







🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【机器学习案列】基于Kmeans的健身房会员聚类分析
一、引言
随着健康意识的提升和健身文化的普及,人们对科学健身和个性化训练的需求日益增长。本项目基于973位健身房会员的真实数据,深入分析不同会员群体的训练特征和健康风险,旨在为健身房优化服务体系、制定科学训练计划提供数据支持,并通过建立健康风险预测模型,识别潜在健康隐患,为会员提供安全、高效的个性化训练指导。

二、数据说明
本次分析的数据集包含973位会员的16项特征,具体如下:
- Index:每条记录的唯一标识号
- Age:会员年龄
- Gender:会员性别(男性或女性)
- Weight (kg):会员体重(单位:公斤)
- Height (m):会员身高(单位:米)
- Max_BPM:运动时最大心率
- Avg_BPM:运动时平均心率
- Resting_BPM:静息心率
- Session_Duration (hours):每次锻炼持续时间(单位:小时)
- Calories_Burned:每次锻炼消耗的卡路里
- Workout_Type:锻炼类型(包括瑜伽、HIIT、有氧、力量训练)
- Fat_Percentage:体脂率(百分比)
- Water_Intake (liters):饮水量(单位:升)
- Workout_Frequency (days/week):每周锻炼频率(单位:天/周)
- Experience_Level:训练经验水平(1至3级)
- BMI:身体质量指数
三、数据预处理
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from scipy.stats import spearmanr, f_oneway
from imblearn.over_sampling import RandomOverSampler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import classification_report, mean_squared_error, r2_score, mean_absolute_error
# 读取数据
data = pd.read_csv("/home/mw/input/11011446/gym_members_data.csv")
# 检查数据信息
print('查看数据信息:')
print(data.info())
print(f'查看重复值:{data.duplicated().sum()}')
# 检查BMI计算是否正确
sample_bmi = data['Weight (kg)'] / (data['Height (m)'] ** 2)
