






Acrobot
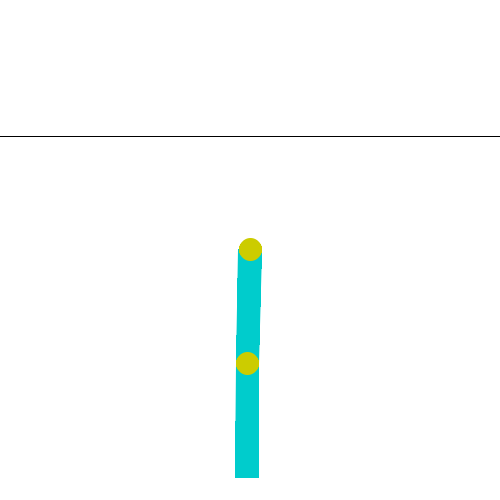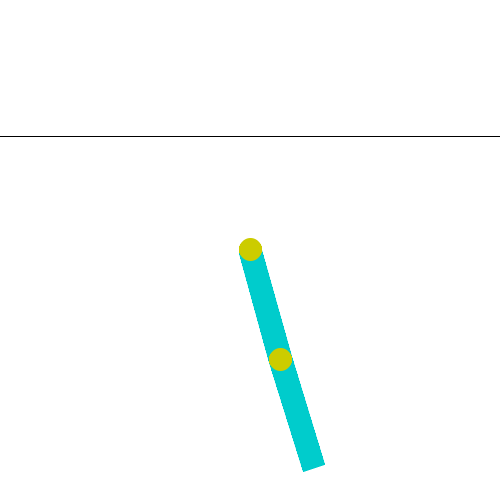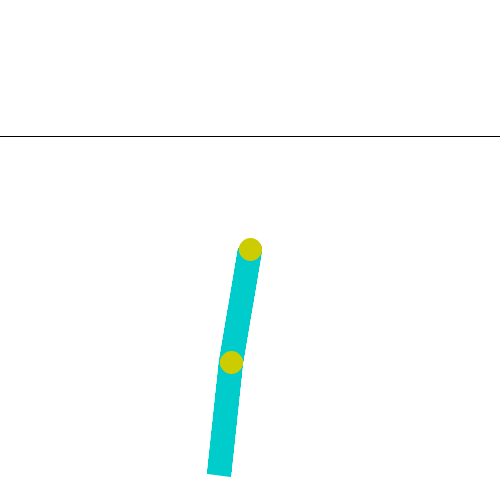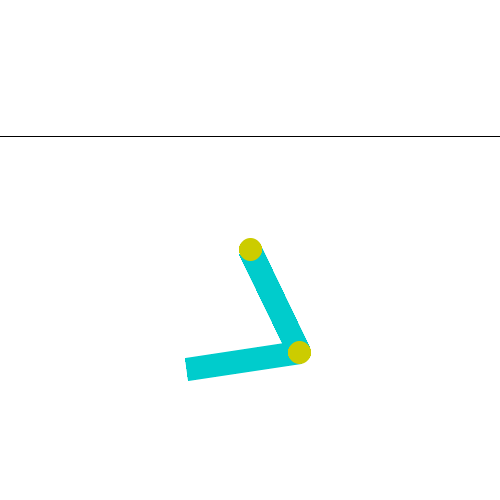
| Action Space |
|
| Observation Space |
|
| import |
|
Description
The Acrobot environment is based on Sutton’s work in “Generalization in Reinforcement Learning: Successful Examples Using Sparse Coarse Coding” and Sutton and Barto’s book. The system consists of two links connected linearly to form a chain, with one end of the chain fixed. The joint between the two links is actuated. The goal is to apply torques on the actuated joint to swing the free end of the linear chain above a given height while starting from the initial state of hanging downwards.
