






摘要:
得益于近期具有世界知识的大规模预训练模型的迅速发展,基于大模型的具身智能在各类任务中取得了良好的效果,展现出强大的泛化能力与在各领域内广阔的应用前景。
鉴于此,对基于大模型的具身智能的工作进行了综述,首先,介绍大模型在具身智能系统中起到的感知与理解作用;其次,对大模型在具身智能中参与的需求级、任务级、规划级和动作级的控制进行了较为全面的总结;然后,对不同具身智能系统架构进行介绍,并总结了目前具身智能模型的数据来源,包括模拟器、模仿学习以及视频学习;最后,对基于大语言模型(Large language model, LLM)的具身智能系统面临的挑战与发展方向进行讨论与总结。
具身智能的概念最早可以上溯至1950年图灵在其著名论文“Computing machinery and intelligence”[1]中对未来机器发展方向的设想:一个方向是让机器学会抽象技能,如下棋;另一个方向则是为机器人提供足够好的传感器,使之可以像人类一样学习。前者的思想出现在后来发展的各类神经网络如多层感知机、卷积神经网络中,即离身智能;后者则逐渐发展出了具身智能的概念。
现在,具身智能一般指拥有物理实体,且可以与物理环境进行信息、能量交换的智能系统[2]。虽然在过去的几十年间,离身智能取得了令人瞩目的成就,但对于解决真实世界的问题来说,“具身”的实现仍然是必要的,与强调从经验中学习并泛化的离身智能方法相比,具身智能更强调与环境的交互,只有拥有物理身体才能与世界进行互动,更好地解决现实问题[3]。
当前,随着机器人技术和计算机科学的发展,具身智能受到更多的关注,逐渐从概念走向实际应用,而如何利用目前飞速发展的计算能力与人工智能(AI)技术提高具身智能的表现则成为学界与产业界的关注重点。最近的研究表明,通过扩大语言模型的规模,可以显著提高其在少样本学习任务上的表现,以GPT-3[4]为代表的大语言模型(LLM)在没有进行任何参数更新或微调的情况下,仅通过文本交互来指定任务和少样本示例就能很好地完成各类任务。在此之后,具有优秀泛化能力与丰富常识的基础模型在计算机视觉、自然语言处理等领域都展现出令人瞩目的效果。GPT-4[5]、LLaMA[6]、LLaMA2[7]、Gemini[8]、Gemini1.5[9]等大语言模型能与人类进行流畅的对话,进行推理任务,甚至进行诗歌和故事的创作;BLIP [10]、BLIP2[11]、GPT4-V[12]等视觉−语言大模型则能对图片进行图像分割[13]、目标检测[14]、视觉问答(VQA)[15];DINO[16]、CLIP[17]、SAM[18]等视觉基础模型则以低于前两者的模型量级提供跨越图像与文本鸿沟的能力,为进行实时的开放词汇的视觉检索提供了可能。这一系列的进展不仅展示了基础模型的强大潜力,也为其与具身智能的融合提供了新的视角和可能性。文献[19] 将上述在大规模数据集上进行训练并能适应广泛任务的模型统称为基础模型,意即可作为大量下游任务训练基础的模型(目前一般认为基础模型即大模型,后文将不对二者作区分)。
由于涉及到物理环境,机器人深度学习模型往往面临数据获取难度大、训练的模型泛化性差的困境,传统机器人往往仅能处理单一任务,无法灵活面对复杂的真实环境。而基础模型用来自互联网的大量文本、图片数据进行预训练,往往包含各种主题与应用场景,能学习到丰富的表示与知识,具有解决各类任务的潜能,其作为具身智能的“大脑”能显著弥补机器人领域训练数据少且专门化的缺点,为系统提供强大的感知、理解、决策和行动的能力。此外,基础模型的零样本能力使得系统无需调整即能适应各种未见过的任务,基础模型训练数据的丰富模态也可以满足具身智能对各类传感器信息的处理需求。无论是视觉信息、听觉信息,还是其他类型的感知数据,基础模型都能够为具身智能提供全面和准确的理解。在实际应用中,这意味着具身智能能够更好地适应环境变化,理解各种操作对象,解决各种复杂问题。
大模型的强大理解能力也能为具身智能带来与人类无障碍沟通的能力,能更有效且准确地理解用户需求,而大模型的长对话能力也使其具有处理复杂任务的能力,并规划长期目标。这些特点都使得具身智能有别于传统的仅面向单一任务,或同质任务的传统机器人,使其具有更强的自主性与适应性。人形机器人的突出优势就是其通用性,而大模型带来的认知能力则是形成通用性的关键[20]。近期,各大机器人企业制造的人形机器人,如宇树机器人Unitree H1、特斯拉机器人Optimus,以及Figure AI的Figure 01均使用了基础模型进行赋能,展现出令人惊讶的理解、判断和行动能力。
随着大模型的发展,近年基于大模型的具身智能工作已经成为研究热点,各类试图将二者结合的工作层出不穷。尽管目前有一些以具身智能为主题的综述[21−23],但并未聚焦于大模型。目前也有综述研究大模型在机器人上的应用[24−28],但不同的是,本文的内容更倾向于从具身智能的角度介绍二者如何有机结合,并加入对模型规划层级的分类探讨。此外,由于该领域发展迅速,在上述论文发布后又涌现出了许多重要工作,本文将补充这些最新进展,为希望了解该领域的研究人员提供更多的参考 (工作总览见图1[25,29−100])。

图1 基于大模型的具身智能工作概览
本文内容安排如下:
第1节对大模型如何帮助具身智能实现对环境的感知与理解进行介绍;
第2节分析大模型分别在需求级、任务级、规划级、动作级这四个控制层级上为具身智能提供的规划;
第3节对各类实现大模型结合具身智能的系统架构进行分类与介绍;
第4节从模拟器、模仿学习和视频学习等方面介绍具身智能训练的数据来源,探讨大模型如何为机器人训练带来丰富的数据;
最后在第5节对全文进行总结并提出研究方向。

感知与理解
在与环境的交互中,具身智能通过摄像头、麦克风等传感器接受原始数据,并解析数据信息,形成对环境的认知。在处理此类信息时,大模型有着强大的优势,能有效处理整合多模态的输入数据,捕获各模态之间的关系,提取为统一的高维特征,形成对世界的理解。如对大量无标签的互联网文本和图像进行预训练的视觉模型,能将图像与文本编码到同样的向量空间中,这种对齐不仅有利于对环境的感知,也有利于对用户自然语言指令的理解,利于完成复杂的任务。本节主要讨论各类将大模型用于具身智能感知与理解的方法,讨论范围是文本、图像和音频等信息,其中感知的信息来源于环境与人类用户。
