






 文章介绍了目标检测算法中锚框的标注过程,通过计算锚框与真实边界框的IoU来分配类别和偏移量标签。在训练数据中标注锚框时,会依据IoU将真实边界框分配给锚框,并通过一个示例解释了如何实现这个过程。当类别数量不同时,使用填充策略确保批量处理的一致性。
文章介绍了目标检测算法中锚框的标注过程,通过计算锚框与真实边界框的IoU来分配类别和偏移量标签。在训练数据中标注锚框时,会依据IoU将真实边界框分配给锚框,并通过一个示例解释了如何实现这个过程。当类别数量不同时,使用填充策略确保批量处理的一致性。
目录
一:回顾
上一节课我们了解了目标检测基础中的iou知识点,它是目标检测算法中用于衡量预测框(bounding box)和真实标注框之间重叠程度的指标。它通过计算两个框的交集面积除以它们的并集面积来度量它们的相似度。IOU 的取值范围是 0 到 1,其中 1 表示完全重合,0 表示没有重叠。
二: 在训练数据中标注锚框
在训练集中,我们将每个锚框视为一个训练样本。 为了训练目标检测模型,我们需要每个锚框的类别(class)和偏移量(offset)标签,其中前者是与锚框相关的对象的类别,后者是真实边界框相对于锚框的偏移量。 在预测时,我们为每个图像生成多个锚框,预测所有锚框的类别和偏移量,根据预测的偏移量调整它们的位置以获得预测的边界框,最后只输出符合特定条件的预测边界框。
目标检测训练集带有真实边界框的位置及其包围物体类别的标签。 要标记任何生成的锚框,我们可以参考分配到的最接近此锚框的真实边界框的位置和类别标签。 下文将介绍一个算法,它能够把最接近的真实边界框分配给锚框。
将真实边界框分配给锚框
给定图像,假设锚框是A1,A2,…,An,真实边界框是B1,B2,…,BN,其中Na≥Nb。 让我们定义一个矩阵X∈R*na*nb,其中第i行、第j列的元素xij是锚框Ai和真实边界框Bj的IoU。 该算法包含以下步骤。

下面用一个具体的例子来说明上述算法。 如下图所示,假设矩阵X中的最大值为x23,我们将真实边界框b3分配给锚框a2。 然后,我们丢弃矩阵第2行和第3列中的所有元素,在剩余元素(阴影区域)中找到最大的x71,然后将真实边界框b1分配给锚框a7。...... 之后,我们只需要遍历剩余的锚框a1,a3,a4,a6,a8,然后根据阈值确定是否为它们分配真实边界框。
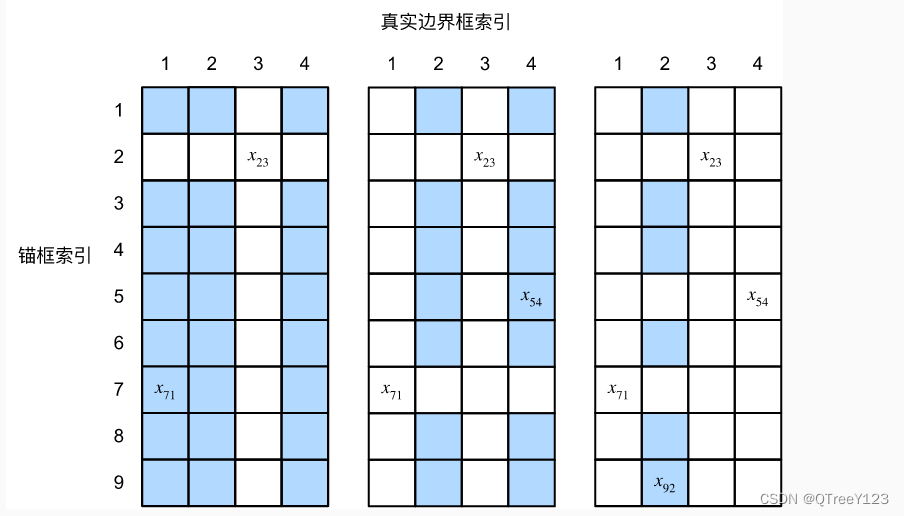
此算法在下面的assign_gtbox_to_anchor函数中实现。
创建drop_columns和drop_row来覆盖当前最大值的行和列号。
# 给锚框分配真实边界框,以及分配真实标签
def assign_gtbox_to_anchor(anchors, gtboxs, device, threshold=0.01):
anchors, gtboxs = anchors.to(device), gtboxs.to(device)
num_batch = anchors.shape[0] # 获取批次
iou_areas = iou(anchors, gtboxs[:, :, 1:], device=device) # 获取iou值
cls_anchors_false = []
cls_anchors_true = []
'''
cls_anchors_false:没有把真实边界框里面的填充边界框类别修改为负类(存放列的标号)
cls_anchors_true:把真实边界框里面的填充边界框类别修改为负类(主函数需要)
'''
