







1.项目背景
本项目使用了一个人工合成的天气数据集,模拟了雨天、晴天、多云和雪天四种类型,在分析过程中,对数据进行了异常值处理,并通过描述性统计对数据进行了初步探索,接着,使用Kruskal-Wallis检验、Dunn检验和卡方检验分析了温度、湿度、风速、降水量、气压、紫外线指数、能见度、云量、季节和地点等特征对天气类型的影响,最终,构建了随机森林模型进行预测,并生成了模型的重要特征图,该项目适用于初学者学习如何进行全面的数据分析和机器学习模型构建。
2.数据说明
| 列名 | 中文解释 | 单位 | 备注 |
|---|---|---|---|
| Temperature | 温度 | 摄氏度 | 气温的测量值 |
| Humidity | 湿度 | % | 空气中水蒸气的含量 |
| Wind Speed | 风速 | km/h | 风的速度 |
| Precipitation (%) | 降水量 | % | 降水强度或降水量分布 |
| Cloud Cover | 云量 | - | 天空中云的覆盖程度,文字描述 |
| Atmospheric Pressure | 气压 | hPa | 大气压力 |
| UV Index | 紫外线指数 | - | 表示紫外线强度的指数 |
| Season | 季节 | - | 数据采集的季节 |
| Visibility (km) | 能见度 | km | 可见距离的测量值 |
| Location | 地点 | - | 数据采集地点,如内陆、山区等 |
| Weather Type | 天气类型 | - | 如晴天、雨天等 |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import scipy.stats as stats
import scikit_posthocs as sp
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report,confusion_matrix
data = pd.read_csv('/home/mw/input/07292689/weather_classification_data.csv')
4.数据预览及预处理
查看数据信息:
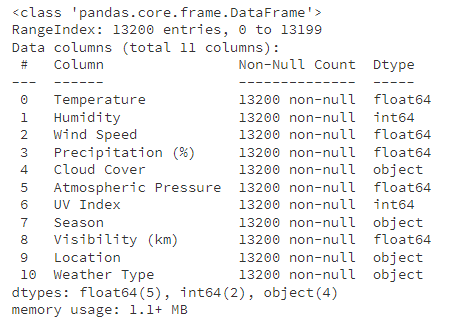
查看重复值:
0
查看分类特征的唯一值:
Cloud Cover:
['partly cloudy' 'cl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6358
6358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









