






-
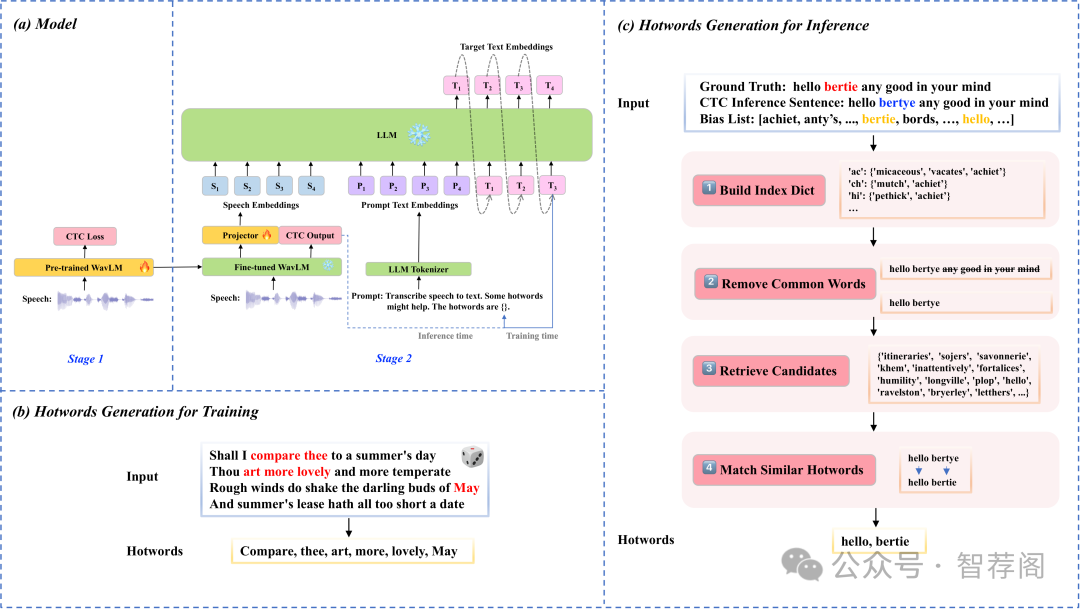
CTC-Assisted LLM-Based Contextual ASR
-
An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models
-
NatureLM-audio: an Audio-Language Foundation Model for Bioacoustics
-
Open-World Task and Motion Planning via Vision-Language Model Inferred Constraints
-
Hidden in Plain Sight: Evaluating Abstract Shape Recognition in Vision-Language Models
1.CTC-Assisted LLM-Based Contextual ASR
Authors:Guanrou Yang, Ziyang Ma, Zhifu Gao, Shiliang Zhang, Xie Chen
https://arxiv.org/abs/2411.06437
论文摘要
Contextual ASR or hotword customization holds substan tial practical value. Despite the impressive performance of current end-to-end (E2E) automatic speech recognition (ASR) systems, they often face challenges in accurately recognizing rare words. Typical E2E contextual ASR mod els commonly feature complex architectures and decoding mechanisms, limited in performance and susceptible to in terference from distractor words. With large language model (LLM)-based ASR models emerging as the new mainstream, we propose a CTC-Assisted LLM-Based Contextual ASR model with an efficient filtering algorithm. By using coarse CTC decoding results to filter potential relevant hotwords and incorporating them into LLM prompt input, our model attains WER/B-WER of 1.27%/3.67% and 2.72%/8.02% on the Librispeech test-clean and test-other sets targeting on recognizing rare long-tail words, demonstrating significant improvements compared to the baseline LLM-based ASR model, and substantially surpassing other related work. More remarkably, with the help of the large language model and proposed filtering algorithm, our contextual ASR model still performs well with 2000 biasing words.