for i in range(num_batch):
cls_gtbox = gtboxs[i, :, 0] # 获取每一个批次的每一个gtbox的类别
# print('cls_gtbox类别有:',cls_gtbox) tensor([ 0., 1., -1., 3., 2.])
# 对阈值进行分类
iou_area = iou_areas[i, :, :] # 获取第i个批次的iou值
# print('iou_area is :',iou_area)
# ou_area.shape[0],而不是【1】,因为每一行肯定都会有iou。那每一行都应该有类别
cls_anchor_false = torch.full([iou_area.shape[0]], -1, dtype=torch.long, device=device)
# print('cls_anchor_false.shape is :',cls_anchor_false)#tensor([-1, -1, -1, -1, -1, -1])
cls_anchor_true = torch.full([iou_area.shape[0]], -1, dtype=torch.long, device=device)
# 根据iou_area的第0维度也就是anchor的个数,建立两个全-1的一行的tensor。iou_area上面已经取出来了,
# 所以降了一维所以nonzero的时候只会出现二维,也就是行和列,没有第三维度,刚刚测试的时候我出现了第三维是因为我的数据没取出来之前是三维的
# 通过threshold筛选掉一些小于阈值的垃圾,小于的就不给他标真实锚框号
# 通过nonzero返回坐标的行和列
idx_anchor = torch.nonzero(iou_area >= threshold)[:, 0].reshape(-1)#行号,表示第几个锚框
idx_gtbox = torch.nonzero(iou_area >= threshold)[:, 1].reshape(-1) #列号,表示类别
print('iou_area is:',iou_area)
print('idx_anchor is:',idx_anchor)
print('idx_gtbox is:',idx_gtbox)
#iou大于0.5的,把对应的idx_gtbox列号覆盖-1这个类别
cls_anchor_false[idx_anchor] = idx_gtbox
# 然后这里再把真实锚框号的真实类别给到锚框那去。这里将gtbox的每一个真实类别返回给cls_anchor_true
cls_anchor_true[idx_anchor] = cls_gtbox[idx_gtbox].long()
print('cls_anchor_false is:',cls_anchor_false)
print('cls_anchor_true is:',cls_anchor_true)
print('cls_gtbox is :',cls_gtbox)
print('cls_gtbox[idx_gtbox] is :',cls_gtbox[idx_gtbox])
print('cls_gtbox[idx_gtbox].long() is :',cls_gtbox[idx_gtbox].long())
# 丢弃法,就是threshold后每一行还有很多个锚框,那要选出iou最大的那个
# 用-1填充丢弃的行和列,先初始化行的-1的个数和列的-1的个数,然后才方便填充
drop_columns = torch.full([iou_area.shape[0]], -1, dtype=torch.long, device=device)