1.1 多模态模型理解
多模态模型,尤其是多模态大模型(Large multimodal model,LMM)具有理解图像、场景文本、图表、文档,以及多语言、多模态理解的强大能力[29],可以直接用于具身智能对环境的理解,并通过提示词使之输出结构化内容如控制代码、任务分解等指令。
Wang等[25]探索了使用GPT-4V赋能的具身智能任务规划的可能性,作者提出一个基于GPT-4V的框架,用于通过结合自然语言指令和机器人视觉感知来增强具身任务规划。框架使用视频数据的初始帧和对应的文本指令作为输入,根据输入的指令和环境图像,生成一系列动作计划。研究人员在多个公开的机器人数据集上进行实验,结果表明,GPT-4V能够有效地利用自然语言指令和视觉感知生成详细的动作计划,且这些计划与真实世界的演示视频具有高度的一致性,展现出GPT-4V在具身智能中的潜力。
ViLA[30]同样引入了GPT-4V,通过将视觉信息直接融入推理和规划过程中来生成一系列可执行步骤。此外,ViLA能够自然地整合视觉反馈,使得机器人能够在动态环境中进行鲁棒的闭环规划:机器人执行第一步行动,并观察结果,执行行动后,ViLA会将新的视觉观察作为反馈,与之前的视觉观察和已执行的行动步骤一起输入到GPT-4V中。GPT-4V将根据这些信息更新其对环境的理解,并调整后续的行动步骤。例如,如果第一次行动没有完全达到预期的效果,ViLA可能会生成一个新的行动步骤来纠正或完成未完成的任务。通过这种以多模态大模型提供实时反馈的设计,ViLA能够自然地利用视觉反馈来实现闭环规划,使得机器人灵活地适应环境变化,并有效地执行长期任务。
MultiPLY[100]构造了基于LLaVA[101]的多模态、以对象为中心的具身大语言模型。研究人员预先定义了一系列的动作标记(如选择对象、导航、观察、触摸、敲击、拿起、放下、环顾四周)和状态标记(如编码获得的对象点云、冲击声、触觉信息和温度信息)与环境互动,其中动作标记指导具身代理在环境中执行特定动作,而状态标记则将代理的多模态状态观察反馈给大语言模型,以便生成后续的文本或动作标记,使得MultiPLY能够灵活地在抽象表示和详细的多模态信息之间切换,以适应不同的交互任务。
1.2 多模态环境建模
一些工作利用多模态大模型对环境进行建模,实现具身智能对空间信息的多模态理解。以CLIP为代表的多模态大模型由于包含跨模态的理解能力,可以用于编码摄像头输入的图片与包含用户任务自然语言,实现对环境的语义建模,以增强具身智能系统对环境的感知。需要强调的是,虽然本节与第1.1节都提到了多模态大模型,但第1.1节内容倾向于直接利用模型进行2D图片与文本理解;本节的工作则是提取多模态模型的知识对场景本身进行建模,并未直接使用模型的输出进行控制。
为了解决开放词汇移动操作(Open-vocabulary mobile manipulation,OVMM) (即机器人能够在未知环境中识别并操纵任意物体以完成日常任务)的挑战,HomeRobot[102]提出了HomeRobot OVMM基准测试,提供了高质量的多房间家庭环境,以支持在仿真和物理环境中进行广泛的基准测试。为了解决开放词汇移动问题,文献[103]利用CLIP等大规模预训练模型的能力,以弱监督的方式学习场景的3D语义表示,构建了一个从空间位置到语义特征向量的映射函数,能够处理分割、实例识别、空间语义搜索和视图定位等多种任务。
文献[86]提出了C2F-ARM算法,实现了由粗到细的Q-attention机制,它在给定体素化场景的情况下,学习应该“放大”场景的哪一部分。通过迭代应用这种“放大”行为,实现了对平移空间的几乎无损的离散化,使得在连续机器人领域中可以使用离散的强化学习方法,取代了训练时往往样本效率低且不稳定的连续控制强化学习方法。然而由粗到细的方案无法提供全局感受野,在理解场景方面存在缺陷。
针对这个问题,PerAct[87]使用基于Transformer体素编码器得到体素特征,而自然语言则通过CLIP的语言编码器转化为语言特征,随后体素特征一起输入至Perceiver Transformer,最后输出序列经过解码器处理,恢复到原始体素网格的维度,并用于预测离散化的行动动作。通过对场景进行三维体素化,并使用编码器进行场景、语言的特征提取,PerAct能够有效地对环境进行建模,获取全局感受野,并在多任务设置中执行精确的6-DoF(Degree of freedom)操控任务。体素化提供了对场景的强结构先验,而Perceiver Transformer则允许模型从少量演示中学习并泛化到新的环境和任务。同样是使用体素对环境进行建模,AVLMaps[91]将视觉定位特征、预训练的视觉−语言特征和音频−语言特征与3D重建相结合,将多模态大模型的开放词汇查询能力融合进环境的3D体素网格中,使得机器人系统能够基于多模态查询(如文本描述、图像或地标的音频片段)在地图中索引目标。
Act3D[92]则提出了一种基于Transformer的3D特征场模型,使用大规模预训练的2D特征提取器(如CLIP[17]或ResNet50[104])来处理多视角的RGB-D图像,并将提取的2D特征通过特征金字塔网络(Feature pyramid network,FPN)[105]提取多尺度视觉词,语言指令则使用预训练的语言编码器来处理。AdaptiGraph[93]通过集成物理属性条件的动态模型和在线物理属性估计,可以使机器人能够适应性地操控具有未知物理属性的多样化物体。AdaptiGraph利用图神经网络(Graph neural network,GNN)预测粒子运动,并通过少量样本适应性地调整模型以适应新材料。实验表明,AdaptiGraph在预测准确性和任务熟练度方面优于非材料条件和非自适应模型。该方法在处理包括绳索、颗粒介质、刚性盒子和布料在内的多种真实世界可变形物体的预测和操控任务中表现出色。
