







https://arxiv.org/abs/2404.07103
背景
LLM参数化记忆知识,不能参考具体的知识来源。
一般通过RAG改善,但现有RAG往往忽略了文本之间的关联。
贡献
- 构建了一个名为GRBENCH的图推理基准数据集。来自五个领域的LLMs的外部知识源,包括学术、电子商务、文学、医疗和法律领域。
同时,这个数据集中的每个样本都是有人工设计的问题和答案组成,这些问题和答案都可以通过参考图或从图中检索信息作为上下文来回答。划分了简单-中等-难三个问题类别 - 简单有效的框架——图链思考:GRAPH-COT,主要思想就是是使LLMs能够逐步遍历图以找出所需的关键信息,而不是直接将整个子图作为上下文输入到LLMs中
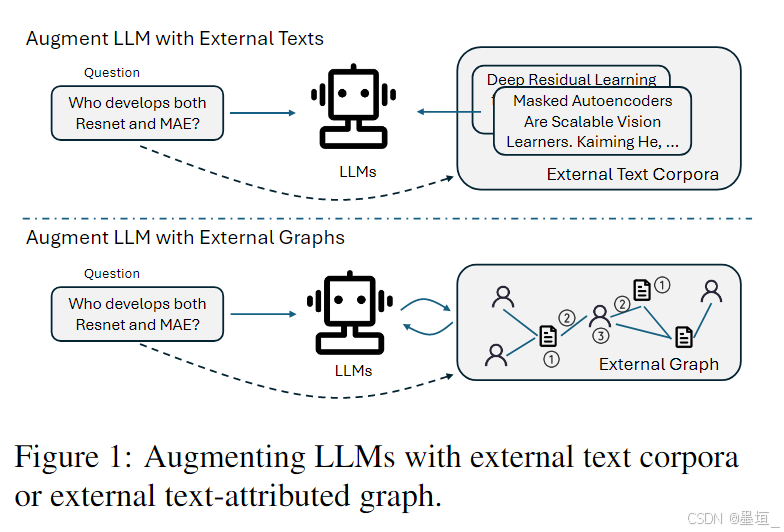
- 每次迭代包括三个子步骤:推理,交互和执行。
- 推理:LLMs提出可以根据当前信息得出结论以及需要从图中获取哪些进一步的信息
- 交互:LLMs生成从图中获取信息所需的交互(例如,查找节点、检查邻居等)
- 执行:在图上执行交互步骤中的请求,并返回相应的信息
内容
GRBENCH数据集:五个通用领域的10个图
LLMs仅凭模型参数中存储的内部知识很难回答这些问题,它们需要与外部领域的图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 73
73

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