drop_row = torch.full([iou_area.shape[1]], -1, dtype=torch.long, device=device)
# 建立两条丢弃tensor,用于在挑选完一个最大值后将该值对应的一行和一列变成-1来避免再次被索引到
iou_area, cls_anchor_false, cls_anchor_true = iou_area.to(device), cls_anchor_false.to(
device), cls_anchor_true.to(device)
# 找最大的iou
for _ in range(iou_area.shape[1]): # 这里一定要是【1】,因为有多少列就对应着几个类别,最多也就对应着多少个锚框,重复的也会去掉
# 获取整个iou_area中最大值对应的 列索引
idx_columns = torch.max(iou_area, dim=1).indices[ #max返回列索引
torch.max(iou_area, dim=1).values == max(torch.max(iou_area, dim=1).values)][0]
# 根据整个iou_area中最大值得到的列索引idx_columns,在这里一列寻找获得最大的行索引
idx_row = torch.max(iou_area[:, idx_columns], dim=0).indices
# 上面threshold也做了 cls_anchor_false[idx_row] = idx_columns这种操作,但是不好使,这里还要再筛选一边,选出最好的一个
cls_anchor_false[idx_row] = idx_columns # 将最大值的行索引对应的列索引也就是gtbox的未修改填充编辑框的类别赋给cls_anchor_false
cls_anchor_true[idx_row] = cls_gtbox[idx_columns] ##将gtbox的每一个真实类别返回给cls_anchor_true
#上面两句标记完后,就把所在的行列全部标记为-1
iou_area[idx_row, :] = drop_row # 用全-1tensor覆盖已挑选最大值的这一行
iou_area[:, idx_columns] = drop_columns # 用全-1tensor覆盖已挑选最大值的这一列
iou_area, cls_anchor_false, cls_anchor_true = iou_area.to(device), cls_anchor_false.to(
device), cls_anchor_true.to(device)
#保存每一轮batch的值
cls_anchors_false.append(cls_anchor_false)
cls_anchors_true.append(cls_anchor_true)
cls_anchors_false = torch.stack([*cls_anchors_false], dim=0).reshape(num_batch, -1)
cls_anchors_true = torch.stack([*cls_anchors_true], dim=0).reshape(num_batch, -1)
return cls_anchors_false, cls_anchors_true
