中 ,其中 READOUT 是一个 是一个 是一个permutation-invariant$(特征之间没有空间位置关系,这里可以理解为不随输入排序变化而改变的)函数,比如取均值或更先进的graph-level池化函数。
3. STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORKS
本文预训练策略的技术核心是在独立节点和全图级别上预训练GNN这一概念。该概念鼓励GNN在两个级别捕获特定领域的语义,如图1(a.iii)所示。
3.1 NODE-LEVEL PRE-TRAINING
对于node-level的预训练,本文方法是用那些容易获得的无标签数据来捕捉特定领域的知识与规律。本文提出了两个自监督方法:Context Prediction和Attribute Masking。
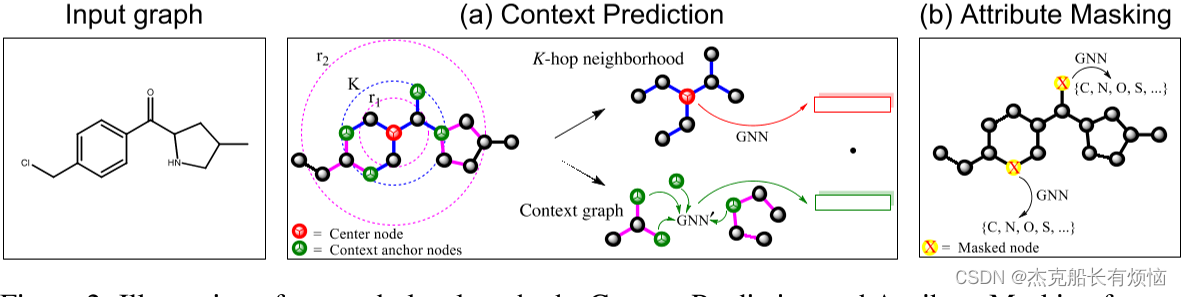
图2:我们对预训练gnn的节点级方法、上下文预测和属性屏蔽的说明。(a)在Context Prediction中,子图是选定中心节点周围的K-hop邻域,其中K为GNN层数,在图中设为2。上下文被定义为从中心节点(图中我们用 r 1 = 1 , r 2 = 4 r_1 = 1, r_2 = 4 r1=1,r2=4)到 r 1 − 和 r 2 − h o p r_1-和r_2-hop r1−和r2−hop之间的周围图结构。(b) Attribute Masking对输入的节点/边属性(如分子图中的原子类型)进行随机屏蔽,并要求GNN对其进行预测。
3.1.1 CONTEXT PREDICTION: EXPLOITING DISTRIBUTION OF GRAPH STRUCTURE 上下文预测
上下文预测中,本文使用子图来预测其周围图结构。目标是训练一个将出现在类似结构上下文的节点映射到相近的embeddings的GNN。
Neighborhood and context graphs 邻居和上下文图
对每个节点 v v v ,如下定义 v v v 的邻居和上下文图:
- 邻居: v v v 的 K − h o p K−hop K−hop 邻域包含图内距离 v v v 节点 K − h o p K-hop K−hop 的所有节点和边(这是由于 K 层GNN聚合了 v v v的 $K $阶邻域的信息,因此节点向量映射 h v ( K ) h_v^{(K)} hv(K) 依赖于距离 v 最多 K v 最多 K v最多K 跳的所有节点);
- **上下文图:**围绕 v v v邻居的图结构。上下文图通过两个超参数 r 1 , r 2 r_1,r_2 r1,r2 描述,其代表一个介于距离 v v v 节点 r 1 − h o p 至 r 2 − h o p r_1-hop 至 r_2-hop r1−hop至r2−hop 的子图(即一个宽度为 r 2 − r 1 r_2−r_1 r2−r1 的环)。
邻居和上下文图举例如上图2。我们要求 r 1 < K r_1<K r1<K 那么邻域和上下文本图才有共享的节点,文章将这些节点定义为上下文锚节点(context anchor nodes)。这些锚节点描述了邻居和上下文图是如何相互连接的。【对比图2(a)可得锚节点节点是距离 v 节点 K − h o p v 节点 K-hop v节点K−hop 的节点】
Encoding context into a fixed vector using an auxiliary GNN 使用辅助GNN将上下文编码到一个固定向量
由于图的combinatorial nature,直接预测上下文图是比较棘手的,这有别于NLP中单词都源于定长、有限的词表。【combinatorial nature,直译为组合特性。由于离散数学是广义的组合数学(Combinatorial mathematics,图论是组合数学的一个分支),所以这里combinatorial nature应该意为离散特性:度、拓扑结构…而有别于NLP猜测是指图数据的结构是多样的、不确定的而不是像nlp中词源固定有限的?】
