







transforms
按住Ctrl查看transforms的源码可以知道,transforms就是一个python文件,里面定义了很多类,每一个类都是一个工具
在结构那里,可以看到有很多的类
ToTensor
Convert a
PIL Imageornumpy.ndarrayto tensor. This transform does not support torchscript
通过ToTensor来学习transforms如何使用以及为什么使用tensor数据类型
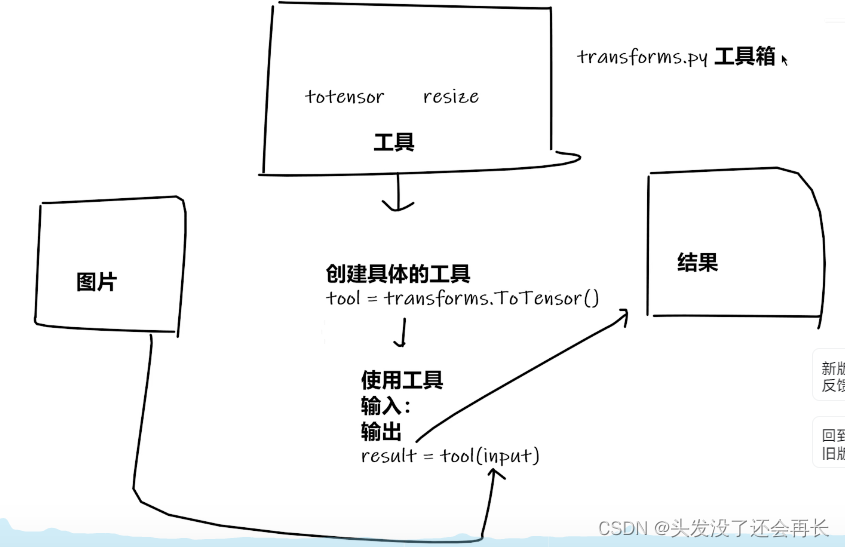
transforms使用
transforms里面每一个类都可以看成是一个模具,我们可以用里面的模具做出一个具体的工具,如何用这个具体的工具来实现具体的功能
比如ToTensor的使用:
from torchvision import transforms
from PIL import Image
img_path = "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()#模具(也就是这个类的对象)
tensor_img = tensor_trans(img)#实现ToTensor的功能,将一个input(PIL Image)转化成tensor
print(tensor_img)
为什么需要tensor数据类型呢?
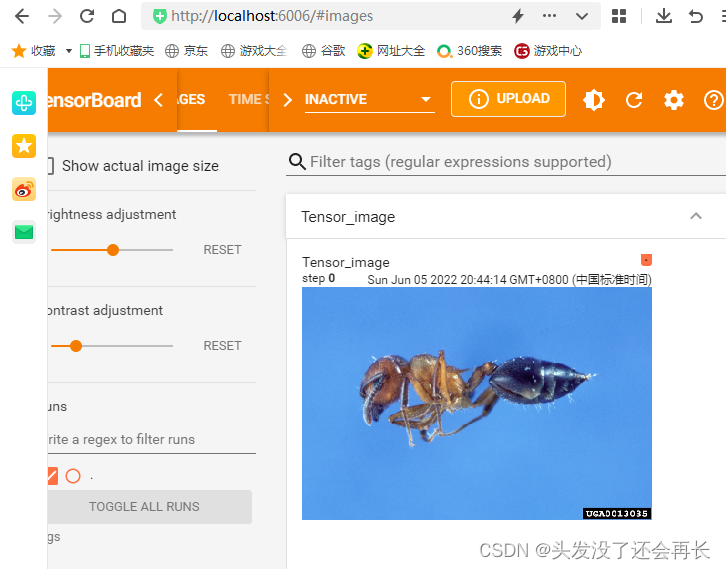
在使用tensorboard里面常用的add_image时,里面的第二个参数是图片的数据类型,这个数据类型,可以是torch.Tensor, numpy.array, or string/blobname,上一篇博客用的是numpy.array,这里,其实可以直接得到tensor类型后直接用
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
img_path = "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer = SummaryWriter("logs")
writer.add_image("Tensor_image", tensor_img)
writer.close()
常见的transforms
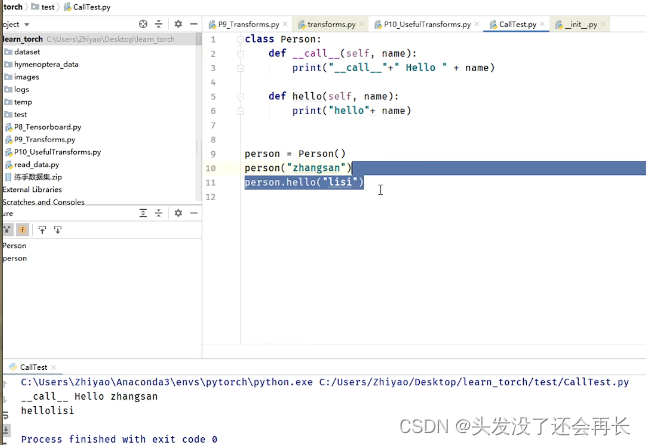
内置方法__call__()
可以发现基本上transforms里面的每一个类都有一个内置方法__call__(),这个方法和普通的方法的区别其实就是,普通方法一般是类的对象通过.的方式调用,但是call函数不需要,可以直接用对象加括号的形式调用
一个Person类,内置方法__call__和hello都有一个参数name,然后两个方法都输出name,一个通过person(“”)形式调用,一个通过person.hello(“”)调用
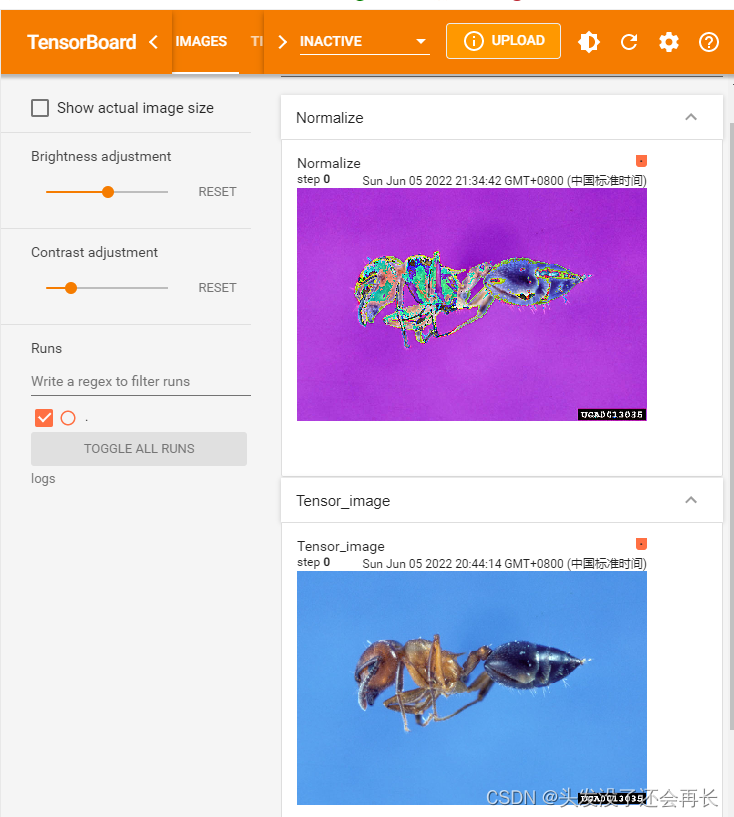
Normalize
Normalize a tensor image with mean and standard deviation.
这个方法进行归一化的时候,传入的参数是有两个列表一个是均值,一个是标准差,每个列表的n表示维度,是根据输入的channel数量决定的,比如我们的图片是rgb那n=3,它能将每个信道的输入进行归一化