diff = abs(sample_bmi - data['BMI'])
print(f"最大差异: {diff.max():.4f}")
if diff.max() < 0.01:
print("BMI计算正确")
else:
print("在允许存在0.01误差情况下,BMI计算可能存在问题")
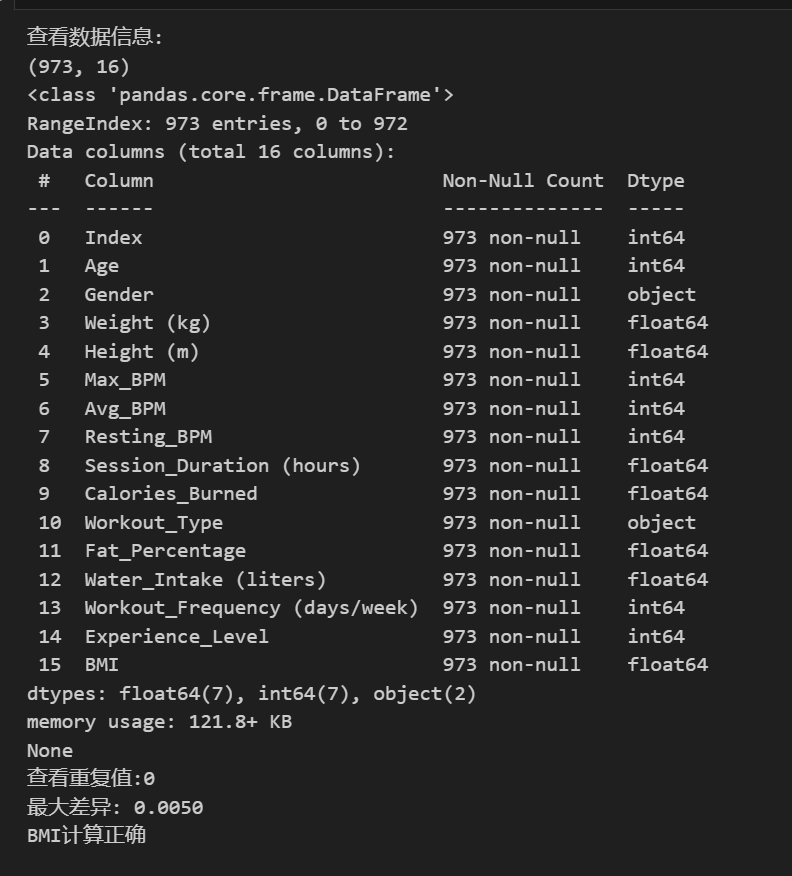
数据shape为(973,16),且不存在缺失值合重复值;
四、用户画像分析
4.1 特征字段映射
feature_map = {
'Age': '年龄',
'Weight (kg)': '体重(公斤)',
'Height (m)': '身高(米)',
'Max_BPM': '最大心率',
'Avg_BPM': '平均心率',
'Resting_BPM': '静息心率',
'Session_Duration (hours)': '训练时长(小时)',
'Calories_Burned': '消耗卡路里',
'Fat_Percentage': '体脂率(%)',
'Water_Intake (liters)': '饮水量(升)',
'Workout_Frequency (days/week)': '每周锻炼频率(天/周)',
'BMI': '身体质量指数'
}
将数据的特征字段名称映射到相应的中文含义,便于可视化分析;
4.2 数据总体分析
plt.figure(figsize=(20, 15))
for i, (col, col_name) in enumerate(feature_map.items(), 1):
plt.subplot(3, 4, i)
sns.boxplot(y=data[col])
plt.title(f'{col_name}的箱线图', fontsize=14)
plt.ylabel('数值', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()

虽然体重、BMI、卡路里消耗存在少量异常值,但是也是符合一些大体重、运动时间较长的用户,故不处理这些值。
4.3 数据特征分析
# 绘制会员年龄分布
plt.figure(figsize=(20,15))
plt.subplot(3, 3, 1)
sns.histplot(data['Age'], bins=41, kde=True)
plt.title('会员年龄分布')
plt.xlabel('年龄 (岁)')
plt.ylabel('人数')
plt.grid(axis='y')
# 绘制会员性别比例
gender_counts = data['Gender'].value_counts()
plt.subplot(3, 3, 2)