神经辐射场(Neural radiance field,NeRF)[106]是一种用于3D场景表示和视图合成的深度学习方法,通过深度神经网络对场景的连续体积密度和颜色进行建模,能够从任意视角渲染出高质量的图像。在文献[107]中研究人员提出了蒸馏特征场(Distilled feature field,DFF)的概念,通过将2D特征映射到3D体积中,结合来自CLIP的知识,创建一个带语义特征的基于NeRF的场景表示,通过将自然语言指令与从NeRF中提取的语义特征相结合,机器人能够根据用户的文本描述来识别和操作场景中的特定对象,如图2所示。在6-DOF姿态推断中对夹爪周围也训练了一个NeRF场,在场中采样查询点并计算这些点的特征向量,使得能够推断出适合抓取特定对象的姿态。
图2 基于NeRF的语义特征场景表示[107]
近期同样用于3D场景表示的3D高斯(3D Gaussian splatting,3DGS)[108]在许多任务上展现出了惊人的能力与效率,其显式的场景表示能够以高效率和高精度渲染出具有丰富细节的场景,在虚拟现实、增强现实、同步定位与地图构建(Simultaneous localization and mapping,SLAM)等领域都表现出了巨大的潜力[109]。
LangSplat[88]是首个提出基于3D高斯构建3D语言场的方法,方法使用SAM与CLIP提取三个语义尺度的语言特征,并优化3D高斯对提取的特征进行表示,最终创建一个能够准确响应语言查询的3D语言场,同时保持高效的渲染和查询性能。实验结果显示,LangSplat显著优于之前最先进的基于NeRF的方法—语言嵌入式辐射场(Language embedded radiance field,LERF)[110],并在1 440 × 1 080像素分辨率下比LERF快199倍。
文献[111]利用3D高斯作为唯一的三维表示形式进行SLAM,实现了精确建图、高效跟踪、映射和高质量渲染,显著提高了实时SLAM系统能够捕捉的物体材料的多样性和真实感,并且在单目和RGB-D情况下都取得了最先进的性能。文献[112]则将语义带入了3D高斯SLAM领域,通过将语义特征嵌入3D高斯,实现了准确的3D语义映射与高精度的重建,并在多个数据集中进行测试,在映射、跟踪、语义分割和新视角合成方面展示出了优于现有的基于NeRF的SLAM方法的性能。
Splat-MOVER[89]成功地将3D高斯应用到具身智能的场景表示中。该方法通过可编辑的3D高斯场景表示实现多阶段、开放词汇的机器人操作。Splat-MOVER由三个主要模块组成:ASK-Splat、SEE-Splat和Grasp-Splat。ASK-Splat是一个3D场景表示模块,利用CLIP模型的视觉−语言特征和VRB (Vision robotics bridge)模型的抓取可操作性,为机器人任务提供了几何、语义和可操作性理解;SEE-Splat则采用实时场景编辑、3D语义遮罩和填充技术来可视化机器人交互导致的物体运动;Grasp-Splat是一个抓取生成模块,结合ASK-Splat和SEE-Splat来为开放世界中的物体提出候选抓取姿势。
1.3 可供性与约束
可供性(Affordance)指的是环境中物体相对于机器人所能提供的潜在交互方式[113];约束(Constraints)则指规划和执行机器人操作时需要遵守的一系列限制条件。使用基础模型对可供性与约束进行提取,可以使具身智能有效利用环境中的各种工具,并在使用工具解决问题的过程中考虑各类约束,以合适的方式完成任务。
预训练模型通过大规模文本预训练,具备了丰富的世界知识,能够回答与视觉场景相关的常识性问题。文献[114−116]最早探索了将基础模型用于对机器人任务进行规范的方法,随后AffordanceLLM[94]将大模型的世界知识与3D几何信息相结合,通过视觉语言模型(Vision language model,VLM)骨干扩展了一个掩码解码器和一个特殊特征,用于预测可操作性图。实验证明,该方法能够综合理解场景的多个方面,包括物体及其部分的检测、定位和识别、场景的地理空间布局、3D形状和物理特性,以及物体与人类潜在的交互功能,此外还能够处理全新的动作,显示出一定的泛化潜力。随后,Affordance Diffusion[95]提出一种基于扩散模型的图像生成方法,可以从单个物体的RGB图像出发合成人类手与该物体交互的合理图像,并从中直接提取出可行的3D手部姿态。作者构建了一个两阶段生成模型:首先使用LayoutNet生成与关节结构无关的手−物体交互布局,在LayoutNet预测出布局之后,ContentNet负责根据预测的布局和物体图像合成手−物体交互的图像。这一步骤考虑了手部外观的多样性,如形状、手指关节和肤色等。两个模块均建立在大规模预训练扩散模型的基础上,以利用其潜在表征能力。
在KITE[99]中,研究人员使用关键点来提取可供性。关键点定义为图像中的2D点,可以指导模型从2D图像中获取底层的动作。给定自然语言指令后,KITE使用一个锚定模块(grounding module)从指令中推断出场景中的2D关键点。锚定模块首先使用CLIP提取图像视觉特征,并将提取所得特征融合到全卷积网络中,最终输出表示关键点在图像中的位置概率的热图,并根据概率提取关键点。考虑对同一物体执行不同任务时对应的关键点相似但动作可能截然不同,KITE使用大语言模型从指令中提取任务类型(如抓取、放置、开启、关闭),并将锚定模块所得关键点与任务类型输入至动作生成模块中,得到完成整个任务所需的动作序列。实验表明,相比于依赖预训练视觉语言模型或仅采用端到端视觉运动控制而忽视技能模块的方法,KITE在演示数据较少或相当的情况下训练效果更优。
CoPa[96]通过部件空间约束实现通用机器人操作。该框架利用大规模预训练模型中蕴含的常识知识来指导机器人在开放世界场景中的低层次控制。在运动规划阶段,首先将识别出的关键部件简化为几何元素表示,如将细长部分建模为向量,而将其他部分建模为表面,然后在场景图像中标注这些几何元素,输入到视觉语言模型中,通过语言提示使视觉语言生成相应的空间几何约束。获取操作约束之后,CoPa计算出抓取后的一系列目标姿态,并将目标姿态规划形式化为一个受约束的优化问题,从而得出符合物理规律且能精准执行的连续动作序列。