论文简评
这篇论文提出了一种通过利用粗粒度CTC解码结果进行过滤的上下文ASR模型,旨在提高对罕见单词的识别准确性。该模型在Librispeech数据集上的表现优于基准模型,特别是在WER和B-WER方面。实验结果显示,该方法显著提升了ASR性能。此外,将大语言模型与CTC编码相结合的研究方向,在当前的上下文ASR领域具有一定的创新和实用性。总的来说,该研究为解决罕见长尾词识别问题提供了新的思路,并有望推动这一领域的进一步发展。
2.An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models
Authors:Fatemeh Shiri, Xiao-Yu Guo, Mona Golestan Far, Xin Yu, Gholamreza Haffari, Yuan-Fang Li
https://arxiv.org/abs/2411.06048
论文摘要
Large Multimodal Models (LMMs) have achieved strong performance across a range of vision and language tasks. However, their spatial reasoning capabilities are under investigated. In this paper, we construct a novel VQA dataset, Spatial-MM, to compre hensively study LMMs’ spatial understanding and reasoning capabilities. Our analyses on object-relationship and multi-hop reasoning re veal several important findings. Firstly, bound ing boxes and scene graphs, even synthetic ones, can significantly enhance LMMs’ spa tial reasoning. Secondly, LMMs struggle more with questions posed from the human perspec tive than the camera perspective about the im age. Thirdly, chain of thought (CoT) prompt ing does not improve model performance on complex multi-hop questions involving spa tial relations. Lastly, our perturbation analysis on GQA-spatial reveals that LMMs are much stronger at basic object detection than complex spatial reasoning. We believe our benchmark dataset and in-depth analyses can spark further research on LMMs spatial reasoning.
论文简评
这篇论文的主要贡献在于引入了Spatial-MM数据集来评估大规模多模态模型(LMM)的空间推理能力。通过分析LMM在空间理解方面的表现,这篇论文揭示了与相机视角相比,LMM在处理人类视角问题时的困难,以及链式思考提示对解决复杂多步推理问题的帮助有限。研究发现,尽管边界框和场景图能够增强空间推理能力,但当前的LMM通常更擅长基本对象检测而非高级空间推理,而在处理复杂空间推理任务时存在不足。
论文的关键观点是:首先,该文为从不同角度探索空间推理的重要性提供了基础;其次,其结论为未来研究方向提供了一定的指导意义,即需要进一步优化LMM的性能以满足更复杂的空间推理需求。总的来说,这篇论文不仅填补了现有关于LMM空间推理能力研究的空白,而且对相关领域的发展具有重要的启示作用。

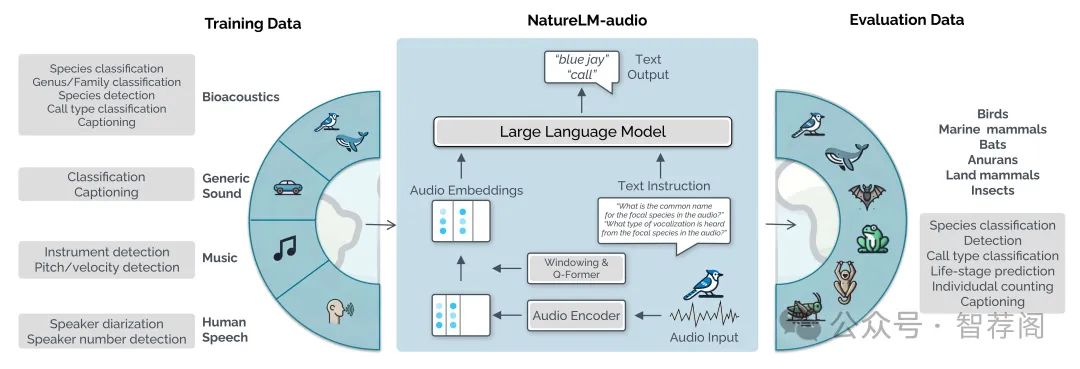
3.NatureLM-audio: an Audio-Language Foundation Model for Bioacoustics
Authors:David Robinson, Marius Miron, Masato Hagiwara, Olivier Pietquin
https://arxiv.org/abs/2411.07186
论文摘要
Large language models (LLMs) prompted with text and audio represent the state of the art in various auditory tasks, including speech, music, and general audio, showing emergent abilities on unseen tasks. However, these capabilities have yet to be fully demonstrated in bioacoustics tasks, such as detecting animal vocaliza tions in large recordings, classifying rare and endangered species, and labeling context and behavior—tasks that are crucial for conservation, biodiversity mon itoring, and the study of animal behavior. In this work, we present NatureLM audio, the first audio-language foundation model specifically designed for bioa coustics. Our carefully curated training dataset comprises text-audio pairs span ning a diverse range of bioacoustics, speech, and music data, designed to address the challenges posed by limited annotated datasets in the field. We demonstrate successful transfer of learned representations from music and speech to bioacous tics, and our model shows promising generalization to unseen taxa and tasks. Im portantly, we test NatureLM-audio on a novel benchmark (BEANS-Zero) and it sets the new state of the art (SotA) on several bioacoustics tasks, including zero shot classification of unseen species. To advance bioacoustics research, we also open-source the code for generating training and benchmark data, as well as for training the model.