Acrobot环境基于Sutton在“强化学习中的泛化:使用稀疏粗编码的成功例子”以及Sutton和Barto的书中的工作。该系统由两个线性连接的链环组成,链环的一端固定。两个连杆之间的接头启动。目标是在致动关节上施加扭矩,以使线性链的自由端在给定高度以上摆动,同时从向下悬挂的初始状态开始。
As seen in the Gif: two blue links connected by two green joints. The joint in between the two links is actuated. The goal is to swing the free end of the outer-link to reach the target height (black horizontal line above system) by applying torque on the actuator.如Gif中所示:两个蓝色链接由两个绿色关节连接。两个连杆之间的接头启动。目标是通过在执行器上施加扭矩,摆动外连杆的自由端以达到目标高度(系统上方的黑色水平线)。
Action Space
The action is discrete, deterministic, and represents the torque applied on the actuated joint between the two links.该动作是离散的、确定性的,并且表示施加在两个连杆之间的致动关节上的扭矩。
| Num | Action | Unit |
|---|---|---|
| 0 | apply -1 torque to the actuated joint | torque (N m) |
| 1 | apply 0 torque to the actuated joint | torque (N m) |
| 2 | apply 1 torque to the actuated joint | torque (N m) |
Observation Space
The observation is a ndarray with shape (6,) that provides information about the two rotational joint angles as well as their angular velocities:观察是具有形状(6,)的ndarray,其提供关于两个旋转关节角度及其角速度的信息:
| Num | Observation | Min | Max |
|---|---|---|---|
| 0 | Cosine of | -1 | 1 |
| 1 | Sine of | -1 | 1 |
| 2 | Cosine of | -1 | 1 |
| 3 | Sine of | -1 | 1 |
| 4 | Angular velocity of | ~ -12.567 (-4 * pi) | ~ 12.567 (4 * pi) |
| 5 | Angular velocity of | ~ -28.274 (-9 * pi) | ~ 28.274 (9 * pi) |
where
-
theta1is the angle of the first joint, where an angle of 0 indicates the first link is pointing directly downwards.theta1是第一个关节的角度,其中角度为0表示第一个链接直接指向下方。 -
theta2is relative to the angle of the first link. An angle of 0 corresponds to having the same angle between the two links.θ2是相对于第一个连杆的角度。角度为0对应于两个连杆之间的角度相同
The angular velocities of theta1 and theta2 are bounded at ±4π, and ±9π rad/s respectively. A state of [1, 0, 1, 0, ..., ...] indicates that both links are pointing downwards.θ1和θ2的角速度分别以±4π和±9πrad/s为界。状态[1,0,1,0,…,…]表示两个链接都指向下方。
Rewards
The goal is to have the free end reach a designated target height in as few steps as possible, and as such all steps that do not reach the goal incur a reward of -1. Achieving the target height results in termination with a reward of 0. The reward threshold is -100.目标是让自由端在尽可能少的步骤中达到指定的目标高度,因此,所有未达到目标的步骤都会获得-1的奖励。达到目标高度将导致终止,奖励为0。奖励阈值为-100。
Starting State
Each parameter in the underlying state (theta1, theta2, and the two angular velocities) is initialized uniformly between -0.1 and 0.1. This means both links are pointing downwards with some initial stochasticity.基本状态下的每个参数(θ1、θ2和两个角速度)在-0.1和0.1之间均匀初始化。这意味着两个链接都指向下方,具有一些初始随机性。
Episode End
The episode ends if one of the following occurs:
-
Termination: The free end reaches the target height, which is constructed as:
-cos(theta1) - cos(theta2 + theta1) > 1.0 -
Truncation: Episode length is greater than 500 (200 for v0)如果出现以下情况之一,则该事件结束:
终止:自由端达到目标高度,其构造为:cos(theta1)-cos(theta2+theta1)>1.0
截断:剧集长度大于500(v0为200)
Arguments
No additional arguments are currently supported during construction.
import gymnasium as gym
env = gym.make('Acrobot-v1')
On reset, the options parameter allows the user to change the bounds used to determine the new random state.