为实现上下文预测,文章将上下文图encode编码为一个固定长度的向量。为实现这个目的,团队使用一个辅助GNN,记为**context GNN。**如上图2描绘,首先应用context GNN(图2(a)中记为GNN’)获取节点在context graph中的embedding向量映射。然后对context anchor nodes的embeddings取平均来获得一个固定长度的context embedding。对于图 G G G 中的节点 v v v ,其context embedding表示为 c v G c_v^G cvG 。
Learning via negative sampling 通过负采样学习
团队使用负采样(不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的来同时学习main GNN和context GNN。main GNN对邻域neighborhoods进行编码以获得节点的向量映射),context GNN对上下文本图context graph进行编码以获得上下文的向量映射。特别是,Context Prediction上下文预测的学习目标是对特定的邻域和特定的上下文图是否属于同一个节点进行二元分类:
σ ( h v ( K ) ⊤ c v ′ G ′ ) ≈ 1 { v 和 v ′是相同的节点 } σ(h_v^{(K)⊤}c_{v′}^{G′})≈1\{v 和 v′是相同的节点\} σ(hv(K)⊤cv′G′)≈1{v和v′是相同的节点}
- σ ( ⋅ ) σ(⋅) σ(⋅)是sigmoid函数;
- 1 ⋅ 1{⋅} 1⋅是指示函数(这里的意思为:若 v 和 v′ 是相同节点,则上式右侧输出1,否则输出0);
- 正样本对(positive neighborhood-context pair): v = v ′ , G = G ′ v=v^′,G=G^′ v=v′,G=G′;
- 负样本对(negative neighborhood-context pair): G ≠ G ′ ,即从随机抽选的 G ′ 中随机采样一个节点 v ′ ; G≠G^′,即从随机抽选的G^′中随机采样一个节点v^′; G=G′,即从随机抽选的G′中随机采样一个节点v′;
- 原文:We either let v′ = v andG′ = G (i.e., a positive neighborhood-context pair), or we randomly sample v′ from a randomly chosen graph G′ (i.e., a negative neighborhood-context pair);
- 负采样率为1,即正负样本数量相等,使用负对数似然函数作为损失函数。
通过预训练,main GNN被保留位pre-trained模型。
3.1.2 ATTRIBUTE MASKING: EXPLOITING DISTRIBUTION OF GRAPH ATTRIBUTES 属性掩盖
在属性遮掩中,团队意在抓取领域知识通过学习分布在图结构中的节点/边属性的规律。
Masking node and edges attributes 遮掩节点和变动属性
Attribute Masking属性遮掩预训练工作如下:
- 掩盖节点/边的属性;
- 使用GNNs通过邻域结构预测这些属性(图2(b)为该方法在分子图上的应用);
- 明确来说,该方法通过随机将输入节点/边的属性用特殊的遮罩指示器(masked indicators,类比Bert中的mask token)替代来遮掩mask输入节点/边的属性(如:分子图中的原子类型);
- 最后将线性模型应用在embeddings上来预测masked被遮掩的节点/边的属性(a linear model is applied on top of embeddings to predict a masked node/edge attribute)。有别于*”BERT: Pre-training of deep bidirectional transformers for language understanding“(Devlin et al. 2019)*中在句子上进行操作并将消息传递应用在符号的全连接图,本文工作是在非全连接图上操作的,并意在抓取分布在不同图结构上的节点/边属性的规律;
- Furthermore, we allow masking edge attributes, going beyond masking node attributes.