Robo-ABC[98]则通过从人类视频中提取物体的交互经验,并存储为可供性的经验,当面对新物体时,机器人通过检索记忆中视觉或语义上相似的物体来获得可供性,并利用预训练的扩散模型将检索到的接触点映射到新物体上。这种方法允许机器人在零样本的情况下泛化操作不同类别的物体,而无需手动注释、额外训练、部件分割、预编码知识或视角限制。实验结果表明,Robo-ABC在视觉Affordance检索的准确性上比现有的端到端可供性模型提高了31.6%,并且在跨类别物体抓取任务中达到了85.7%的成功率。
1.4 人类反馈
在交互中及时根据反馈进行调整可以有效地帮助具身智能完成任务,其中人类的反馈尤为重要,因为人类是目标的提出者与整个交互行为的观察者。一些方法利用大模型提取人类反馈,使机器人不断根据反馈调整目标,有效地提高具身智能的灵活性并提高任务的完成度。OLAF[80]通过使用大语言模型来改进机器人的行为。系统包含三个步骤:用户交互、数据合成和策略更新。在用户交互阶段,用户观察机器人执行任务,并在认为机器人无法完成任务时停止,然后提供如何改进的自然语言指令;在数据合成阶段,使用大语言模型作为批评者,根据用户的口头纠正重新标记机器人执行的行动;在策略更新阶段,通过行为克隆在新合成的数据和之前收集的数据上更新策略。类似地,YAY Robot[81]探讨一种通过语言修正实时修正机器人行为的方法。当用户想要干预机器人行为时,可以通过口头指令,如“停止”让机器人暂停行动,然后提供口头纠正指导,并记录用户提供的所有口头纠正及对应的观察数据。这些数据随后用于进一步微调高级策略,系统每隔固定时间间隔查询高级策略生成语言指令。通过这个过程,YAY Robot不仅能在执行任务时根据用户的口头反馈即时调整行为,而且能不断吸取经验教训,通过反复微调逐渐改善自身表现。
尽管大模型具有丰富的常识知识,但由于训练数据来自互联网的图片与文本,理解3D物理世界的能力仍然不足。直接使用大模型进行机器人的动作规划往往无法精确地控制结果,难以进行细粒度的操作,如“抓住杯子”与“抓住杯柄”的难度截然不同。一些工作通过接受人类提示来加强模型对该区域的关注的方式解决这一问题。与KITE[99]类似,MOKA[85]同样利用关键点进行低层次动作的推理。不同的是,MOKA中的关键点由用户在图像中标出,作者将该方法称之为视觉提示。视觉提示有利于将动作生成问题转化为视觉语言模型能解决的视觉问答问题,解决了自然语言表达能力不精确的问题。MOKA框架包括两个层次的推理过程:高层任务推理和低层动作推理。在高层任务推理阶段,视觉语言模型将自然语言描述的任务分解为一系列简单的子任务,并总结每个子任务的信息,如抓取对象、未固定对象和运动方向等;在低层动作推理阶段,MOKA根据当前观察到的环境图像,提出关键点和路径候选,并通过视觉提问的方式让VLM从候选中选择正确的关键点和路径点,进而生成可执行的基于点的运动计划。ViLA[30]也探索了视觉提示的使用,作者发现在某些任务中,使用一幅表示期望结果的图片来指导机器人比仅依赖口头指令更有效。例如,要指示机器人整理桌面,提供一张按期望方式排列好的桌面照片可能更有效率。

控制层级
机器人的控制一般可以粗略地分为高层和低层。高层负责全局、长期的目标;低层负责具体操作与及时反馈。虽然基础模型具有丰富常识与较强的推理能力,但精确性、实时性较差,所以大模型往往不会直接参与机器人的低层次控制,而是通过需求理解、任务规划、动作生成等方式进行较高层级的控制。本文将目前基础模型参与的具身智能控制分为四个层级:需求级、任务级、规划级、动作级,这之下的层级则根据文献[117]分为基元级与伺服级。其中,规划级、动作级、基元级和伺服级也属于传统机器人控制规划的范畴,如图3所示。
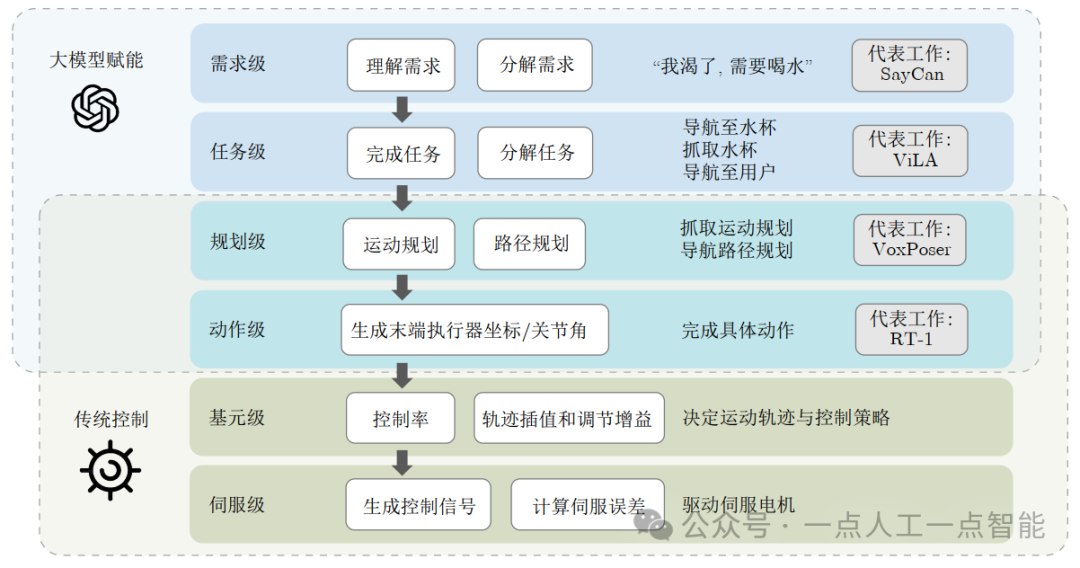
图3 具身智能系统的控制层级
大模型目前比较擅长的是理解需求和分解任务,同时越来越多的研究探索利用大模型在规划级和动作级赋能更具体的操作;而对于控制频率更高、更底层的基元级和伺服级,传统机器人学习更成熟和更适合高频控制的方法。由于许多工作涵盖了不止一种层级,本节将选择性地介绍在各层级所做出的代表性贡献的工作。
2.1 需求级
需求级负责理解用户需求,利用大模型的强大理解能力准确分析用户需求中隐含的任务要求,并分解为机器人可以完成的具体任务。
Text2Motion[72]构造了一个将自然语言指令转换为一套既符合需求也满足物理执行条件的框架,框架使用大语言模型进行高层次任务规划,从多种机器人技能组成的技能库中选择合适的技能,并使用几何可行性规划器优化技能序列参数,解决动作间的几何协调问题,从而提高任务成功率。
PaLM-E[73]是一个仅有解码器(decoder-only)的多模态语言模型,能够结合视觉、语言和机器人传感器数据,自回归地生成文本,这个生成的文本可以是回答问题的答案,或者是以文本形式产生的由机器人执行的决策序列,用于执行各种任务,如视觉问答、图像描述、机器人任务规划等任务。PaLM-E预设存在一组能够执行一系列低级技能的政策,这些技能定义了一个相对较小的词汇表,PaLM-E的规划由这些技能的序列组成。当PaLM-E用于任务规划时,会被集成到一个控制循环中,依据用户指令与训练的数据将目标分解为一些低级策略,执行完毕后依据新的观测结果重新进行规划。
