






在本文中,将展示如何创建自己的 RAG 数据集,该数据集包含任何语言的文档的上下文、问题和答案。
检索增强生成 (RAG) [1] 是一种允许 LLM 访问外部知识库的技术。
通过上传 PDF 文件并将其存储在矢量数据库中,我们可以通过矢量相似性搜索检索这些知识,然后将检索到的文本作为附加上下文插入到 LLM 提示中。
这为LLM提供了新的知识,并减少了LLM编造事实(幻觉)的可能性。
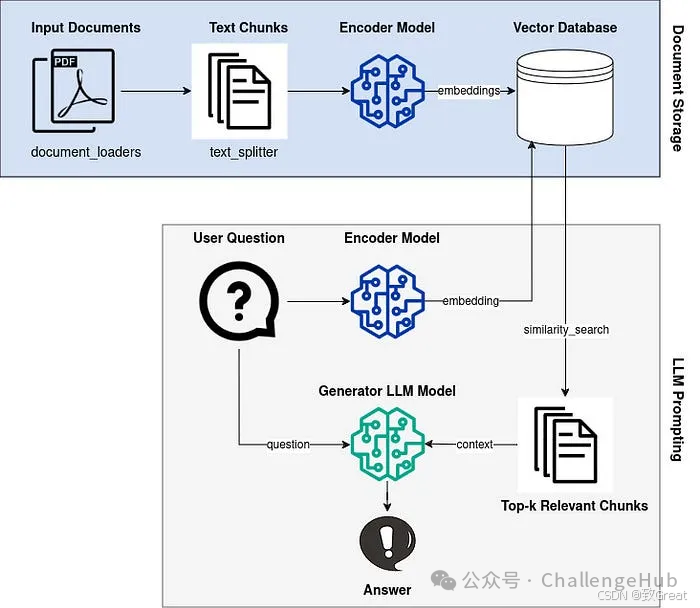
RAG 流程概述,对于文档存储:输入文档 -> 文本块 -> 编码器模型 -> 向量数据库,对于 LLM 提示:用户问题 -> 编码器模型 -> 向量数据库 -> 前 k 个相关块 -> 生成器 LLM 模型,然后,LLM 使用检索到的上下文回答问题。
然而,我们需要在 RAG 流程中设置许多参数,研究人员也一直在提出新的改进建议。我们如何知道应该选择哪些参数以及哪些方法可以真正提高我们特定用例的性能?
这就是为什么我们需要一个validation/dev/test数据集来评估我们的 RAG 管道。数据集应该来自我们感兴趣的领域和我们想要使用的语言。
使用 VLLM 部署本地 LLM
首先,我们要建立并运行本地大模型。
我使用VLLM设置了一个与 OpenAI 兼容的 LLM 服务,其中包含量化的Llama-3.2–3B-Instruct。确保你使用的 LLM 已经针对你想要使用的语言进行过训练。
使用 Docker 和 VLLM 部署本地 LLM 非常简单:
使用Docker:
docker run --runtime nvidia --gpus all \ -v ~/.cache/huggingface:/root/.cache/huggingface \ -- env "HUGGING_FACE_HUB_TOKEN=<secret>" \ -p 8000:8000 \ --ipc=host \ vllm/vllm-openai:latest \ --model AMead10/Llama-3.2-3B-Instruct-AWQ \ --quantization awq \ --max-model-len 2048
使用Docker Compose:
services: vllm: image: vllm/vllm-openai:latest command: ["--model", "AMead10/Llama-3.2-3B-Instruct-AWQ", "--max-model-len", "2048", "--quantization", "awq"] ports: - 8000:8000 volumes: - ~/.cache/huggingface:/root/.cache/huggingface environment: - "HUGGING_FACE_HUB_TOKEN=<secret>" deploy: resources: reservations: devices: - driver: nvidia count: 1 capabilities: [gpu]
现在我们可以将本地的 LLM 与官方 OpenAI Python SDK 一起使用。
如果我们想使用官方 OpenAI 模型,只需更改base_url、api_key和model变量。
%pip install openai from openai import OpenAI client = OpenAI( base_url= "http://localhost:8000/v1" , api_key= "None" , ) chat_completion = client.chat.completions.create( messages=[ { "role" : "user" , "content" : "Say this is a test" , } ], model= "AMead10/Llama-3.2-3B-Instruct-AWQ" , )
让我们进行快速的健全性检查,看看一切是否按预期进行:
`print(chat_completion.choices[ 0 ].message.content)`
“这似乎是一个测试。有什么具体的事情你想测试或讨论吗?我可以帮你。”
创建 RAG 评估数据集
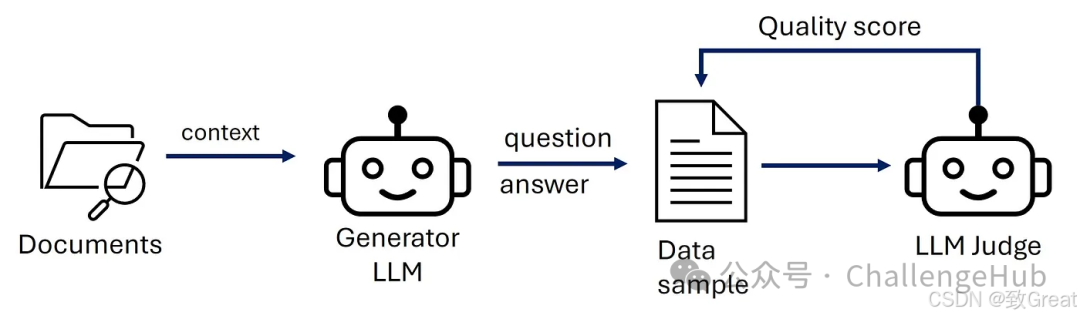
我们加载文档并将上下文传递给生成器 LLM,生成器会生成问题和答案。问题、答案和上下文是传递给 LLM 评委的一个数据样本。然后,LLM 评委会生成质量分数,该分数可用于过滤掉不良样本。自动从文档生成 RAG 评估数据样本的工作流程。图片由作者提供 自动生成 RAG 数据集的基本工作流程从从文档(例如 PDF 文件)读取我们的知识库开始。
然后我们要求生成器 LLM从给定的文档上下文生成问答对。
最后,我们使用评委 LLM进行质量控制。LLM 将为每个问答上下文样本打分,我们可以使用该分数来过滤掉不良样本。
为什么不使用像Ragas这样的框架来为 RAG 生成合成测试集?因为 Ragas 内部使用的是英语 LLM 提示。目前无法将 Ragas 与非英语文档一起使用。
我在本文中使用了 OpenAI 指南“RAG 评估” [2] 作为代码的基础。不过,我尝试简化他们的示例代码,并根据一些研究结果更改了评估 [3、4、5]。
读取文件
我们将使用 LangChain 读取包含所有文件的文件夹。
首先,我们需要安装所有必要的软件包。LangChain的 DirectoryLoader 使用非结构化库来读取各种文件类型。在本文中,我将仅读取 PDF,以便我们可以安装较小版本的unstructured。
pip install langchain==0.3.6 langchain-community==0.3.4 unstructured[pdf]==0.16.3 tqdm