plt.pie(gender_counts, labels=gender_counts.index, autopct='%1.1f%%', startangle=90, colors=['#66b3ff','#ff9999'])
plt.title('会员性别比例')
plt.axis('equal') # 使饼图为圆形
# 绘制会员体重与身高关系
plt.subplot(3, 3, 3)
sns.regplot(x='Height (m)', y='Weight (kg)', data=data, scatter_kws={'s': 50}, line_kws={'color': 'red'})
plt.title('会员体重与身高关系')
plt.xlabel('身高 (米)')
plt.ylabel('体重 (公斤)')
plt.grid(True)
# 绘制会员锻炼类型偏好
ax4 = plt.subplot(3, 3, 4)
sns.countplot(x='Workout_Type', data=data)
plt.title('会员锻炼类型偏好')
plt.xlabel('锻炼类型')
plt.ylabel('人数')
for p in ax4.patches:
ax4.annotate(f'{p.get_height()}', (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', fontsize=11, color='black', xytext=(0, 5),
textcoords='offset points')
# 绘制会员每周锻炼频率分布
ax5 = plt.subplot(3, 3, 5)
sns.countplot(x='Workout_Frequency (days/week)', data=data)
plt.title('会员每周锻炼频率分布')
plt.xlabel('锻炼频率 (每周次数)')
plt.ylabel('人数')
for p in ax5.patches:
ax5.annotate(f'{p.get_height()}', (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', fontsize=11, color='black', xytext=(0, 5),
textcoords='offset points')
# 绘制会员每次锻炼持续时间分布
plt.subplot(3, 3, 6)
sns.histplot(data['Session_Duration (hours)'], bins=6, kde=True)
plt.title('会员每次锻炼持续时间分布')
plt.xlabel('每次锻炼持续时间(单位:小时)')
plt.ylabel('人数')
plt.grid(axis='y')