SayCan[74]指出,尽管大模型具有一定的推理能力与理解能力,但因为模型没有直接接触现实世界,使用大语言模型生成的抉择可能超出机器人的能力范围。如用户提出的需求为扫地,模型经过推理提出可以使用吸尘器完成任务,但实际上机器人所处环境并没有吸尘器或是机器人还未掌握此技能,使得任务无法完成。SayCan提出了一种新的解决方法,可以结合大模型的高级语义知识和与物理环境相关的低级技能。方法提出了两个模块:Say和Can。前者使用大语言模型解析和生成与任务相关的自然语言描述,为每个可能的技能(或子任务)生成一个概率分布,表明它们对于完成整个指令的价值;后者利用价值函数来评估每个技能在当前状态下的可行性。最终结合Say模块的概率评分和Can模块的价值函数,SayCan选择最有可能成功执行且对完成任务最有帮助的技能。SayCan让机器人了解自己的能力范围,而KnowNo[79]使机器人能够判断何时它们缺乏必要的信息,并在需要时请求帮助。KnowNo建立了一个预测集,该预测集以用户指定的概率覆盖正确选项。如果预测集包含多个选项,机器人将请求人类帮助以明确下一步行动。
思维链(Chain of thought,CoT)是一种用于增强人工智能模型,特别是大语言模型在复杂任务中表现的技术,该方法通过模拟人类的思考过程,将复杂问题分解为一系列更小、更易于处理的步骤[118]。EmbodiedGPT[55]通过CoT生成更详细和可执行的计划,从而提高机器人执行任务的成功率。首先,模型识别任务的关键要素,例如目标、所需对象和预期的结果,将任务分解为一系列子目标。这些子目标是实现最终目标所需的中间步骤,随后规划模块为每个子目标生成详细的行动计划。类似地,LLM-Planner[78]使用大语言模型分解任务,并根据环境观察来提供每一步的指导。对于在自由环境中的智能体,同样需要明确需求。ELLM[76]和Voyager[77]使用大语言模型为游戏中的智能体提供探索目标和合适的任务,不断地掌握新技能和更难达成的目标。
2.2 任务级
任务级负责完成各项具体的任务,如抓取、导航、定位等。在一些工作如ViLA[30]中,这些任务由预定义的技能完成,而相应的技能由强化学习、行为克隆等方式学习得到。在其他工作中,子任务仍然由大模型完成。
OK-Robot[69]构造了一个开放知识机器人系统,它结合多种在公开数据上训练的基础模型,并用于在真实世界环境中拾取和放置物体。对于定位任务,初始化阶段使用iPhone手动扫描家庭环境,然后使用OWL-ViT[119]作为对象检测器,提取与每个物体相关的特征并构建一个以体素图为中心的语义记忆。导航时将语言查询转换为语义向量,并在体素图中找到与查询向量点积最大的体素,从而确定物体的位置。对于抓取任务,LangSam模型根据语言查询对物体进行分割,得到物体的掩码,然后从AnyGrasp生成的抓取姿态中筛选出与物体掩码匹配的抓取点,并实施抓取。
CaP(Code as polices)[70]利用大语言模型来生成机器人策略代码。这些代码能够将自然语言命令转换为机器人可执行的策略,从而实现对机器人的控制。CaP方法的关键优势在于它能够通过少量示例(Few-shot prompting)引导大语言模型生成新的策略代码。通过向大语言模型提供一系列格式化的自然语言命令和相应的策略代码示例,大语言模型能够学习如何将新的命令转换为应用程序编程接口(Application programming interface,API)调用的重新组合,从而生成新的策略代码。这种方法不仅能够处理空间几何推理,还能够泛化到新的指令,并且能够根据上下文为模糊的描述(如“更快”、“向左移动”)指定精确的值。此外,CaP方法还能够利用第三方库(如NumPy[120])执行算术运算和空间几何推理,从而增强大语言模型的能力。通过这种方式,CaP能够生成执行复杂任务的机器人策略,如视觉引导的拾放操作或基于轨迹的控制。LLM-GROP[71]同样通过提示技术从LLM中提取关于语义有效对象配置的常识知识,并将这些知识实例化到任务和运动规划器中,以适应不同的场景几何结构,从而提升服务机器人在多对象重新排列任务中的常识推理能力。
2.3 规划级
对于某个具体任务,规划级负责进行任务的规划,根据环境观察动态地决定具身系统未来的动作,完成轨迹生成、语言导航等任务。
VoxPoser[52]利用大语言模型和视觉语言模型提取环境可供性,并合成机器人轨迹,用于实现对大量日常操作任务的灵活、零样本执行。该方法中的大语言模型通过编写代码与视觉语言模型进行互动,生成三维价值地图并用于生成机器人轨迹(如图4所示)。其中,Affordance map与Avoidance map是两种关键的3D价值地图类型。Affordance map凸显出机器人最容易执行对应动作的区域,吸引力较大的区域说明这里是执行特定动作的最佳位置,例如抓住物品或转动旋钮;Avoidance map则用于指示机器人应尽量避免进入或接近的位置,高值区域提示机器人应当回避的障碍或其他不希望接触的对象。在运动规划阶段,VoxPoser首先依据Affordance map和Avoidance map进行贪心搜索,寻找一系列无碰撞的末端执行器位置,并结合其他类型的地图(如旋转、速度和夹爪状态等)进一步细化每个位置上的参数设定。
与SayCan[74]类似,3D-VLA(3D vision language action)[63]关注大模型对物理世界的知识不足的问题。3D-VLA是一个生成视觉模型,可以理解并处理3D空间信息,如场景的3D特征、点云、深度图,这些特征为模型提供了丰富的空间上下文,使得模型可以通过其3D理解能力来模拟未来事件,以更好地规划行动。在数据方面,作者创建了一个大型的具身指令数据集以微调模型,数据集中包含丰富的3D语言−动作对,覆盖了多种任务,如任务描述、动作预测、定位、多模态目标生成;在模型方面,3D-VLA在3D大模型的基础上引入了各类特征,如场景特征、物体特征和动作特征,使得模型可以更加关注需要交互的对象。在给定初始状态和目标状态的情况下,模型可以想象最终完成任务后的状态图与点云,并生成一系列动作特征以控制机器人完成任务。