By default, the dynamics of the acrobot follow those described in Sutton and Barto’s book Reinforcement Learning: An Introduction. However, a book_or_nips parameter can be modified to change the pendulum dynamics to those described in the original NeurIPS paper.
# To change the dynamics as described above env.unwrapped.book_or_nips = 'nips'
Version History
-
v1: Maximum number of steps increased from 200 to 500. The observation space for v0 provided direct readings of
theta1andtheta2in radians, having a range of[-pi, pi]. The v1 observation space as described here provides the sine and cosine of each angle instead. -
v0: Initial versions release (1.0.0) (removed from gymnasium for v1)
References
-
Sutton, R. S. (1996). Generalization in Reinforcement Learning: Successful Examples Using Sparse Coarse Coding. In D. Touretzky, M. C. Mozer, & M. Hasselmo (Eds.), Advances in Neural Information Processing Systems (Vol. 8). MIT Press. https://proceedings.neurips.cc/paper/1995/file/8f1d43620bc6bb580df6e80b0dc05c48-Paper.pdf
-
Sutton, R. S., Barto, A. G. (2018 ). Reinforcement Learning: An Introduction. The MIT Press.
Cart Pole

This environment is part of the Classic Control environments which contains general information about the environment.
| Action Space |
|
| Observation Space |
|
| import |
|
Description
This environment corresponds to the version of the cart-pole problem described by Barto, Sutton, and Anderson in “Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problem”. A pole is attached by an un-actuated joint to a cart, which moves along a frictionless track. The pendulum is placed upright on the cart and the goal is to balance the pole by applying forces in the left and right direction on the cart.
这种环境对应于Barto、Sutton和Anderson在《可以解决学习控制难题的神经元自适应元件》中描述的cart-pole问题。杆通过一个未驱动的接头连接到推车上,推车沿着无摩擦轨道移动。摆锤垂直放置在推车上,目的是通过在推车上施加左右方向的力来平衡杆。
Action Space
The action is a ndarray with shape (1,) which can take values {0, 1} indicating the direction of the fixed force the cart is pushed with.
-
0: Push cart to the left
-
1: Push cart to the right
Note: The velocity that is reduced or increased by the applied force is not fixed and it depends on the angle the pole is pointing. The center of gravity of the pole varies the amount of energy needed to move the cart underneath it该动作是一个形状为(1,)的ndarray,其取值为{0,1},表示推车所受固定力的方向。
0:向左推推车
1:向右推推车
Observation Space
The observation is a ndarray with shape (4,) with the values corresponding to the following positions and velocities:
| Num | Observation | Min | Max |
|---|---|---|---|
| 0 | Cart Position | -4.8 | 4.8 |
| 1 | Cart Velocity | -Inf | Inf |
| 2 | Pole Angle | ~ -0.418 rad (-24°) | ~ 0.418 rad (24°) |
| 3 | Pole Angular Velocity | -Inf | Inf |
Note: While the ranges above denote the possible values for observation space of each element, it is not reflective of the allowed values of the state space in an unterminated episode. Particularly:
-
The cart x-position (index 0) can be take values between
(-4.8, 4.8), but the episode terminates if the cart leaves the(-2.4, 2.4)range. -
The pole angle can be observed between
(-.418, .418)radians (or ±24°), but the episode terminates if the pole angle is not in the range(-.2095, .2095)(or ±12°)
Rewards
Since the goal is to keep the pole upright for as long as possible, a reward of +1 for every step taken, including the termination step, is allotted. The threshold for rewards is 475 for v1.由于目标是使杆尽可能长时间保持直立,因此每走一步(包括终止步骤)都会获得+1的奖励。v1的奖励阈值为475
Starting State
All observations are assigned a uniformly random value in (-0.05, 0.05)
Episode End
The episode ends if any one of the following occurs:
-
Termination: Pole Angle is greater than ±12°
-
Termination: Cart Position is greater than ±2.4 (center of the cart reaches the edge of the display)
-
Truncation: Episode length is greater than 500 (200 for v0)如果出现以下任何一种情况,则该事件结束:
终端:极角大于±12°
终止:推车位置大于±2.4(推车中心到达显示器边缘)
截断:剧集长度大于500(v0为200)
Arguments
import gymnasium as gym
gym.make('CartPole-v1')
On reset, the options parameter allows the user to change the bounds used to determine the new random state.
