






在大规模语言模型的高效部署中,模型压缩技术至关重要。DeepSeek-V3 采用的 FP8 量化方案,通过创新的量化策略和高效的计算流程,在显著降低模型存储需求和计算资源占用的同时,保持了较高的精度。本文将深入剖析 DeepSeek-V3 的 FP8 量化技术,探讨其量化策略、计算公式、工程实现以及性能优化的关键细节,为读者揭示这一前沿技术的奥秘。
1. FP8 量化基础
1.1 FP8 格式与精度
FP8 是一种低精度浮点数格式,主要用于高效计算和存储。它有两种主要格式:E4M3 和 E5M2。其中,E4M3 格式包含 4 位指数和 3 位尾数,E5M2 格式包含 5 位指数和 2 位尾数。这两种格式的设计旨在平衡精度和计算效率。
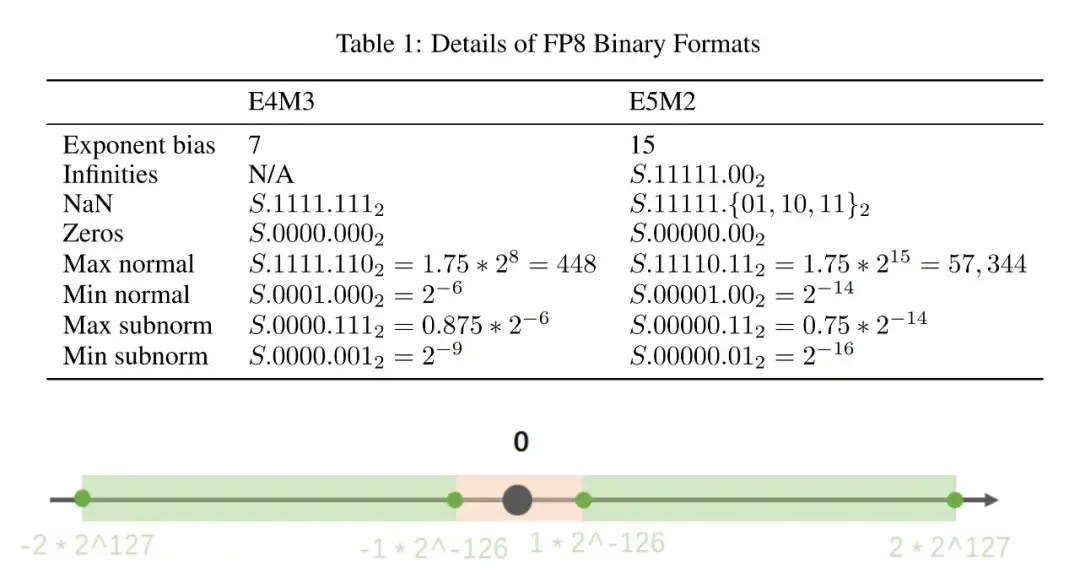
E4M3 格式:
-
指数位:4 位,偏置值为 7。
-
尾数位:3 位。
能表示的最大值约为 14.84,最小值约为 -14.84。
能表示的最小非零正数约为 0.03125。
该格式在处理动态范围较小但需要较高精度的场景时表现较好。
E5M2 格式:
-
指数位:5 位,偏置值为 15。
-
尾数位:2 位。
能表示的最大值约为 57344,最小值约为 -57344。
能表示的最小非零正数约为 0.0009765625。
该格式在处理动态范围较大的场景时表现较好,但精度相对较低。
在 DeepSeek-V3 中,所有 FP8 张量均采用 E4M3 格式,以获得更高的精度。这种格式在处理语言模型中的激活值和权重时,能够有效减少量化误差,同时保持较高的计算效率。
2. DeepSeek-V3 中的 FP8 量化方案
2.1 权重量化策略
在 DeepSeek-V3 中,权重量化采用了** Block-wise Quantization 策略**,将权重张量分割成大小为 128×128 的块,并为每个块分配独立的量化参数(缩放因子 s 和零点 z)。这种策略能够更好地适应权重数据的局部特征,减少量化误差。
量化参数计算:

量化过程:

反量化过程:

静态离线量化:
权重量化是离线预计算好的,即在模型训练完成后进行量化,并将量化参数存储起来。这种方式减少了推理时的计算开销,提高了推理效率。
2.2 激活量化策略
激活量化在 DeepSeek-V3 中采用了 Per-token-group Quantization 策略,以动态在线的方式进行量化。对于每个 token,在隐藏维度(hidden_dim)上每 128 个通道分为一组,并为每组计算独立的量化参数。
量化参数计算:

量化过程:

反量化过程:

动态在线量化:
激活量化是在推理过程中实时进行的,根据输入数据的特征动态调整量化参数。这种方式能够更好地适应不同的输入数据分布,减少量化误差。
分组粒度:

通过上述权重量化和激活量化策略,DeepSeek-V3 在保持较高精度的同时,显著提升了模型的存储和计算效率,为大规模语言模型的高效部署提供了有力支持。
3. FP8 量化计算流程
3.1 矩阵乘法与累加
在 DeepSeek-V3 中,FP8 量化矩阵的乘法与累加操作是模型推理的核心环节,其高效实现对整体性能至关重要。
矩阵乘法

累加操作
在矩阵乘法过程中,中间结果的累加操作同样重要。由于 FP8 的动态范围有限,累加过程中容易出现下溢(underflow)现象,即计算结果过小而无法被 FP8 精确表示。为了避免这一问题,DeepSeek-V3 采用了以下策略:
-
分块累加:将矩阵乘法的结果按块进行累加,每块包含 128 个元素。当累加到 128 个元素后,将结果转换为 FP32 格式,以避免下溢。
-
高精度累加器:在 CUDA Cores 中使用 FP32 精度的累加器来存储中间结果,确保累加过程的精度。
具体流程如下:
-
Tensor Core 计算:使用 Tensor Core 单元以 FP8 精度高效执行矩阵乘法和累加操作,中间结果存储在低精度累加器中。
-
转换为 FP32:每累加 128 个元素后,将这些 FP8 累加结果转换为 FP32 精度。
-
高精度累加:在 CUDA Cores 的 FP32 寄存器中进行高精度的累加操作,最终结果经过缩放因子反量化。
性能优化
通过上述策略,DeepSeek-V3 在保持较高精度的同时,显著提升了矩阵乘法和累加操作的效率。例如,在 NVIDIA Hopper 架构上,FP8 GEMM 操作的速度比 FP16 提升了 2−3 倍,具体数值依赖于不同的应用场景。
3.2 精度转换与反量化
在 FP8 量化计算过程中,精度转换与反量化是确保模型推理精度的关键步骤。通过合理的精度转换和反量化策略,DeepSeek-V3 能够在低精度计算的基础上恢复较高的精度,从而保证模型的性能。
精度转换
精度转换是指将低精度的 FP8 数据转换为更高精度的 FP32 数据。这一过程在矩阵乘法的中间结果累加阶段尤为重要,以避免下溢和精度损失。具体转换公式如下:

反量化
反量化是将量化后的数据恢复到原始精度的过程。在 DeepSeek-V3 中,权重和激活值的反量化公式分别为:

反量化策略
在实际应用中,反量化策略需要根据具体场景进行优化。例如,在矩阵乘法的最终结果反量化时,需要考虑缩放因子的动态调整,以适应不同的输入数据分布。此外,反量化后的数据可以直接用于后续的计算,或者进一步进行优化处理,以提高模型的推理精度。
性能与精度平衡
通过合理的精度转换和反量化策略,DeepSeek-V3 在保持较高计算效率的同时,显著减少了量化误差。例如,在某些应用场景中,反量化后的模型精度与原始 FP32 模型的差距小于 1%,这表明 FP8 量化方案在精度和效率之间取得了良好的平衡。
综上所述,FP8 量化计算流程在 DeepSeek-V3 中得到了高效实现,通过矩阵乘法与累加的优化以及精度转换与反量化的合理设计,显著提升了模型的存储和计算效率,同时保持了较高的推理精度。
4. 性能优化与硬件适配
4.1 GPU 加速机制
DeepSeek-V3 的 FP8 量化方案充分利用了 GPU 的强大计算能力,尤其是 NVIDIA Hopper 架构的特性,显著提升了模型的推理速度和效率。
Tensor Core 的高效利用:
NVIDIA Hopper 架构的 Tensor Core 单元对 FP8 计算提供了原生支持,能够高效执行 FP8 矩阵乘法和累加操作。DeepSeek-V3 通过将矩阵乘法分解为多个小块,并利用 Tensor Core 的并行计算能力,显著提高了计算效率。例如,每个 Tensor Core 可以处理 128×128 的矩阵块,每秒可执行超过 3.2 万亿次浮点运算(TFlops),这使得模型推理速度提升了数倍。
混合精度计算:
DeepSeek-V3 采用了混合精度计算策略,将 FP8 用于矩阵乘法的中间计算,而将结果转换为 FP32 进行高精度累加。这种策略既利用了 FP8 的高效计算能力,又避免了精度损失。例如,在矩阵乘法过程中,每累加 128 个 FP8 结果后,将其转换为 FP32 格式,然后在 CUDA Cores 的 FP32 寄存器中进行高精度累加,最终结果经过缩放因子反量化,恢复到较高的精度。
硬件特性适配:
DeepSeek-V3 的 FP8 量化方案针对 NVIDIA Hopper 架构进行了深度优化。例如,Hopper 架构的 Tensor Memory Accelerator (TMA) 单元能够高效地在全局内存和共享内存之间传输大型数据块,支持线程块之间的异步拷贝。DeepSeek-V3 利用这些特性,减少了数据传输的延迟,提高了整体计算效率。
4.2 内存与通信优化
内存和通信优化是提升大规模模型推理效率的关键环节。DeepSeek-V3 通过多种策略,显著减少了内存占用和通信开销。
内存占用优化:
-
量化存储:通过将权重和激活值量化为 FP8 格式,DeepSeek-V3 显著减少了模型的存储需求。例如,一个 100MB 的 FP32 模型在量化为 FP8 后,存储需求可减少到 25MB,节省了 75% 的存储空间。这种存储效率的提升对于大规模模型的部署尤为重要,尤其是在资源受限的设备上。
-
分块存储:DeepSeek-V3 采用了分块量化策略,将权重张量分割成 128×128 的块,并为每个块分配独立的量化参数。这种策略不仅减少了量化误差,还优化了内存布局,提高了内存访问效率。
通信优化:
-
分布式推理:在分布式推理场景中,DeepSeek-V3 通过优化通信协议和数据传输策略,减少了节点之间的通信开销。例如,通过将矩阵乘法分解为多个小块,并在多个 GPU 上并行执行,减少了数据传输的总量。此外,DeepSeek-V3 还利用 NVIDIA 的 NVLink 技术,实现了 GPU 之间的高速通信,进一步提高了分布式推理的效率。
-
异步通信:DeepSeek-V3 采用了异步通信机制,允许计算和通信操作同时进行,减少了等待时间。例如,在矩阵乘法的中间结果累加阶段,DeepSeek-V3 可以在 GPU 上并行执行多个小块的计算,同时将结果异步传输到其他 GPU,从而提高了整体计算效率。
通过上述 GPU 加速机制和内存与通信优化策略,DeepSeek-V3 在保持较高精度的同时,显著提升了模型的推理速度和效率,为大规模语言模型的高效部署提供了有力支持。
5、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

















 6399
6399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