根据公式可以知道计算的结果其实就是

代码示例:
from PIL import Image
from torchvision import transforms
img_path = "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer = SummaryWriter("logs")
writer.add_image("Normalize", img_norm)
writer.close()
输出:
tensor(0.3137)
tensor(-0.3725)
Resize
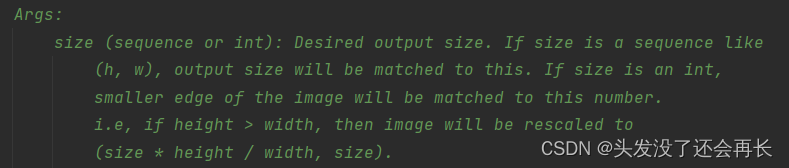
Resize the input image to the given size
参数:
可以给一个(H,W)这样的参数,改变图片的大小,也可以指定一个int,改变长和宽的比例
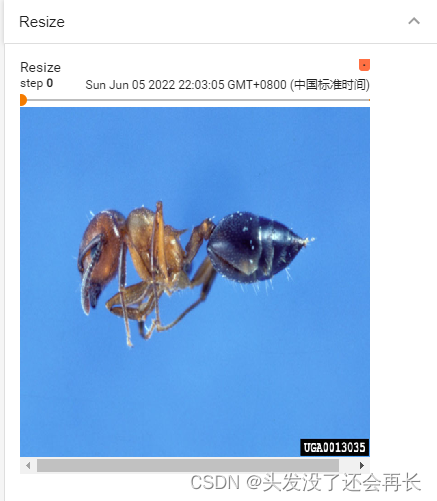
代码示例
print(img.size)
trans_resize = transforms.Resize((512, 512))
img_resize = trans_resize(img)# 参数和返回值都是 img PIL
print(img_resize)
输出结果:

变成了正方形
Compose
Composes several transforms together. This transform does not support torchscript.
可以将第一种类型转化为第二种,参数一的类型做输入,参数二的类型做输出,输入一定要对应,不然就会报错
代码示例
trans_totensor = transforms.ToTensor()
trans_resize_2 = transforms.Resize(512)
# PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)
















 1885
1885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