现在我们可以读取数据文件夹以获取LangChain文档。以下代码首先从文件夹中加载所有PDF文件,然后将它们分块为相对较大的 2000 个块。
from langchain_text_splitters.character import RecursiveCharacterTextSplitter from langchain_community.document_loaders.directory import DirectoryLoader loader = DirectoryLoader("/path/to/data/folder", glob="**/*.pdf", show_progress=True) docs = loader.load() text_splitter = RecursiveCharacterTextSplitter( chunk_size=2000, chunk_overlap=200, add_start_index=True, separators=["\n\n", "\n", ".", " ", ""], ) docs_processed = [] for doc in docs: docs_processed.extend(text_splitter.split_documents([doc]))
结果是docs_processed包含类型的项目的列表Document。每个文档都有一些metadata和实际的page_content。
此文档列表是我们的知识库,我们将根据其上下文创建问答对page_content。
生成问答上下文样本
使用 OpenAI 客户端和我们之前创建的模型,我们首先编写一个生成器函数来从我们的文档中创建问题和答案。
def qa_generator_llm(context: str, client: OpenAI, model: str = "AMead10/Llama-3.2-3B-Instruct-AWQ"): generation_prompt = """ Your task is to write a factoid question and an answer given a context. Your factoid question should be answerable with a specific, concise piece of factual information from the context. Your factoid question should be formulated in the same style as questions users could ask in a search engine. This means that your factoid question MUST NOT mention something like "according to the passage" or "context". Provide your answer as follows: Output::: Factoid question: (your factoid question) Answer: (your answer to the factoid question) Now here is the context. Context: {context}\n Output:::""" chat_completion = client.chat.completions.create( messages=[ { "role": "system", "content": "You are a question-answer pair generator." }, { "role": "user", "content": generation_prompt.format(context=context), } ], model=model, temperature=0.5, top_p=0.99, max_tokens=500 ) return chat_completion.choices[0].message.content
如果我们想使用英语以外的语言,我们将需要翻译generation_prompt(和系统指令)。
接下来,我们只需循环遍历知识库中的所有文档块,并为每个块生成一个问题和一个答案。
from tqdm.auto import tqdm outputs = [] for doc in tqdm(docs_processed): # Generate QA couple output_QA = qa_generator_llm(doc.page_content, client) try: question = output_QA.split("Factoid question: ")[-1].split("Answer: ")[0] answer = output_QA.split("Answer: ")[-1] assert len(answer) < 500, "Answer is too long" outputs.append( { "context": doc.page_content, "question": question, "answer": answer, "source_doc": doc.metadata["source"], } ) except Exception as e: print(e)
根据我们拥有的 PDF 文件数量,这可能需要一段时间。如有必要,请不要忘记翻译字符串output_QA.split。
为了生成 RAG 评估数据集,我使用了一份来自欧盟的关于欧盟 AI 法案监管的 PDF (根据CC BY 4.0许可)。这是我生成的原始outputs数据集:
[{'context': 'Official Journal of the European Union\n\n2024/1689\n\nREGULATION (EU) 2024/1689 OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL\n\nof 13 June 2024\n\nlaying down harmonised rules on artificial intelligence and amending Regulations (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 and (EU) 2019/2144 and Directives 2014/90/EU, (EU) 2016/797 and (EU) 2020/1828 (Artificial Intelligence Act)\n\n(Text with EEA relevance)\n\nTHE EUROPEAN PARLIAMENT AND THE COUNCIL OF THE EUROPEAN UNION,\n\nHaving regard to the Treaty on the Functioning of the European Union, and in particular Articles 16 and 114 thereof,\n\nHaving regard to the proposal from the European Commission,\n\nAfter transmission of the draft legislative act to the national parliaments,\n\nHaving regard to the opinion of the European Economic and Social Committee (1),\n\nHaving regard to the opinion of the European Central Bank (2),\n\nHaving regard to the opinion of the Committee of the Regions (3),\n\nActing in accordance with the ordinary legislative procedure (4),\n\nWhereas:\n\n(1)', 'question': 'What is the date on which Regulation (EU) 2024/1689 of the European Parliament and of the Council was laid down?\n', 'answer': '13 June 2024', 'source_doc': 'documents/OJ_L_202401689_EN_TXT.pdf'}, {'context': 'Having regard to the opinion of the Committee of the Regions (3),\n\nActing in accordance with the ordinary legislative procedure (4),\n\nWhereas:\n\n(1)\n\nThe purpose of this Regulation is to improve the functioning of the internal market by laying down a uniform legal framework in particular for the development, the placing on the market, the putting into service and the use of artificial intelligence systems (AI systems) in the Union, in accordance with Union values, to promote the uptake of human centric and trustworthy artificial intelligence (AI) while ensuring a high level of protection of health, safety, fundamental rights as enshrined in the Charter of Fundamental Rights of the European Union (the ‘Charter’), including democracy, the rule of law and environmental protection, to protect against the harmful effects of AI systems in the Union, and to support innovation. This Regulation ensures the free movement, cross-border, of AI-based goods and services, thus preventing Member States from imposing restrictions on the development, marketing and use of AI systems, unless explicitly authorised by this Regulation.\n\n(2)\n\nThis Regulation should be applied in accordance with the values of the Union enshrined as in the Charter, facilitating the protection of natural persons, undertakings, democracy, the rule of law and environmental protection, while boosting innovation and employment and making the Union a leader in the uptake of trustworthy AI.