Pendulum

This environment is part of the Classic Control environments which contains general information about the environment.
| Action Space |
|
| Observation Space |
|
| import |
|
Description
The inverted pendulum swingup problem is based on the classic problem in control theory. The system consists of a pendulum attached at one end to a fixed point, and the other end being free. The pendulum starts in a random position and the goal is to apply torque on the free end to swing it into an upright position, with its center of gravity right above the fixed point.
The diagram below specifies the coordinate system used for the implementation of the pendulum’s dynamic equations.倒立摆摆摆动问题是在控制理论经典问题的基础上提出的。该系统由一端连接到固定点的钟摆组成,另一端是自由的。钟摆从一个随机的位置开始,目标是在自由端施加扭矩,使其摆动到垂直位置,重心正好在固定点上方。
下图规定了用于实现摆锤动力学方程的坐标系。

-
x-y: cartesian coordinates of the pendulum’s end in meters. -
theta: angle in radians. -
tau: torque inN m. Defined as positive counter-clockwise.
Action Space
The action is a ndarray with shape (1,) representing the torque applied to free end of the pendulum.
| Num | Action | Min | Max |
|---|---|---|---|
| 0 | Torque | -2.0 | 2.0 |
Observation Space
The observation is a ndarray with shape (3,) representing the x-y coordinates of the pendulum’s free end and its angular velocity.
| Num | Observation | Min | Max |
|---|---|---|---|
| 0 | x = cos(theta) | -1.0 | 1.0 |
| 1 | y = sin(theta) | -1.0 | 1.0 |
| 2 | Angular Velocity | -8.0 | 8.0 |
Rewards
The reward function is defined as:
r = -(theta2 + 0.1 * theta_dt2 + 0.001 * torque2)
where $ heta$ is the pendulum’s angle normalized between [-pi, pi] (with 0 being in the upright position). Based on the above equation, the minimum reward that can be obtained is -(pi2 + 0.1 * 82 + 0.001 * 22) = -16.2736044, while the maximum reward is zero (pendulum is upright with zero velocity and no torque applied).
Starting State
The starting state is a random angle in [-pi, pi] and a random angular velocity in [-1,1].
Episode Truncation
The episode truncates at 200 time steps.
Arguments
-
g: acceleration of gravity measured in (m s-2) used to calculate the pendulum dynamics. The default value is g = 10.0 .
import gymnasium as gym
gym.make('Pendulum-v1', g=9.81)
On reset, the options parameter allows the user to change the bounds used to determine the new random state.
Inverted Pendulum
This environment is part of the Mujoco environments which contains general information about the environment.
| Action Space |
|
| Observation Space |
|
| import |
|
Description
This environment is the cartpole environment based on the work done by Barto, Sutton, and Anderson in “Neuronlike adaptive elements that can solve difficult learning control problems”, just like in the classic environments but now powered by the Mujoco physics simulator - allowing for more complex experiments (such as varying the effects of gravity). This environment involves a cart that can moved linearly, with a pole fixed on it at one end and having another end free. The cart can be pushed left or right, and the goal is to balance the pole on the top of the cart by applying forces on the cart.
这种环境是基于Barto、Sutton和Anderson在“可以解决困难的学习控制问题的神经元自适应元件”中所做的工作的cartpole环境,就像在经典环境中一样,但现在由Mujoco物理模拟器提供动力,允许进行更复杂的实验(例如改变重力的影响)。这种环境包括一个可以线性移动的推车,一端固定一根杆子,另一端自由。推车可以向左或向右推动,目的是通过在推车上施加力来平衡推车顶部的杆子。
Action Space
The agent take a 1-element vector for actions.