#问:为什么取完最大值要填充-1?因为那一行那一列只能有一个类别(锚框),所以要这样做核心部分
idx_anchor = torch.nonzero(iou_area >= threshold)[:, 0].reshape(-1)#行号,表示第几个锚框
idx_gtbox = torch.nonzero(iou_area >= threshold)[:, 1].reshape(-1) #列号,表示类别
print('iou_area is:',iou_area)
print('idx_anchor is:',idx_anchor)
print('idx_gtbox is:',idx_gtbox)
#iou大于0.5的,把对应的idx_gtbox列号覆盖-1这个类别
cls_anchor_false[idx_anchor] = idx_gtbox
# 然后这里再把真实锚框号的真实类别给到锚框那去。这里将gtbox的每一个真实类别返回给cls_anchor_true
cls_anchor_true[idx_anchor] = cls_gtbox[idx_gtbox].long()
# 找最大的iou
for _ in range(iou_area.shape[1]): # 这里一定要是【1】,因为有多少列就对应着几个类别,最多也就对应着多少个锚框,重复的也会去掉
# 获取整个iou_area中最大值对应的 列索引
idx_columns = torch.max(iou_area, dim=1).indices[ #max返回列索引
torch.max(iou_area, dim=1).values == max(torch.max(iou_area, dim=1).values)][0]
# 根据整个iou_area中最大值得到的列索引idx_columns,在这里一列寻找获得最大的行索引
idx_row = torch.max(iou_area[:, idx_columns], dim=0).indices
# 上面threshold也做了 cls_anchor_false[idx_row] = idx_columns这种操作,但是不好使,这里还要再筛选一边,选出最好的一个
cls_anchor_false[idx_row] = idx_columns # 将最大值的行索引对应的列索引也就是gtbox的未修改填充编辑框的类别赋给cls_anchor_false
cls_anchor_true[idx_row] = cls_gtbox[idx_columns] ##将gtbox的每一个真实类别返回给cls_anchor_true
#上面两句标记完后,就把所在的行列全部标记为-1
iou_area[idx_row, :] = drop_row # 用全-1tensor覆盖已挑选最大值的这一行
iou_area[:, idx_columns] = drop_columns # 用全-1tensor覆盖已挑选最大值的这一列测试结果:
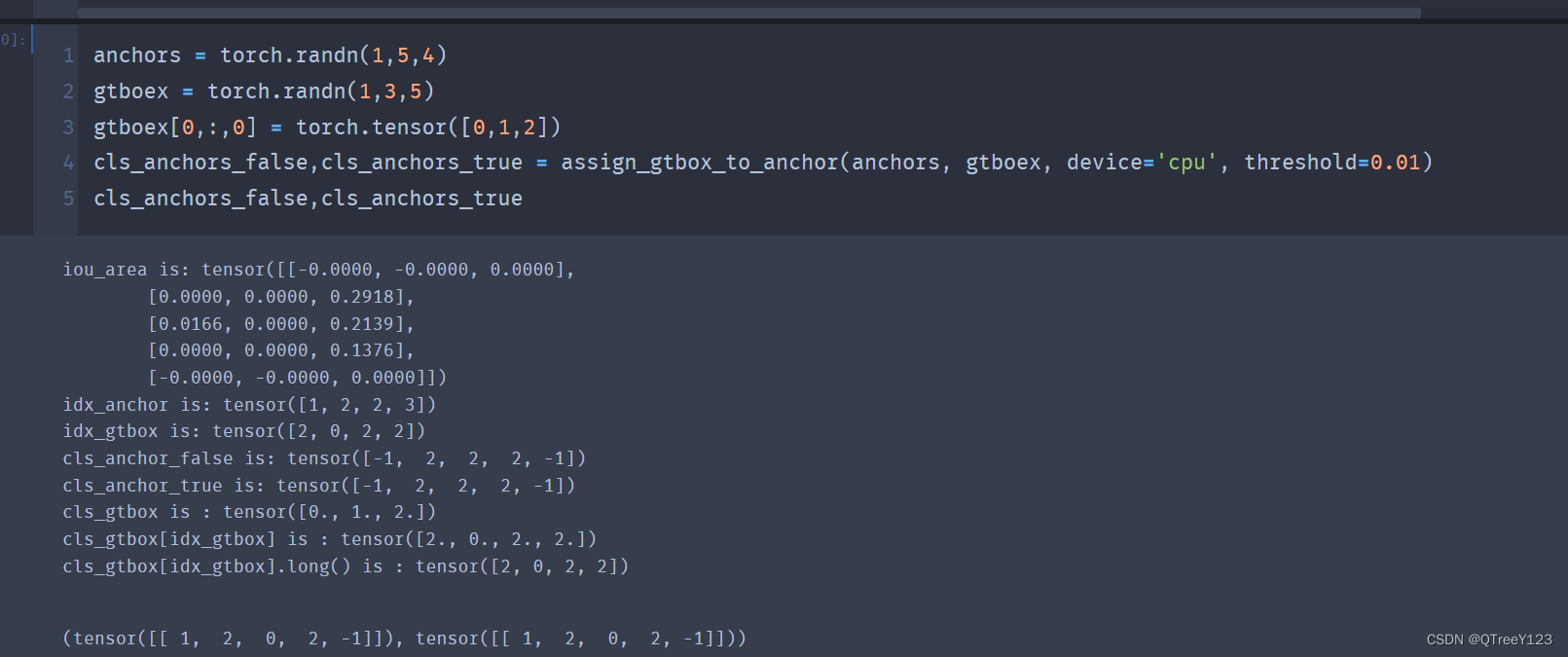
idx_anchor = torch.nonzero(iou_area >= threshold)[:, 0].reshape(-1)#行号,表示第几个锚框
idx_gtbox = torch.nonzero(iou_area >= threshold)[:, 1].reshape(-1) #列号,表示类别
去除行号表示锚框,列号表示类别,但表示类别的标签!