\n\n(3)', 'question': 'What is the purpose of the proposed Regulation on the development, placing on the market, putting into service, and use of artificial intelligence systems in the Union?\n', 'answer': 'To improve the functioning of the internal market by laying down a uniform legal framework for the development, placing on the market, putting into service, and use of artificial intelligence systems in the Union.', 'source_doc': 'documents/OJ_L_202401689_EN_TXT.pdf'}, {'context': '(3)\n\nAI systems can be easily deployed in a large variety of sectors of the economy and many parts of society, including across borders, and can easily circulate throughout the Union. Certain Member States have already explored the adoption of national rules to ensure that AI is trustworthy and safe and is developed and used in accordance with fundamental rights obligations. Diverging national rules may lead to the fragmentation of the internal market and may decrease legal certainty for operators that develop, import or use AI systems. A consistent and high level of protection throughout the Union should therefore be ensured in order to achieve trustworthy AI, while divergences hampering the free circulation, innovation, deployment and the uptake of AI systems and related products and services within the internal market should be prevented by laying down uniform obligations for operators and\n\n(1) (2) (3) (4)\n\nOJ C 517, 22.12.2021, p. 56. OJ C 115, 11.3.2022, p. 5. OJ C 97, 28.2.2022, p. 60. Position of the European Parliament of 13 March 2024 (not yet published in the Official Journal) and decision of the Council of 21 May 2024.\n\nELI: http://data.europa.eu/eli/reg/2024/1689/oj\n\nEN L series\n\n12.7.2024\n\n1/144\n\nEN\n\n2/144\n\n(4)\n\n(5)\n\n(6)\n\n(7)\n\n(8)\n\n(5) (6)\n\nOJ L, 12.7.2024', 'question': 'What is the official journal number for the regulation related to trustworthy AI, as of 12.7.2024?\n', 'answer': '(4)', 'source_doc': 'documents/OJ_L_202401689_EN_TXT.pdf'}, ... ]
过滤掉错误的问答对
接下来,我们使用LLM 作为评判者,自动过滤掉坏样本。
当使用 LLM 学位作为评估样本质量的评判标准时,最好使用与生成样本时不同的模型,因为存在自我偏好偏差[6] —— 你不会给自己的论文评分,对吧?
在评判我们生成的问题和答案时,我们可以使用很多可能的提示。
为了构建我们的提示,我们可以使用G-Eval论文 [3]中的一个结构:
-
我们从任务介绍
( task introduction)开始 -
我们提出了评估标准
(evaluation criteria) -
我们希望模型能够进行思维链
(CoT)推理 [7],以提高其性能 -
我们最后要求总分
对于评估标准,我们可以使用一个列表,其中每个标准如果得到满足就会加一分。
评估标准应确保问题、答案和上下文相互契合、合理。
以下是 OpenAI RAG 评估手册中的两个评估标准 [2]:
-
依据性:是否可以从给定的背景来回答该问题?