The action space is a continuous (action) in [-3, 3], where action represents the numerical force applied to the cart (with magnitude representing the amount of force and sign representing the direction)智能体采用一个1元素向量进行操作。
动作空间是[-3,3]中的连续(动作),其中动作表示施加到推车上的数值力(大小表示力的大小,符号表示方向)
| Num | Action | Control Min | Control Max | Name (in corresponding XML file) | Joint | Unit |
|---|---|---|---|---|---|---|
| 0 | Force applied on the cart | -3 | 3 | slider | slide | Force (N) |
Observation Space
The state space consists of positional values of different body parts of the pendulum system, followed by the velocities of those individual parts (their derivatives) with all the positions ordered before all the velocities.
The observation is a ndarray with shape (4,) where the elements correspond to the following:
| Num | Observation | Min | Max | Name (in corresponding XML file) | Joint | Unit |
|---|---|---|---|---|---|---|
| 0 | position of the cart along the linear surface | -Inf | Inf | slider | slide | position (m) |
| 1 | vertical angle of the pole on the cart | -Inf | Inf | hinge | hinge | angle (rad) |
| 2 | linear velocity of the cart | -Inf | Inf | slider | slide | velocity (m/s) |
| 3 | angular velocity of the pole on the cart | -Inf | Inf | hinge | hinge | anglular velocity (rad/s) |
Rewards
The goal is to make the inverted pendulum stand upright (within a certain angle limit) as long as possible - as such a reward of +1 is awarded for each timestep that the pole is upright.目标是使倒立摆尽可能长时间地直立(在一定的角度限制内)——因此,杆直立的每一步都会获得+1的奖励。
Starting State
All observations start in state (0.0, 0.0, 0.0, 0.0) with a uniform noise in the range of [-0.01, 0.01] added to the values for stochasticity.
Episode End
The episode ends when any of the following happens:
-
Truncation: The episode duration reaches 1000 timesteps.
-
Termination: Any of the state space values is no longer finite.
-
Termination: The absolute value of the vertical angle between the pole and the cart is greater than 0.2 radian.
Arguments
No additional arguments are currently supported.
import gymnasium as gym
env = gym.make('InvertedPendulum-v4')
There is no v3 for InvertedPendulum, unlike the robot environments where a v3 and beyond take gymnasium.make kwargs such as xml_file, ctrl_cost_weight, reset_noise_scale, etc.
import gymnasium as gym
env = gym.make('InvertedPendulum-v2')
Version History
-
v4: All MuJoCo environments now use the MuJoCo bindings in mujoco >= 2.1.3
-
v3: Support for
gymnasium.makekwargs such asxml_file,ctrl_cost_weight,reset_noise_scale, etc. rgb rendering comes from tracking camera (so agent does not run away from screen) -
v2: All continuous control environments now use mujoco-py >= 1.50
-
v1: max_time_steps raised to 1000 for robot based tasks (including inverted pendulum)
-
v0: Initial versions release (1.0.0)
Inverted Double Pendulum
This environment is part of the Mujoco environments which contains general information about the environment.
| Action Space |
|
| Observation Space |
|
| import |
|
Description
这种环境源于控制理论,建立在基于Barto、Sutton和Anderson在“可以解决困难的学习控制问题的神经元自适应元件”中所做的工作的cartpole环境之上,由Mujoco物理模拟器提供动力,允许进行更复杂的实验(如改变重力或约束的影响)。这种环境包括一个可以线性移动的推车,其上固定有一根杆子,第二根杆子固定在第一根杆子的另一端(第二根棍子是唯一一个有自由端的杆子)。推车可以向左或向右推动,目的是通过在推车上施加连续的力来平衡第一杆顶部的第二杆,第一杆依次位于推车顶部。
Action Space
The agent take a 1-element vector for actions. The action space is a continuous (action) in [-1, 1], where action represents the numerical force applied to the cart (with magnitude representing the amount of force and sign representing the direction)
| Num | Action | Control Min | Control Max | Name (in corresponding XML file) | Joint | Unit |
|---|---|---|---|---|---|---|
| 0 | Force applied on the cart | -1 | 1 | slider | slide | Force (N) |
Observation Space
The state space consists of positional values of different body parts of the pendulum system, followed by the velocities of those individual parts (their derivatives) with all the positions ordered before all the velocities.