iVideoGPT[64]提出了一个交互式视频生成模型,通过构建可扩展的世界模型支持基于模型的智能体进行探索、推理和规划。iVideoGPT采用可扩展的自回归Transformer框架,能够将多模态信号(包括视觉观察、动作和奖励)集成到一个由标记组成的序列中。通过可扩展的架构,作者在数百万人类和机器人操控轨迹上预训练了iVideoGPT,使得模型能够适应各种下游任务,如条件视频预测、视觉规划。针对具身智能的视觉和语言导航(Vision language navigation,VLN)问题,NaVid[65]通过预训练的视觉编码器和大语言模型来编码视觉观察和推理导航动作,模型仅依赖机器人的单目RGB相机捕获的视频流和人类指令来规划下一步行动,展示了VLM在无需地图、里程计或深度输入的情况下实现最先进的导航性能的能力。该方法模仿人类的导航方式,自然地解决了里程计噪声和从模拟到现实(Sim2Real)的领域差异问题。训练时,作者通过从连续环境中收集的510 k导航样本和763 k大规模网络数据训练NaVid,并在模拟环境和现实世界中进行了广泛的实验,证明了NaVid在跨数据集和模拟到现实的迁移方面实现了最先进的性能。
大模型同样可以为多机器人协作提供规划,保证多机器人间的沟通与协作。RoCo[66]提出了一种多机器人协作方法,该方法利用预训练的大语言模型进行高层次的通信和低层次的路径规划。在RoCo中,每个机器人都被分配一个LLM代理,能够以自然语言讨论任务策略,并生成子任务计划和任务空间航点路径。针对无人机的编舞问题,Swarm-GPT[67]利用自然语言指令,自动生成同步的无人机表演。系统通过使用音频分析工具提取的音乐特征,以及用户通过自然语言提供的任务规格,从而形成LLM的提示模板。然后,LLM根据这些信息生成一系列与选定歌曲节拍同步的时间位置航点,为每架无人机规划编舞。这些航点随后被一个轨迹规划器处理,以保证无碰撞和可行的运动。
2.4 动作级
在动作级中,大模型处理环境观察与提示,输出动作序列,动作序列可以是一系列关节角度或末端执行器的位姿与夹爪开合数据,这些序列将直接用于控制机器人的运动。Gato[60]是一个可以处理多模态、多任务和具身化问题的通用智能体,通过在604个涵盖不同的模态、观测和动作规范的任务上进行预训练,Gato可以完成玩游戏、为图像添加字幕、操控真实机械臂堆叠方块等多种任务。当Gato作为动作策略时,通过自回归方式逐个标记采样动作向量,并将采样的标记解码成具体的动作输出到环境中以控制游戏角色或机械臂。类似地,RoboFlamingo[61]通过解耦视觉−语言理解和决策制定,使用模仿学习在语言条件操控数据集上进行微调,有效地将预训练的VLM用于理解视觉观察和语言指令,输出一系列包括末端执行器姿态、夹爪状态在内的动作序列以指导机器人完成任务。
Prompt2Walk[59]探索了如何使用大语言模型GPT-4,通过设计良好的文本提示来输出机器人的关节目标位置,从而实现机器人的行走。核心思想是利用少量的物理环境中收集的提示,使得大语言模型能够在没有针对特定任务进行微调的情况下,自回归地生成机器人的低级控制命令。这种方法有效地解决了将大语言模型与物理世界结合的挑战,并能够生成动态的机器人运动。
ManipLLM[62]通过微调多模态大语言模型(Multimodal LLM,MLLM),使其在保留固有常识和推理能力的同时,具备了输出机器人执行器位姿的能力。首先模型使用CLIP的视觉编码器来提取输入RGB图像的视觉特征,而输入文本则通过预训练的LLaMA[6]模型的分词器将编码转换为文本特征,随后二者通过多模态投影模块进行对齐,之后输入至LLaMA模型,进行多模态理解并预测机器人操控的对象姿态。在训练时,通过LLaMA-Adapter[121]对LLaMA进行微调。LLaMA-Adapter是一种可以高效微调LLaMA的方法,不仅能使得LLaMA获得新的知识,也能保证LLaMA的预训练知识不被破坏。最终,模型能够识别图像中对象的类别,了解对象的哪些区域可以被操控,并预测末端执行器的精确姿态。

系统架构
目前的具身智能架构一般可以粗略地分为两种,第一种是端到端的Transformer[122]架构(图5(a)),第二种是冻结参数的大模型结合基础模型(图5(b))。前者端到端的架构可以直接从输入数据到目标结果,不需要进行提示词工程,较为简洁高效,往往在规划级、动作级中使用;后者使用的大模型通常是在广泛的数据上预训练好的,在利用大模型的强大能力的同时保留了对特定任务进行微调的灵活性,在需求级、任务级中使用较多。使用预训练模型可以显著减少训练时间和所需的数据量,普遍适用于数据较为稀缺的任务。
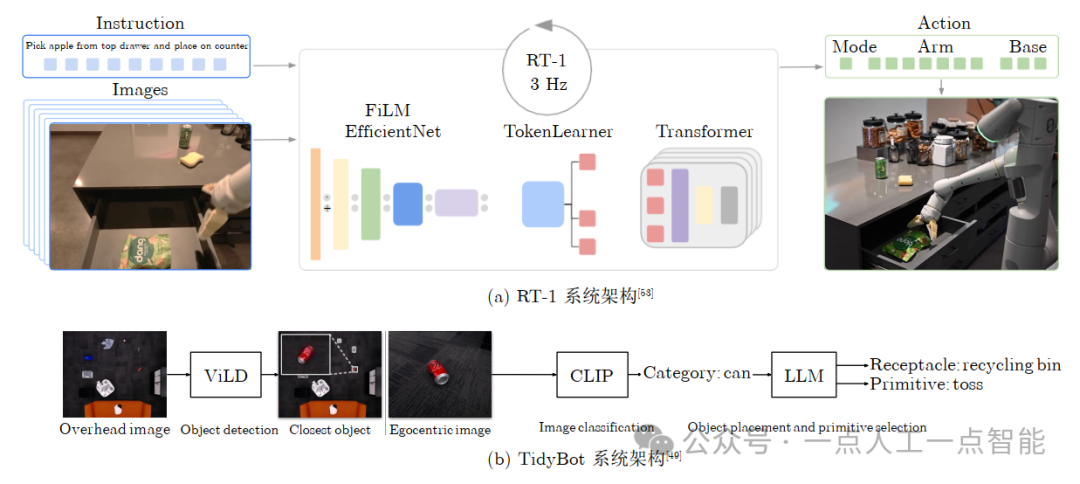
图5 具身智能的不同架构举例
3.1 基于Transformer的架构
Transformer[122]自从2017年被提出以来,其高效的架构以及广泛的应用领域已经成为自然语言处理中一个新的重要里程碑。它通过注意力机制(Attention mechanism)捕捉数据之间的关联性,从而显著提高了模型处理序列数据的能力。Transformer架构的一个关键特点是其能够并行处理序列中的所有元素,这种并行处理能力使得Transformer模型在处理大规模数据集时更加高效,从而极大地加速了模型的训练过程。在端到端的应用中,Transformer不仅可用于文本处理任务,还扩展到图像识别、语音识别等其他领域,展现出极高的通用性和灵活性。
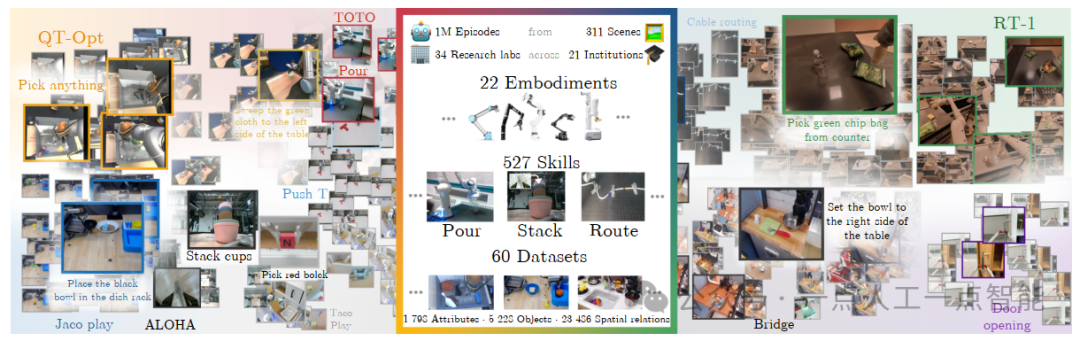
图6 RT-X收集到的多样化数据[55]
Robotics transformer (RT-1)[53]设计了一个端到端架构,能够吸收多样化的机器人数据,并在真实世界的机器人应用中执行真实任务。模型同时接受文本与6幅300 × 300像素的图片。文本特征需要经过USE (Universal sentence encoder)[123]处理后与图像对齐,与初始图片一起经由EfficientNet[124]层提取出特征,之后通过FiLM[125]对提取的特征进行调节,使得模型能够根据给定的文本指令动态调整其对图像的理解,随后特征经过tokenlearner模块生成特征,最后送入Transformer并输出离散动作指令:末端执行器的三维坐标、欧拉角、夹爪的开合、底座的运动以及状态指示。实验显示了RT-1出色的可扩展性、泛化能力、鲁棒性和学习能力,且得益于高效的模型架构,RT-1能够在3 Hz的频率下实时运行。