上述的节点/边属性遮蔽方法对于有丰富注释的科学领域的图特别有效:
- 分子图中:原子类型对应节点属性。通过抓取它们如何在图上分布来训练GNN使之能学习简单的化学规则,如:价(原子价、化合价)或更复杂的化学现象,如官能团(羟基、羧基、醚键、醛基等决定有机化合物的化学性质的原子或原子团)的电子或空间性质;
- 蛋白质相互作用(PPI)图中:边属性对应一对蛋白质间不同类型的相互作用。捕获这些属性在PPI图中是如何分布的使得GNN学习到不同的相互作用是如何关联和互相对应的。
3.2 GRAPH-LEVEL PRE-TRAINING
此部分目的是预训练GNN以生成通过3.1方法获得的有意义的节点嵌入组成的有用的图嵌入。目标是确保节点和图嵌入都是高质量的,那么图嵌入在下游任务中是就是鲁棒的和可迁移的(如图1(a.iii)所示)。此外,如图1(b)所示,图级预训练有两个选项:(1)预测整个图的领域特定属性(例如,监督标签);(2)预测图结构。
3.2.1 SUPERVISED GRAPH-LEVEL PROPERTY PREDICTION 属性预测
由于graph-level表示 h G h_G hG是直接用于下游预测任务的微调的,所以将领域特定信息直接编码到 h G h_G hG 中是可取的。
通过定义有监督的graph-level预测任务,我们将graph-level领域特定知识添加到预训练的向量映射中。团队具体是使用图级别多任务有监督预训练来联合预测单个图的一组不同的监督标签。例如:在分子性质预测中,我们可以预训练GNN来预测到目前为止实验测量到的分子的所有性质;蛋白质功能预测中,目标是预测一个给定的蛋白质是否具有给定的功能,我们对GNN进行预训练以预测目前已被验证的多种蛋白质功能的存在性。为了联合预测多个图属性,且每个属性都对应于一个二分类任务,团队在图表示上应用了线性分类器。