The observation is a ndarray with shape (11,) where the elements correspond to the following:
| Num | Observation | Min | Max | Name (in corresponding XML file) | Joint | Unit |
|---|---|---|---|---|---|---|
| 0 | position of the cart along the linear surface | -Inf | Inf | slider | slide | position (m) |
| 1 | sine of the angle between the cart and the first pole | -Inf | Inf | sin(hinge) | hinge | unitless |
| 2 | sine of the angle between the two poles | -Inf | Inf | sin(hinge2) | hinge | unitless |
| 3 | cosine of the angle between the cart and the first pole | -Inf | Inf | cos(hinge) | hinge | unitless |
| 4 | cosine of the angle between the two poles | -Inf | Inf | cos(hinge2) | hinge | unitless |
| 5 | velocity of the cart | -Inf | Inf | slider | slide | velocity (m/s) |
| 6 | angular velocity of the angle between the cart and the first pole | -Inf | Inf | hinge | hinge | angular velocity (rad/s) |
| 7 | angular velocity of the angle between the two poles | -Inf | Inf | hinge2 | hinge | angular velocity (rad/s) |
| 8 | constraint force - 1 | -Inf | Inf | Force (N) | ||
| 9 | constraint force - 2 | -Inf | Inf | Force (N) | ||
| 10 | constraint force - 3 | -Inf | Inf | Force (N) |
There is physical contact between the robots and their environment - and Mujoco attempts at getting realistic physics simulations for the possible physical contact dynamics by aiming for physical accuracy and computational efficiency.
There is one constraint force for contacts for each degree of freedom (3). The approach and handling of constraints by Mujoco is unique to the simulator and is based on their research. Once can find more information in their documentation or in their paper “Analytically-invertible dynamics with contacts and constraints: Theory and implementation in MuJoCo”.
Rewards
The reward consists of two parts:
-
alive_bonus: The goal is to make the second inverted pendulum stand upright (within a certain angle limit) as long as possible - as such a reward of +10 is awarded for each timestep that the second pole is upright.
-
distance_penalty: This reward is a measure of how far the tip of the second pendulum (the only free end) moves, and it is calculated as 0.01 * x2 + (y - 2)2, where x is the x-coordinate of the tip and y is the y-coordinate of the tip of the second pole.
-
velocity_penalty: A negative reward for penalising the agent if it moves too fast 0.001 * v12 + 0.005 * v2 2
The total reward returned is reward = alive_bonus - distance_penalty - velocity_penalty
Starting State
All observations start in state (0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0) with a uniform noise in the range of [-0.1, 0.1] added to the positional values (cart position and pole angles) and standard normal force with a standard deviation of 0.1 added to the velocity values for stochasticity.
Episode End
The episode ends when any of the following happens:
1.Truncation: The episode duration reaches 1000 timesteps. 2.Termination: Any of the state space values is no longer finite. 3.Termination: The y_coordinate of the tip of the second pole is less than or equal to 1. The maximum standing height of the system is 1.196 m when all the parts are perpendicularly vertical on top of each other).
Arguments
No additional arguments are currently supported.
import gymnasium as gym
env = gym.make('InvertedDoublePendulum-v4')
There is no v3 for InvertedPendulum, unlike the robot environments where a v3 and beyond take gymnasium.make kwargs such as xml_file, ctrl_cost_weight, reset_noise_scale, etc.
import gymnasium as gym
env = gym.make('InvertedDoublePendulum-v2')
















 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