-
独立:这个问题不需要任何背景就能理解吗?(为了避免出现这样的问题"What is the name of the function used in this guide?")
RAGAS 论文 [5] 中还有另外两个评估标准:
-
忠实:答案应基于给定的背景
-
答案相关性:答案应该解决实际提出的问题
我们可以尝试添加更多标准或更改我使用的标准文本。
该judge_llm()函数会批评问题、答案和上下文样本,并在最后得出总体评分:
def judge_llm( context: str, question: str, answer: str, client: OpenAI, model: str = "AMead10/Llama-3.2-3B-Instruct-AWQ", ): critique_prompt = """ You will be given a question, answer, and a context. Your task is to provide a total rating using the additive point scoring system described below. Points start at 0 and are accumulated based on the satisfaction of each evaluation criterion: Evaluation Criteria: - Groundedness: Can the question be answered from the given context? Add 1 point if the question can be answered from the context - Stand-alone: Is the question understandable free of any context, for someone with domain knowledge/Internet access? Add 1 point if the question is independent and can stand alone. - Faithfulness: The answer should be grounded in the given context. Add 1 point if the answer can be derived from the context - Answer Relevance: The generated answer should address the actual question that was provided. Add 1 point if the answer actually answers the question Provide your answer as follows: Answer::: Evaluation: (your rationale for the rating, as a text) Total rating: (your rating, as a number between 0 and 4) You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer. Now here are the question, answer, and context. Question: {question}\n Answer: {answer}\n Context: {context}\n Answer::: """ chat_completion = client.chat.completions.create( messages=[ {"role": "system", "content": "You are a neutral judge."}, { "role": "user", "content": critique_prompt.format( question=question, answer=answer, context=context ), }, ], model=model, temperature=0.1, top_p=0.99, max_tokens=800 ) return chat_completion.choices[0].message.content
现在我们循环遍历生成的数据集并批评每个样本:
for output in tqdm(outputs): try: evaluation = judge_llm( context=output["context"], question=output["question"], answer=output["answer"], client=client, ) score, eval = ( int(evaluation.split("Total rating: ")[-1].strip()), evaluation.split("Total rating: ")[-2].split("Evaluation: ")[1], ) output.update( { "score": score, "eval": eval } ) except Exception as e: print(e)
让我们过滤掉所有坏样本。
由于生成的数据集将成为评估目的的基本事实,因此我们只应允许非常高质量的数据样本。这就是为什么我决定只保留得分最高的样本。
dataset = [doc for doc in outputs if doc["score"] >= 4]
以下是我们最终的 RAG 评估数据集(以 Pandas DataFrame 格式):
import pandas as pd pd.set_option("display.max_colwidth", 200) df = pd.DataFrame(dataset) display(df)
我们生成的英语 RAG 评估数据集的可视化,包含以下列:上下文、问题、答案、源文档、分数和评估。
保存数据集
我们可以将 Pandas DataFrame 转换为 Hugging Face 数据集。然后,我们可以将其保存到磁盘并在需要时加载它。
%pip install datasets==3.0.2 # save from datasets import Dataset dataset = Dataset.from_pandas(df, split="test") dataset.save_to_disk("path/to/dataset/directory") # load from datasets import load_dataset dataset = load_dataset("path/to/dataset/directory")
我们还可以将数据集上传到Hugging Face Hub。
实验结论
从文档集合中自动创建 RAG 评估数据集非常简单。我们所需要的只是 LLM 生成器的提示、LLM 评委的提示,以及中间的一些 Python 代码。
要更改 RAG 评估数据集的域,我们只需交换提供给的文档DirectoryLoader。文档不必是 PDF 文件,也可以是 CSV 文件、markdown 文件等。
要更改我们的 RAG 评估数据集的语言,我们只需将 LLM 提示从英语翻译成另一种语言。
如果生成的数据样本不足以满足我们的用例,我们可以尝试修改提示。此外,使用更大、更好的 LLM 将提高数据集的质量。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