重要的是,仅单独执行大量的多任务图级别预训练可能无法提供可迁移的图级表示graph-level representations,如第5节中的实证证明。这是因为一些有监督的训练预任务可能与感兴趣的下游任务无关,甚至会损害下游表现(负迁移)。一种解决方案是选择“真正相关的”有监督预训练任务并只在这些任务上预训练GNN。然而,这样的解决方案是非常昂贵的,因为选择相关的任务需要大量的领域专业知识,并且需要对不同的下游任务分别进行预训练。
为了缓解这一问题,团队提出对多任务有监督预训练只提供图级别的监督。因此,创建图级嵌入的局部节点嵌入可能没有意义,如图1(a.ii)所示。这种无用的节点嵌入会加剧负迁移问题,因为许多不同的训练前任务在节点嵌入空间中更容易相互干扰。基于此,团队的预训练策略是,在进行图级预训练之前,首先通过3.1节中描述的节点级预训练方法,在单个节点级对GNN进行正则化。正如下文实证研究那样,在没有专业挑选的有监督预训练任务的情况下,该组合策略产生了更可迁移的图表示,并鲁棒地提高了下游性能。
3.2.2 STRUCTURAL SIMILARITY PREDICTION 结构相似度预测
第二种方法是定义一个图级预测任务,目标是对两个图的结构相似性进行建模。此类任务的示例包括建模图编辑距离【图编辑距离(GED)是成对图的一种常用的相似度度量方法,也指从源图到目标图的编辑路径的恢复】或预测图结构相似性。然而,找到ground truth graph distance值是一个困难的问题【ground truth抽象含义为真值、真实的有效值】,并且在大数据集中有一个二次数的图对(quadratic number of graph pairs)要考虑。因此,虽然这种类型的预训练也是很自然的,但它超出了本文的范围,故将其研究留给未来的工作。