# 绘制会员体脂率分布
plt.subplot(3, 3, 7)
sns.histplot(data['Fat_Percentage'], bins=5, kde=True)
plt.title('会员体脂率分布')
plt.xlabel('体脂率(百分比)')
plt.ylabel('人数')
plt.grid(axis='y')
# 绘制会员BMI分布
experience_level_counts = data['Experience_Level'].value_counts()
plt.subplot(3, 3, 8)
plt.pie(experience_level_counts, labels=experience_level_counts.index, autopct='%1.1f%%', startangle=90)
plt.title('训练经验水平比例')
plt.axis('equal') # 使饼图为圆形
plt.subplot(3, 3, 9)
sns.histplot(data['BMI'], bins=12, kde=True)
plt.title('会员BMI分布')
plt.xlabel('BMI')
plt.ylabel('人数')
plt.grid(axis='y')
plt.tight_layout()
plt.show()
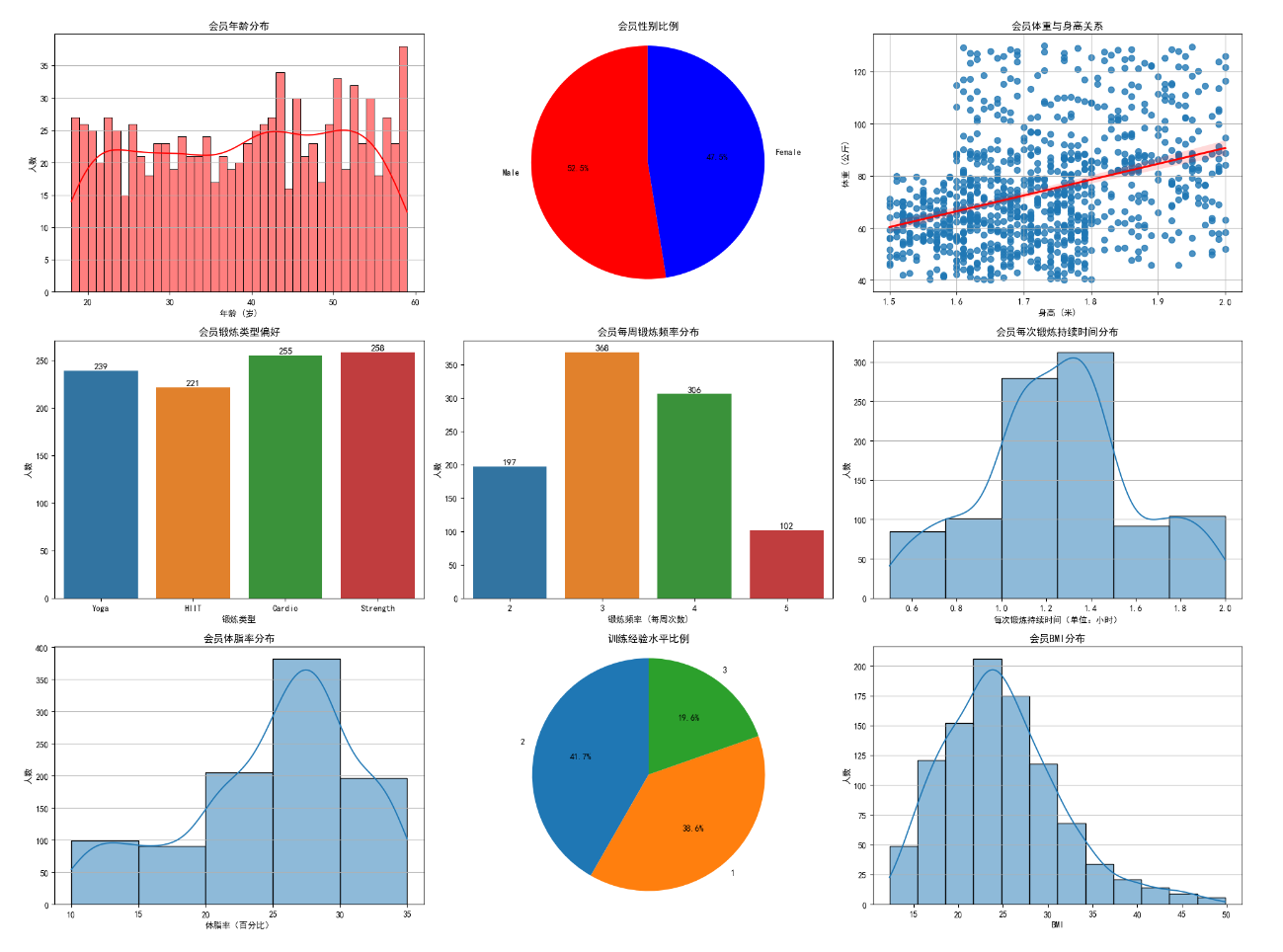
基础人口统计特征:
- 样本量为973人,年龄18-59岁,平均38.7岁,标准差12.2岁
- 性别分布中男性511人占多数,表明男性更倾向于健身房锻炼
- 体重范围从40kg到129.9kg,平均73.85kg,标准差21.21kg反映出体重差异较大
- 身高范围在1.5m到2.0m之间,平均1.72m,标准差较小(0.13m)显示身高分布集中
运动表现指标:
- 最大心率160-199,平均179.88,说明运动强度普遍较大
- 平均心率120-169,均值143.77,显示整体运动强度适中
- 静息心率50-74,均值62.22,处于健康范围
- 训练时长从0.5小时到2小时不等,平均1.26小时,符合科学锻炼建议
- 卡路里消耗差异很大,从303到1783卡路里,平均905.42卡路里
健康与习惯指标:
- 体脂率从10%到35%不等,平均24.98%,标准差6.26%反映出较大差异
- 饮水量1.5-3.7升,平均2.63升,表明会员普遍注意补充水分
- 每周锻炼2-5次,平均3.32次,标准差0.91显示锻炼频率较稳定
- BMI分布广泛(12.32-49.84),平均24.91,标准差6.66,暗示会员体型差异大
训练水平:
- 经验等级1-3级,平均1.81级,标准差0.74表明以初中级为主
- 四种训练类型中Strength最受欢迎(258人),反映力量训练的主导地位