论文简评
NatureLM-audio是阿里巴巴云研发的一项创新成果,基于大型语言模型设计了一种针对生物声学任务的独特音频语言基础模型。该研究旨在解决生物声学领域的一个重要问题:如何从音乐和语音中学习到生物声学知识。NatureLM-audio不仅展示了其在零样本分类方面的强大性能,且在不同物种的表现也令人印象深刻,并成功实现了跨域学习,将音乐和语音的知识应用于生物声学领域。此外,作者还提供了一个开源代码库和一个名为BEANS-Zero的新基准集,用于评估模型在不同生物声学任务上的表现。这一系列工作为生物声学领域的研究提供了新的思路和方法,也为其他领域的研究者们提供了宝贵的参考和资源。总之,NatureLM-audio是一个具有重要意义的研究成果,它的出现为生物声学领域的未来发展带来了无限可能。
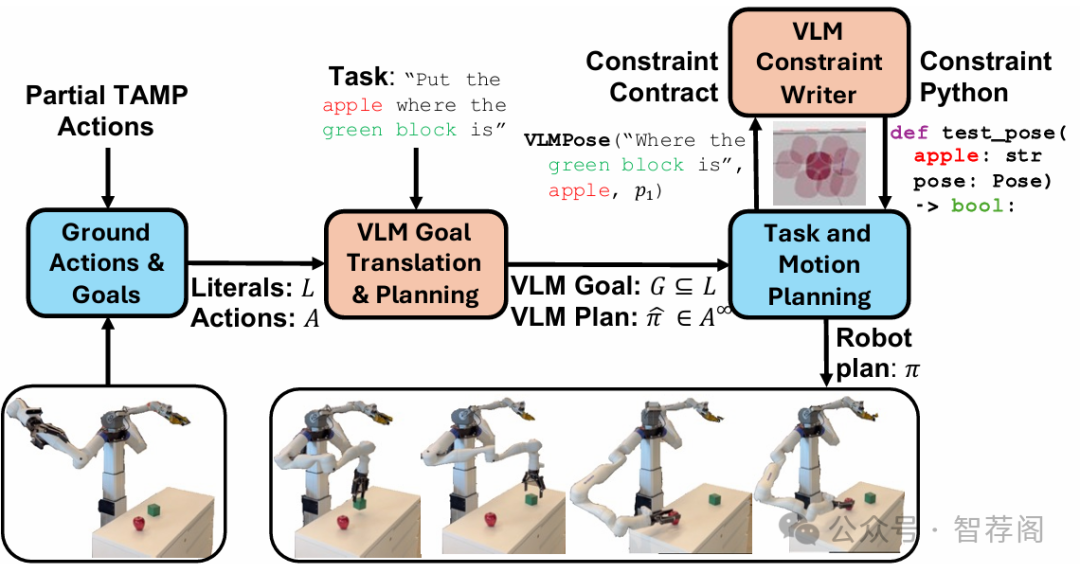
4.Open-World Task and Motion Planning via Vision-Language Model Inferred Constraints
Authors:Nishanth Kumar, Fabio Ramos, Dieter Fox, Caelan Reed Garrett
https://arxiv.org/abs/2411.08253
论文摘要
Foundation models trained on internet-scale data, such as Vision Language Models (VLMs), excel at performing tasks involving common sense, such as visual question answering. Despite their impressive capabilities, these models cannot currently be directly applied to challenging robot manipulation problems that require complex and precise continuous reasoning. Task and Motion Planning (TAMP) systems can control high-dimensional continuous systems over long horizons through combining traditional primitive robot operations. How ever, these systems require detailed model of how the robot can impact its envi ronment, preventing them from directly interpreting and addressing novel human objectives, for example, an arbitrary natural language goal. We propose deploy ing VLMs within TAMP systems by having them generate discrete and continu ous language-parameterized constraints that enable TAMP to reason about open world concepts. Specifically, we propose algorithms for VLM partial planning that constrain a TAMP system’s discrete temporal search and VLM continuous constraints interpretation to augment the traditional manipulation constraints that TAMP systems seek to satisfy. We demonstrate our approach on two robot em bodiments, including a real world robot, across several manipulation tasks, where the desired objectives are conveyed solely through language.