3.3 OVERVIEW: PRE-TRAINING GNNS AND FINE-TUNING FOR DOWNSTREAM TASKS
总而言之,本文的预训练策略是首先执行节点级自监督预训练(第3.1节),然后执行图级多任务监督预训练(第3.2节)。当GNN预训练完成后,我们对下游任务的预训练GNN模型进行微调。具体来说,我们在图级表示的基础上添加线性分类器来预测下游图标签。完整模型(即预先训练的GNN和下游线性分类器)随后以端到端的方式进行微调。该预训练方法在GNNs中产生的前向计算开销很小。
4. FURTHER RELATED WORK
使用无监督的方法学习图节点的方法表示大致可分为两类:
(1)使用基于局部随机游走的对象和通过预测边是否存在等重建图邻接矩阵的方法:
前者:
- node2vec: Scalable feature learning for networks
- Deepwalk: Online learning of social representations
- Line: Large-scale information network embedding
后者:
- Inductive representation learning on large graphs
- Variational graph auto-encoders
(2)Deep Graph Infomax,最大化局部节点表示和池化后全局图的表示之间的交互信息,训练得到节点编码器:
- Deep graph infomax
最近的一些研究也探讨了节点嵌入如何跨任务进行泛化:
- Mol2vec: unsupervised machine learning approach with chemical intuition
- Distributed representation of chemical fragments
- subgraph2vec: Learning distributed representations of rooted sub-graphs from large graphs
5. EXPERIMENTS
实验任务:图分类(图级别的属性预测)
对比方法:将本文的预训练策略和两种原先的基线策略进行比较:(i)在相关图级任务上进行大量有监督多任务预训练,(ii)节点级自监督预训练。
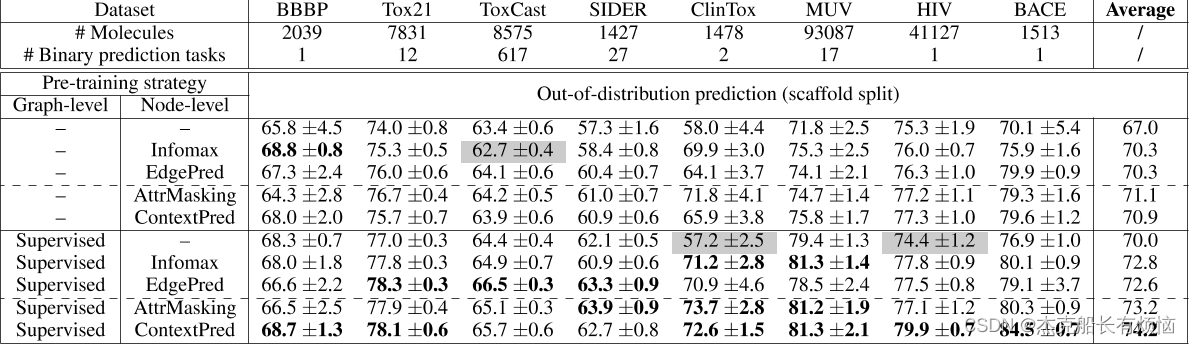
使用GIN测试ROC-AUC(%)在分子预测基准上的表现,使用不同的训练前策略。最右边的列是8个数据集测试性能的平均值。每个数据集的最佳结果和可比较的结果(即,与最佳结果在一个标准偏差内的结果)被加粗。阴影单元表示负迁移,即预训练模型的ROC-AUC低于非预训练模型。请注意,节点级和图级的预训练对于良好的性能至关重要。

测试不同GNN架构的ROC-AUC(%)性能,有无预训练。在没有预先训练的情况下,表现力较低的gnn比表现力最强的GIN的性能略好,因为它们在低数据环境下的模型复杂性较小。然而,通过预训练,最具表现力的GIN被适当地规范化,并主导了其他架构。化学数据集分割结果见附录h表4化学数据训练前策略:上下文预测+图级监督前训练;生物数据训练前策略:属性掩蔽+图级监督训练前策略
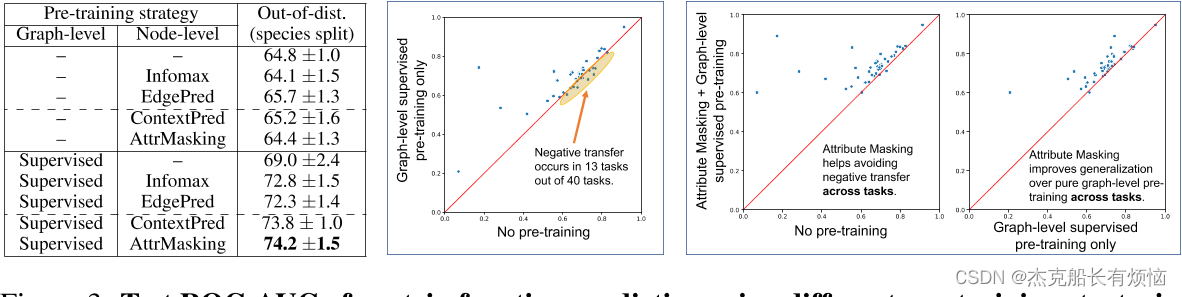
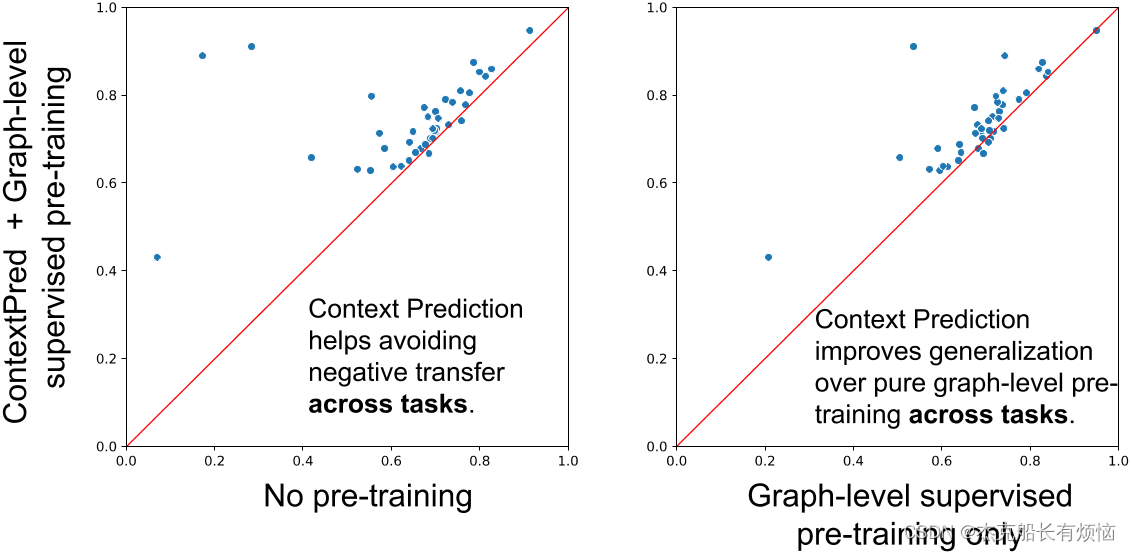