五、聚类分析
5.1 数据预处理
对数值型变量就行标准化,对分类变量进行独热编码。
data_scaled = data.drop(columns='Index')
numerical_features = data_scaled.select_dtypes(include=[np.number]).columns.tolist()
scaler = StandardScaler()
data_scaled[numerical_features] = scaler.fit_transform(data_scaled[numerical_features])
categorical_features = ['Gender', 'Workout_Type']
data_scaled = pd.get_dummies(data_scaled, columns=categorical_features)
bool_columns = data_scaled.select_dtypes(include=[bool]).columns
data_scaled[bool_columns] = data_scaled[bool_columns].astype(int)
5.2 确定聚类数
inertia = []
silhouette_scores = []
k_range = range(2, 11)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=15).fit(data_scaled)
inertia.append(kmeans.inertia_)
silhouette_scores.append(silhouette_score(data_scaled, kmeans.labels_))
plt.figure(figsize=(15,5))
plt.subplot(1, 2, 1)
plt.plot(k_range, inertia, marker='o',color='red')
plt.xlabel('聚类中心数目')
plt.ylabel('惯性')
plt.title('肘部法则图')
plt.subplot(1, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o',color='red')
plt.xlabel('聚类中心数目')
plt.ylabel('轮廓系数')
plt.title('轮廓系数图')
plt.tight_layout()
plt.show()
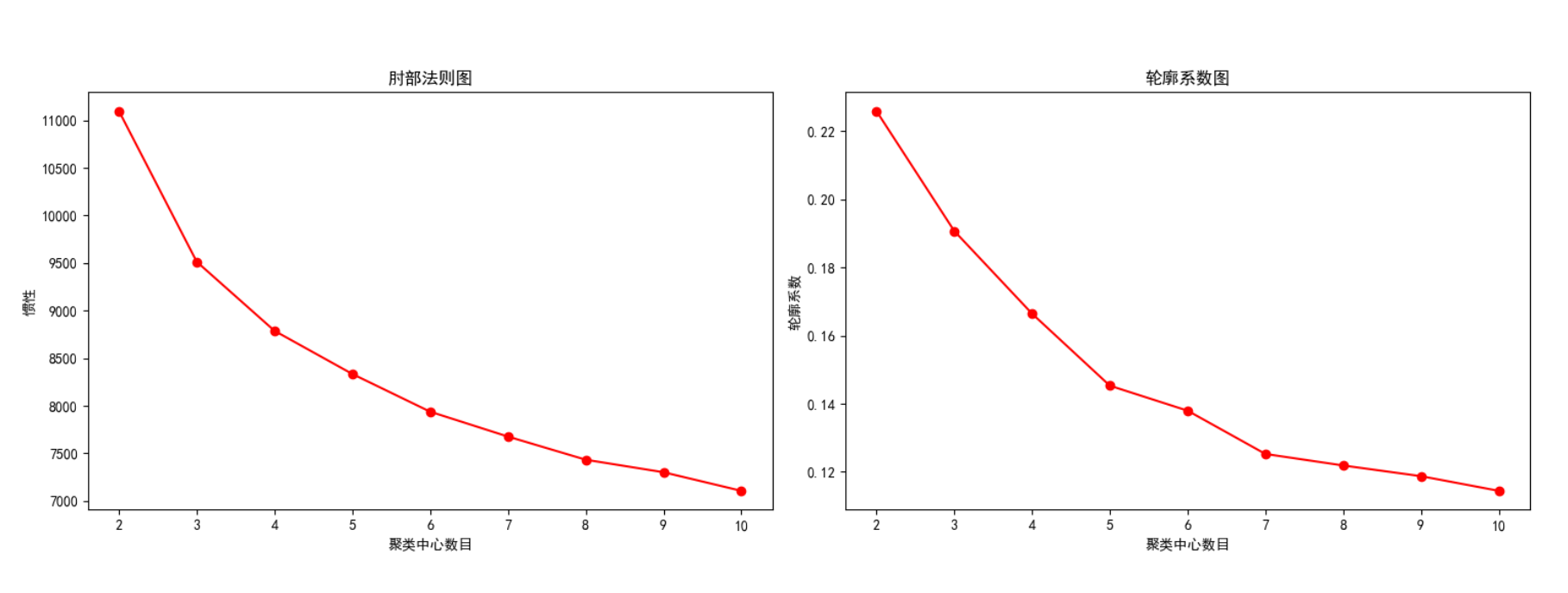
- 肘部法则(左图 - 射部法则图):当聚类中心数量达到 4 或 5 时,惯性值的下降幅度开始变得较小。这意味着聚类效果在 4 或 5 个聚类时已经显著提高,之后增加聚类数带来的收益开始减小。