随后,谷歌的DeepMind团队又提出了RT-2[54],研究了如何将基于互联网规模数据训练的视觉−语言模型直接整合到端到端的机器人控制中,以提高泛化能力并实现语义推理。RT-2模型的基础是大型的视觉−语言模型,如PaLI-X[126]和PaLM-E[73],这些模型已经在互联网规模的数据集上进行了预训练,能够直接处理图像和文本输入,并生成自然语言文本的序列作为输出。为了使自然语言响应和机器人动作适应同一格式,这些模型将动作表示为文本特征,并像自然语言词元一样直接将其纳入模型的训练集,最终将视觉语言模型训练为视觉−语言−动作模型(VLA)。与RT-1和其他基线方法相比,RT-2模型在执行任务和泛化到新对象、背景和环境方面的表现均更为优秀,也涌现出了解释命令中未出现在机器人训练数据中的语义关系,以及在用户命令的响应中进行基本推理等新兴能力。此外作者也强调了数据集多样性与规模对机器人适应性与泛化性的重要性,提出如何让机器人通过新的数据收集范式(如人类视频)来获取新技能是一个值得探索的问题。谷歌团队在后续的RT-X[55]中进一步增加了数据的规模与多样性,如图6所示。

图4 VoxPoser根据价值图规划运动轨迹[52]
InteractiveAgent[56]提出了一个名为“交互式代理基础模型”的人工智能系统,通过多任务代理训练范式训练能够在多个领域、数据集和任务中表现良好的AI代理,通过统一的预训练框架处理文本、视觉数据和动作作为输入。作者将每种输入类型视为独立的特征,并预训练模型以预测文本、视觉、动作这三种模态的特征,这三种模态的结合使得模型能够在多模态环境中进行有效的交互和任务执行。例如,在机器人技术中根据文本指令执行物理操作;在游戏AI中根据视觉场景和文本指令预测玩家的动作;在医疗保健中通过视频理解临床情况并生成相关文本描述。作者的实验证明了其在各个领域中生成有意义和上下文相关输出的能力,展示了在多模态系统中开发通用、行动导向的系统的可能性。
在ALOHA[37]中,作者提出一种新颖的算法:基于Transformer的动作块(Action chunking with transformers,ACT),用于低成本硬件上的精细双手动态操作任务。ACT 的核心思想是通过模仿学习来实现对复杂动作序列的生成模型,以此来提高在高精度任务中的性能。ACT 的模型结构基于条件变分自编码器(Conditional variational autoencoder,CVAE)[127],包括一个编码器和一个解码器。CVAE 编码器采用类似 BERT[128] 的 Transformer 编码器,而 CVAE 解码器则结合了 ResNet 图像编码器、Transformer 编码器和 Transformer 解码器。输入的图像通过 ResNet18 进行处理,将高分辨率的 RGB 图像转换为特征映射,然后通过 Transformer 编码器和解码器生成动作序列。在ACT的训练过程中,编码器首先将动作序列和关节观察压缩成一个特征,而解码器则利用这个特征和当前的观察来预测一系列动作。在测试时,编码器被丢弃,仅使用解码器作为策略。ACT 在多个模拟和真实世界的精细操作任务上表现出色,例如打开半透明调料杯和放置电池,成功率高达 80% ~ 90%,并且仅需要 10 min的演示数据。这表明ACT能够有效地从人类演示中学习,并在低成本硬件上执行复杂的操作任务。随后,作者又增加了重力补偿等便于操作的改进,提出ALOHA2[58];增加移动底盘,提出Mobile ALOHA[129],得以实现许多需要移动才能完成的复杂操作,如炒菜、打扫房间等。
3.2 参数冻结的大模型结合基础模型
随着深度学习技术的不断进步,预训练大模型逐渐成为一种重要的技术趋势。在具身智能领域,通过结合冻结参数的大模型和基础模型,在不牺牲模型泛化能力的前提下,针对特定任务进行灵活的优化和调整,不仅可以利用大模型在海量数据上学习到丰富的知识,还可以通过基础模型的调整来适应特定的任务需求。
TidyBot[49]探讨了如何使机器人在执行家庭清理任务时能根据用户的个人偏好进行有效且个性化的辅助。TidyBot的工作流程包含几个关键步骤:首先,通过与机器人的初步交互收集用户偏好;接着,将这些偏好输入到大语言模型中进行总结,生成概括性的放置规则;随后,利用CLIP模型进行图像分类,识别出环境中物体的类别,基于大语言模型总结的规则,系统选择合适的容器(receptacle)及操作方式(如放置或投掷);最后,机器人执行相应操作,将物体归位。
VIMA[50]提出了一种可接受多模态输入的创新性的框架,旨在通过多模态提示实现通用机器人操作,从而将自然语言处理领域的提示式学习成功范式拓展至机器人技术。在模型方面,VIMA提出一个基于Transformer架构的模型,能够自回归地输出动作序列以响应输入的多模态提示,利用跨注意力机制条件优于多模态提示,并针对机器人操作任务定制了一系列组件。特别是在动作解码阶段,VIMA通过一组动作头将预测的动作特征映射至动作空间,这些动作头分别负责解码SE(2)姿态的离散坐标和旋转表示,最终通过仿射变换整合为连续动作输出。此外,VIMA还开发了一个全新的仿真基准,包含数千个程序生成的任务实例,每个任务均附有多模态提示,以及超过60万条专家轨迹用于模仿学习,同时设立4层评估协议,以系统地检验模型的泛化能力。
Instruct2Act[51]提出了一种框架,通过大语言模型将多模态指令转换为机器人操作任务的序列化动作。该框架的核心在于利用预训练的大语言模型生成Python程序,这些程序构成了一个全面的感知、规划和动作循环。在感知部分,Instruct2Act使用预定义的API调用多个基础模型,其中SAM用于精确定位候选对象,而CLIP模型用于对象分类。Instruct2Act的一个关键特点是其在处理不同指令模态和输入类型方面的灵活性和可调性,能够适应特定的任务需求。例如,它能够处理纯语言输入和语言−视觉输入,通过统一的检索系统使用不同类型的查询来确保使用统一架构处理这两种输入。对于纯语言输入,描述性句子用于指定目标对象和动作;而对于多模态输入,指令使用图像来描述目标对象或目标状态。在VIMABench的6个代表性元任务上的实验展现了Instruct2Act强大的竞争性能。