使用GIN测试不同训练前策略下蛋白质功能预测的ROC-AUC。(左)测试ROC-AUC得分(%)通过不同的训练前策略获得,其中得分在40个细粒度预测任务上的平均。(中右):在40个单独的下游任务上,对训练前策略的ROC-AUC得分进行散点图比较。每个点代表一个特定的下游任务。(中):有很多单独的下游任务,图级多任务监督预训练模型比非预训练模型表现更差,这表明负迁移。(右):将图级多任务监督前训练和属性掩蔽相结合,避免了下游任务之间的负迁移。性能也比纯图级监督训练前有所提高。
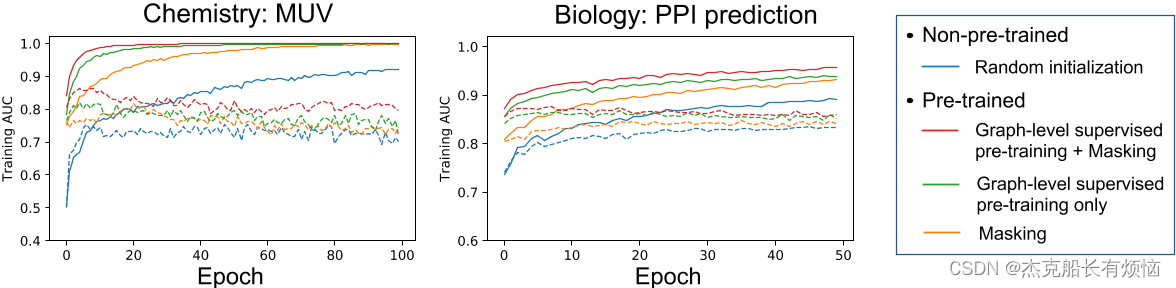
不同训练前策略对GINs的训练和验证曲线。实线和虚线分别表示训练曲线和验证曲线。
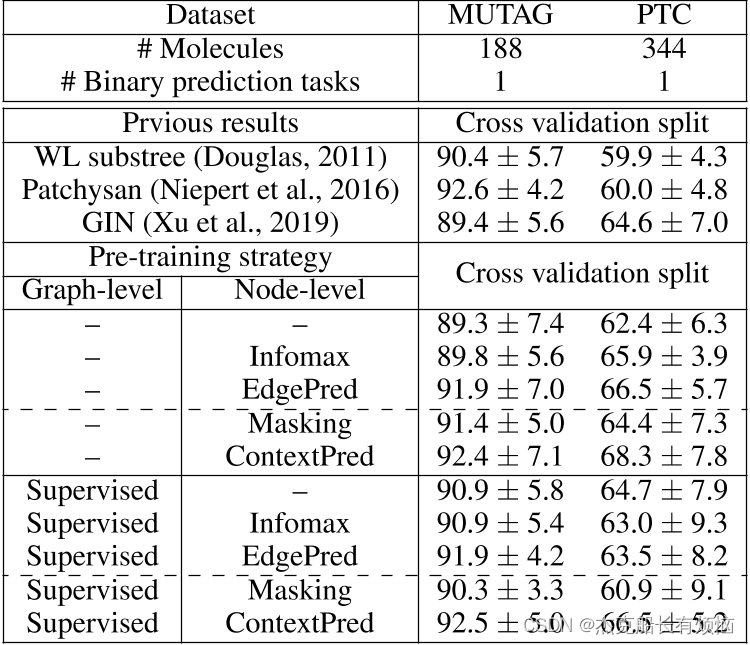
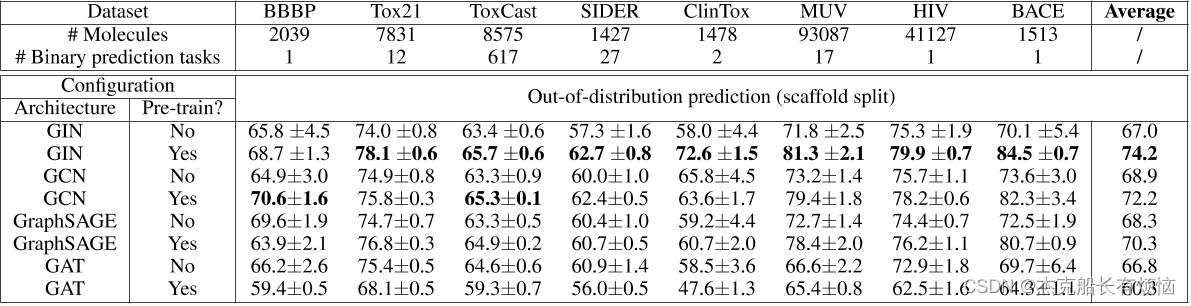
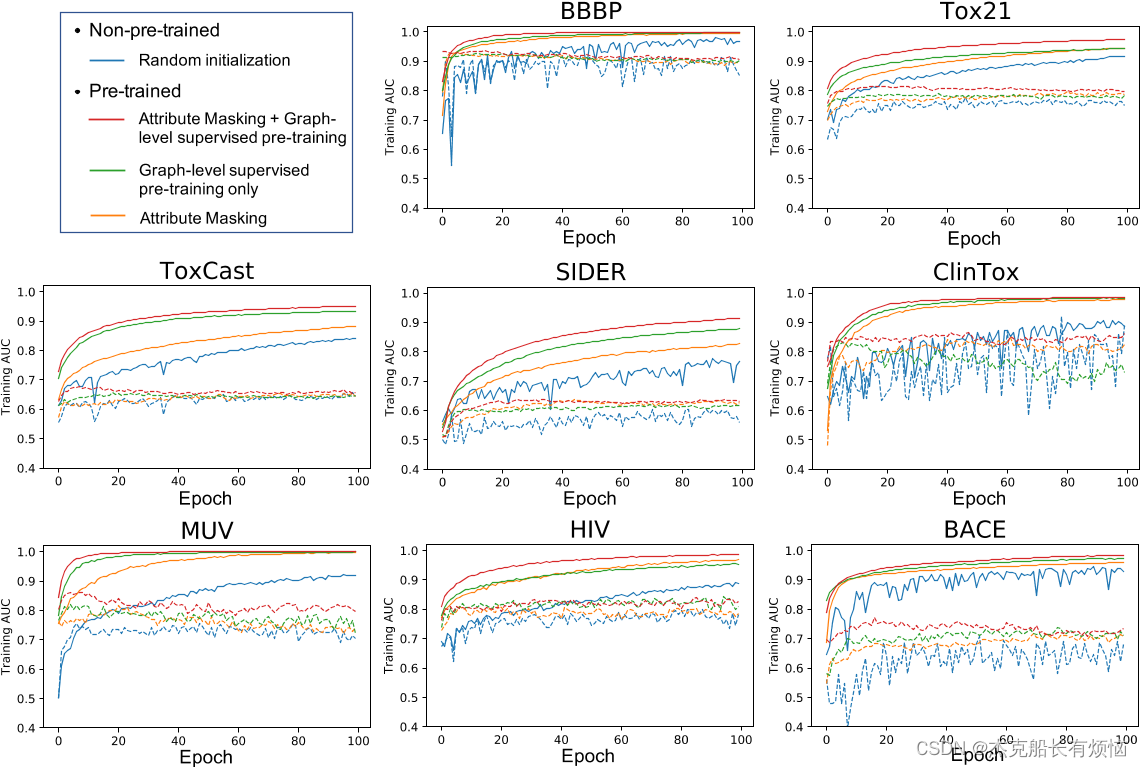
6. CONCLUSIONS AND FUTURE WORK
本文提出了GNN预训练的策略比没有经过预训练的模型具有更强的对out-of-distribution的泛化能力。
未来的研究方向有:a. 通过改进GNN体系结构以及预训练和微调方法来进一步提高泛化能力;b. 研究预训练模型学习到了什么有用的信息;c. 将本文方法应用到其他领域,例如,物理,材料科学和结构生物学,在这些领域中,许多问题都是通过表示原子,粒子和氨基酸相互作用的图形来定义的。

















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