- 轮廓系数图(右图 - 轮廓系数图):聚类数为 2 时轮廓系数最高,之后随着聚类数的增加,轮廓系数逐渐下降。
综上所述,4个聚类是一个较为合理的选择,因为此时惯性已经大幅降低,且轮廓系数还保持在相对较高的水平。
5.3 K-Means聚类
kmeans = KMeans(n_clusters=4, random_state=15)
kmeans.fit(data_scaled)
cluster_labels = kmeans.labels_
data['Cluster'] = cluster_labels
cluster_centers = kmeans.cluster_centers_
feature_variances = np.var(cluster_centers, axis=0)
feature_importance = pd.DataFrame({
'Feature': data_scaled.columns,
'Variance': feature_variances
})
feature_importance = feature_importance[feature_importance['Feature'] != 'Cluster']
feature_importance = feature_importance.sort_values(by='Variance', ascending=False)
给我数据添加了Cluster的字段名称,包括0,1,2,3四类;
5.4 四类用户画像分析
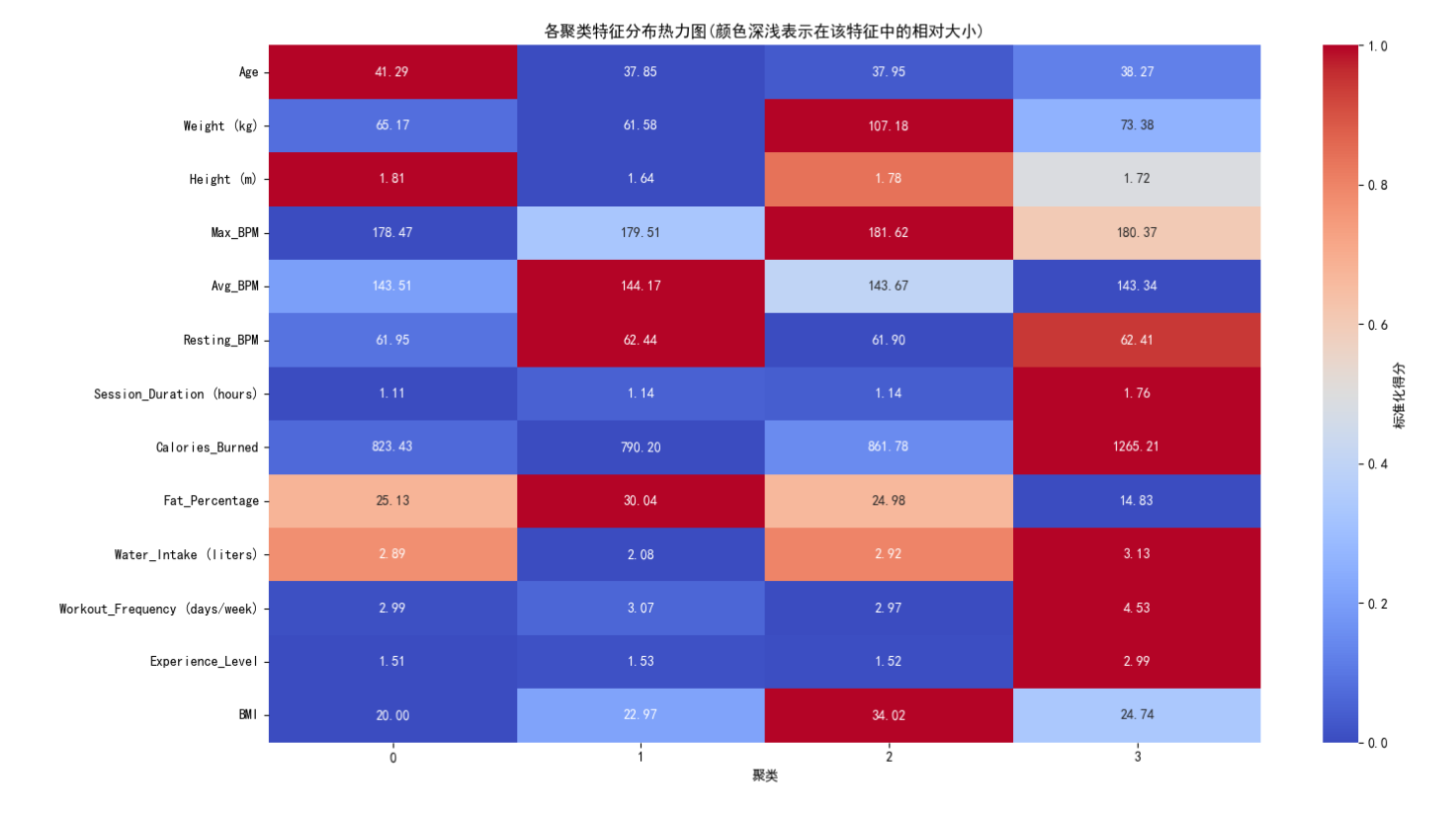
cluster_means = data.groupby('Cluster')[numerical_features].mean()
normalized_means = cluster_means.apply(lambda x: (x - x.min()) / (x.max() - x.min()))
plt.figure(figsize=(15, 8))
sns.heatmap(normalized_means.T,
cmap='coolwarm',
center=0.5,
vmin=0,
vmax=1,
annot=cluster_means.T.round(2),
fmt='.2f',
cbar_kws={'label': '标准化得分'})
plt.xlabel('聚类')
plt.title('各聚类特征分布热力图(颜色深浅表示在该特征中的相对大小)')
plt.tight_layout()
plt.show()
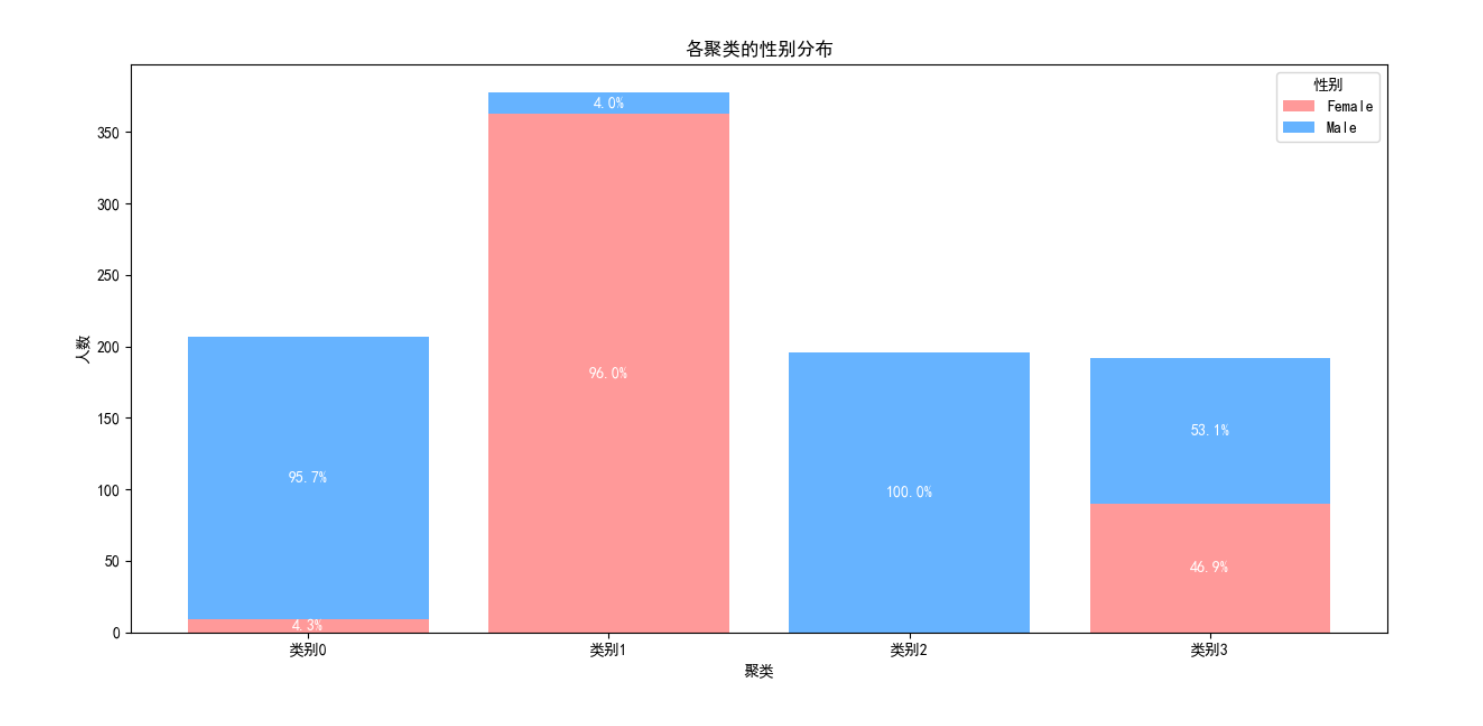