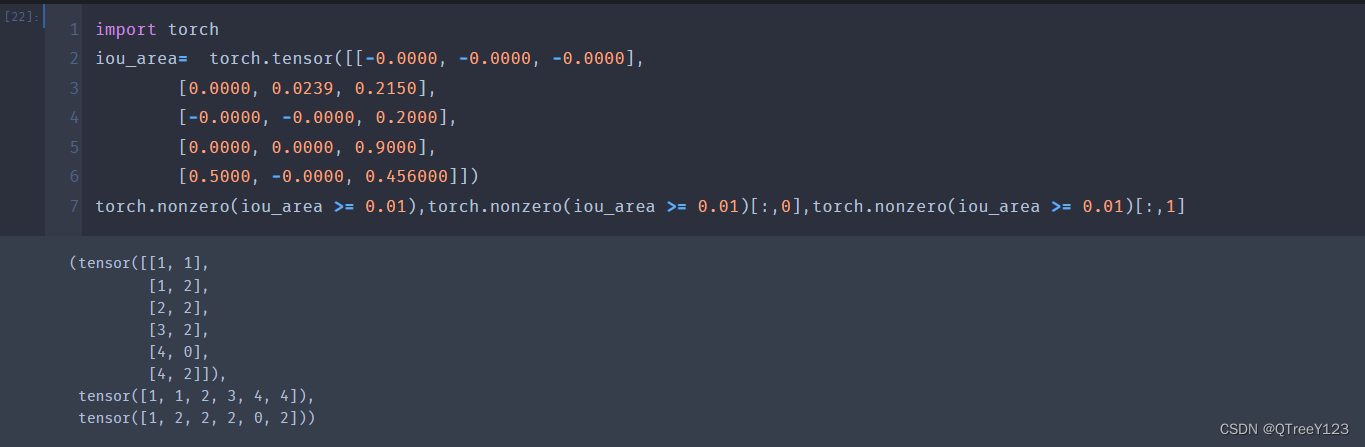
最左边:红色的字表示idx_gtbox,绿色的表示idx_gtbox对应的真实的标签!
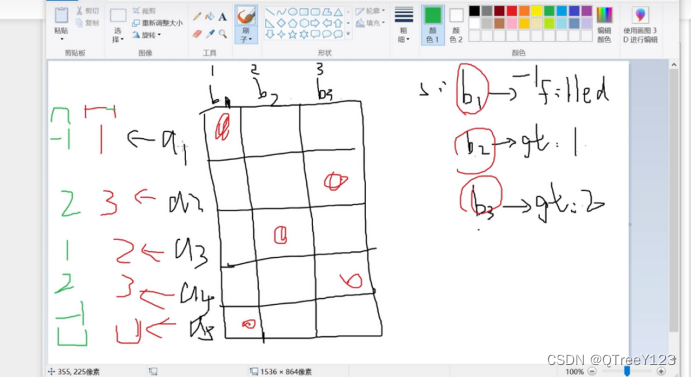
三:为什么需要填充?
因为当gtbox的类别个数不一样的时候,无法进行batch融合,需要填充类(-1,和四个随机坐标)进行填充。强行使他们的维度一致,这样就可以用批次来训练了
例如下图:左边的只有一个类别。右边有m个,所以左边需要填充m-1个负类别,坐标随机生成,因为负类的坐标是没用的。
所有项目代码+UI界面
视频,笔记和代码,以及注释都已经上传网盘,放在主页置顶文章


















 2107
2107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