论文简评
这篇论文提出了一个名为OWL-TAMP的框架,旨在将视觉语言模型(VLM)集成到任务和运动规划(TAMP)系统中,以增强机器人抓取能力。它介绍了生成连续和离散约束的方法,这些约束允许TAMP系统解释开放世界概念,并执行涉及对象操作的任务。实验结果显示,与基准方法相比,提出的解决方案在各种抓取任务中的成功率更高。此外,这项工作具有重要性和前瞻性,随着人工智能技术的进步及其在机器人领域的应用,这一研究领域正变得越来越重要。
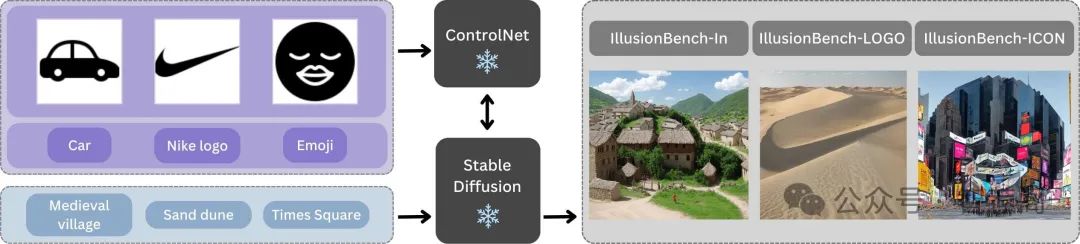
5.Hidden in Plain Sight: Evaluating Abstract Shape Recognition in Vision-Language Models
Authors:Arshia Hemmat, Adam Davies, Tom A. Lamb, Jianhao Yuan, Philip Torr, Ashkan Khakzar, Francesco Pinto
https://arxiv.org/abs/2411.06287
论文摘要
Despite the importance of shape perception in human vision, early neural im age classifiers relied less on shape information for object recognition than other (often spurious) features. While recent research suggests that current large Vision Language Models (VLMs) exhibit more reliance on shape, we find them to still be seriously limited in this regard. To quantify such limitations, we introduce IllusionBench, a dataset that challenges current cutting-edge VLMs to deci pher shape information when the shape is represented by an arrangement of visual elements in a scene. Our extensive evaluations reveal that, while these shapes are easily detectable by human annotators, current VLMs struggle to rec ognize them, indicating important avenues for future work in developing more robust visual perception systems. The full dataset and codebase are available at: https://arshiahemmat.github.io/illusionbench/
论文简评
该篇论文以IllusionBench为新数据集,旨在评估视觉语言模型(VLM)在形状识别能力方面的局限性。研究表明,尽管人类注释者可以轻松识别形状,但许多最先进的VLM却表现不佳,这一事实凸显了它们在视觉感知方面的重大局限性。论文通过零样本、少样本以及领域通用化等场景的深入评估,揭示了VLM更倾向于依赖场景元素而非形状识别的趋势。
论文的核心在于它直接面对当前VLM们在形状识别上的局限性,并通过一系列实验展示了其在不同任务中的性能差异。这些实验不仅强调了人类视觉认知的重要性,还进一步证明了形状在视觉识别中的核心地位。这一发现对未来VLM的研究具有重要意义,因为它提醒我们在构建和优化VLM时应更加关注形状感知能力的提升。总的来说,这篇论文是一个非常有价值的成果,为我们理解VLM如何处理复杂视觉信息提供了新的视角,并对未来的视觉计算机科学研究具有重要的指导意义。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