# 计算每个聚类中的性别分布
gender_counts = pd.crosstab(data['Cluster'], data['Gender'])
gender_proportions = pd.crosstab(data['Cluster'], data['Gender'], normalize='index')
# 创建图形
plt.figure(figsize=(12, 6))
plt.bar(gender_counts.index, gender_counts['Female'], label='Female', color='#ff9999')
plt.bar(gender_counts.index, gender_counts['Male'], bottom=gender_counts['Female'], label='Male', color='#66b3ff')
for i in range(len(gender_counts)):
for gender in ['Female', 'Male']:
proportion = gender_proportions.iloc[i][gender]
count = gender_counts.iloc[i][gender]
if proportion > 0.01:
if gender == 'Female':
y_position = count/2
else:
y_position = gender_counts['Female'].iloc[i] + count/2
plt.text(i, y_position, f'{proportion:.1%}', ha='center', va='center', fontsize=10, color='white', fontweight='bold')
plt.title('各聚类的性别分布')
plt.xlabel('聚类')
plt.ylabel('人数')
plt.legend(title='性别')
plt.xticks(range(len(gender_counts)), [f'类别{i}' for i in range(len(gender_counts))])
plt.tight_layout()
plt.show()
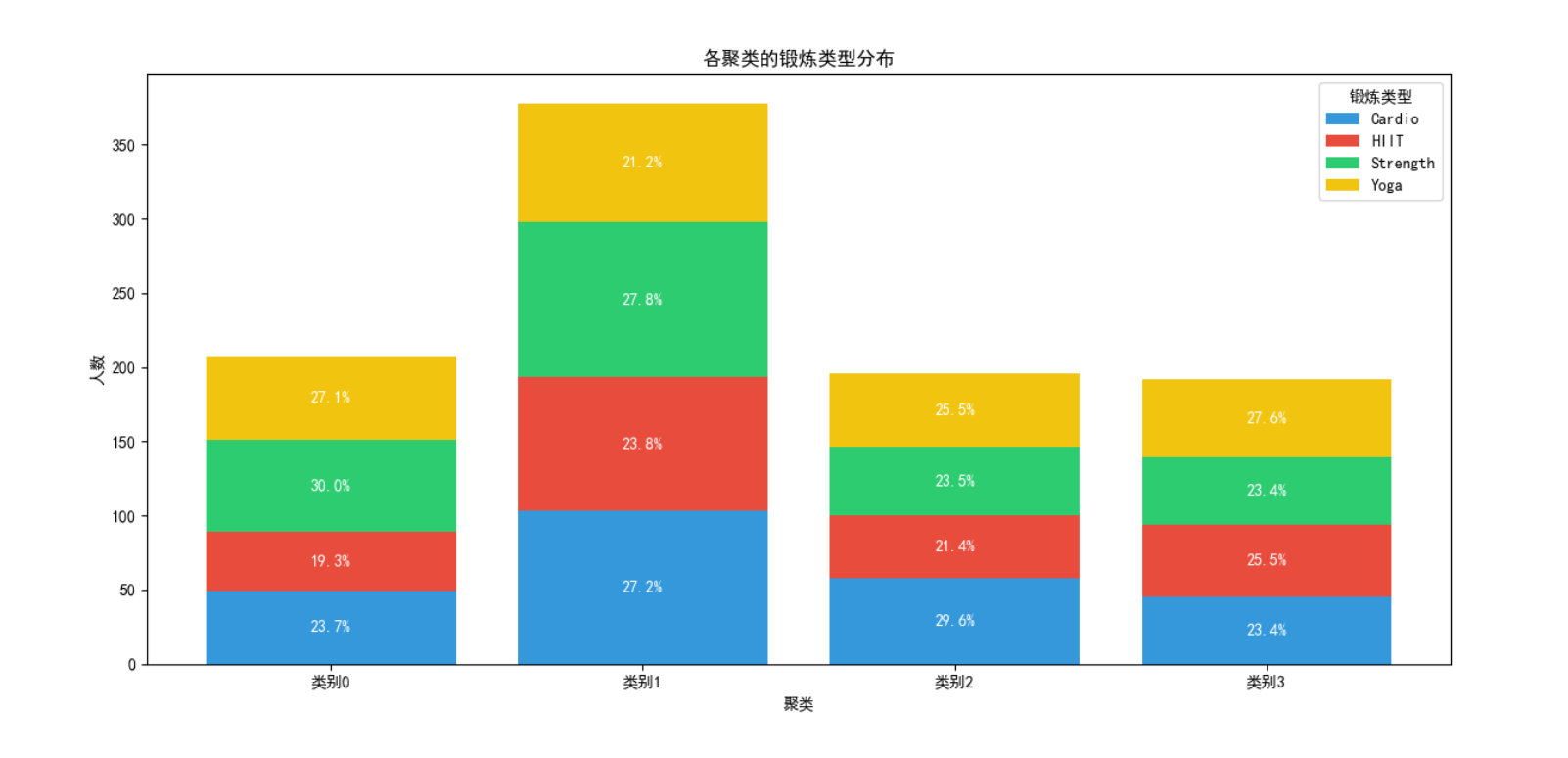
# 对于锻炼类型分布分析
workout_counts = pd.crosstab(data['Cluster'], data['Workout_Type'])
workout_proportions = pd.crosstab(data['Cluster'], data['Workout_Type'], normalize='index')
plt.figure(figsize=(12, 6))
colors = ['#3498db', '#e74c3c', '#2ecc71', '#f1c40f']
bottom = np.zeros(len(workout_counts))
for i, workout in enumerate(workout_counts.columns):
plt.bar(workout_counts.index, workout_counts[workout], bottom=bottom, label=workout, color=colors[i])
for j in range(len(workout_counts)):
proportion = workout_proportions.iloc[j][workout]
if proportion > 0.01:
y_position = bottom[j] + workout_counts.iloc[j][workout]/2
plt.text(j, y_position, f'{proportion:.1%}', ha='center', va='center', fontsize=10, color='white', fontweight='bold')
bottom += workout_counts[workout]
plt.title('各聚类的锻炼类型分布')
plt.xlabel('聚类')
plt.ylabel('人数')
plt.legend(title='锻炼类型')
plt.xticks(range(len(workout_counts)), [f'类别{i}' for i in range(len(workout_counts))])
plt.tight_layout()
plt.show()
根据新的数据,我来重新总结各个聚类的特征和建议:
Cluster 0 特征
以男性为主(95.65%)的中年会员群体,身高较高体重适中,BMI正常偏瘦,训练频率和时长中等,训练经验初级到中级,体脂率中等,饮水量适中,力量训练和瑜伽比例较高。
**Cluster 1 特征 **
全男性(100%)群体,体重和BMI最高,训练时长和频率适中,训练经验初级到中级,体脂率中等,饮水量适中,偏好有氧运动。
Cluster 2 特征
性别均衡(男53.12%,女46.88%)的高级会员群体,训练时长最长,卡路里消耗最高,训练频率最高,体脂率最低,训练经验最丰富,饮水量最高,各类型运动分布均衡。
Cluster 3 特征
以女性为主(96.03%)的会员群体,身高体重较低,训练时长适中,卡路里消耗最少,训练频率中等,训练经验初级到中级,体脂率最高,饮水量最低,力量训练和有氧运动比例较高。



















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