数据来源
为了让具身智能系统展示出强大的适应性与泛化性,为具身智能模型训练获取高质量、多样化的数据是至关重要的一步。本节将探讨在各种场景中获取数据的不同方法,包括在模拟器中获取数据、从人类演示中提取数据以及利用视频与游戏作为数据来源,并对具身智能系统从这些数据中学习的能力进行深入讨论。
4.1 模拟器
模拟器也称仿真器,为具身智能提供了一个可控且安全的测试环境,且模拟器能支持多个实例同时运行,大大加快了数据收集的速度。通过模拟器,研究者能够在虚拟环境中快速迭代和测试不同的算法和模型配置,而无需担心实际物理世界中可能遇到的延时、成本(人力和时间)和安全问题[47,130−136]。
BEHAVIOR-1K[48]提出了人类中心化的具身智能基准测试,该基准测试由两个主要部分组成:第1部分是定义了1 000个日常活动的数据集,这些活动覆盖了50个不同的场景(如房屋、花园、餐厅、办公室等),并涉及超过9 000个带有丰富物理和语义属性的物体;第2部分是OMNIGIBSON,这是一个新颖的仿真环境,它通过逼真的物理仿真和渲染来支持这些活动,包括刚体、可变形体和液体,为训练和测试具身智能代理提供了理想的平台。通过在这些复杂且逼真的活动中训练,具身智能系统能够在模拟环境中学习和改进,最终将这些技能转移到现实世界中,以执行有用的任务和解决实际问题。
由于在现实世界中收集大量交互数据成本高昂,研究者们通常依赖模拟数据来训练通用的机器人策略,使用大语言模型自动生成丰富的模拟环境和专家演示可以增强机器人策略的任务级泛化能力[137]。如RoboGen[42]提出了通过使用生成模型自动大规模学习多样化的机器人技能的方法,以提取嵌入大规模模型中的广泛且多变的知识,并将其转移到机器人领域,用以应对机器人研究中长期存在的挑战,即如何让机器人掌握多样的技能,并在各类环境中执行任务。RoboGen为机器人设计了一套自我引导的“提议−生成−学习”循环:首先,机器人基于大语言模型提议潜在的有趣任务与技能;接着,生成包含适当空间配置的物体及资产的模拟环境;然后,将高级任务分解成子任务,选择最优学习方式(强化学习、运动规划或轨迹优化),生成训练监督;最终,学习获取新技能的策略。
类似地,Scaling up and distilling down[44]提出了一个在模拟器中进行学习的框架,使用大语言模型指导高层规划,并利用基于采样的机器人规划器(如运动或抓取采样器)生成多样化和丰富的操作轨迹。为增强数据收集过程的鲁棒性,大语言模型需要推断出每个任务的成功条件的代码片段,不仅提高了数据收集策略的成功率,也使数据收集过程能够检测失败并重试,同时自动将轨迹标记为成功/失败。随后,研究者将这些机器人经验蒸馏成一个从视觉观察和自然语言任务描述中推断控制序列的视觉−语言−运动策略。为了有效地学习多样化的机器人轨迹,他们扩展了扩散策略,以处理基于语言的多任务条件,允许学习到的策略通过基于语言的规划器被重用和重组。此外,文献[44]还提出了一个新的多任务基准,包含18个任务,以测试长期行为、常识推理、工具使用和直观物理理解。在基准上的实验结果表明,蒸馏策略成功地学习了数据收集过程中的鲁棒重试行为,并在上述领域的绝对成功率上平均提高了33.2%。
Omnigrasp[46]提出了一种控制模拟仿真人形机器人的方法,该机器人能够抓取物体并沿复杂轨迹移动物体。方法的训练经历两个阶段,首先在仿真环境中通过蒸馏过程训练一个通用的、灵巧的仿生人运动表示模型,随后使用这个预训练的运动表示进行强化学习策略的训练,完成控制仿生人抓取各种物体并沿预定轨迹移动的功能。其中仿真环境采用高性能的基于GPU (Graphics processing unit)的物理模拟平台Isaac Gym[136],利于快速迭代和优化强化学习策略。该方法的核心在于利用一种预训练的通用灵巧运动表示(Universal dexterous motion representation),这为强化学习提供了一个结构化的行动空间,显著提高了训练效率。Omnigrasp方法不需要依赖特定任务的运动先验或成对的全身动作与物体轨迹数据集,仅通过物体网格和期望的轨迹,在测试时就能实现对新物体的抓取和轨迹跟随。
尽管模拟器在安全、成本和效率方面均有优势,但模拟环境无法完美复现现实世界的复杂性和不确定性,这就带来了如何确保机器人在现实世界中表现与模拟中一致的挑战,即Sim2Real问题。传统的Sim2Real方法依赖于手动设计和调整任务奖励函数以及模拟物理参数,这一过程缓慢且耗费人力。与之相对,DrEureka[45]算法通过对目标任务的物理模拟,能自动构建合适的奖励函数和领域随机化分布(Domain randomization),这个过程分为三个阶段:首先,LLM合成奖励函数;其次,基于扰动模拟中的初始策略执行,创建物理参数的适当采样范围;最后,LLM利用这些信息生成有效的领域随机化配置。实验表明,该方法对多种机器人和任务具有普遍适用性。
4.2 模仿学习
人类对机器人进行远程操控并完成任务的过程能够提供对复杂任务处理的深刻见解。专家执行任务的方式中包含了关键的决策点和操作技巧,这些信息可以用于通过模仿学习来训练具身智能模型以完成复杂任务。
ALOHA[37]通过人类操作员使用一对机器手臂来演示任务,在操作员操控时记录下机械臂的关节位置,与来自4个摄像头(顶部、前置、左手腕和右手腕)的图像流共同构成观测值,并将这些观测值用于训练端到端模型,使得机械臂能仅凭RGB图像输入独立完成复杂任务。尽管ALOHA提供了廉价的模仿学习方案,但受限于机械臂系统,操作只能在实验室环境内完成。
HumanPlus[39]则探索了人型机器人的数据收集与训练。系统通过单目RGB摄像头实现实时人体和手部运动的估计,并将其重新定位到仿人机器人的运动中,从而实现“影子跟随(shadowing)”。通过这种方式,人类操作员可以远程操作机器人收集全身数据,用于学习真实世界中不同任务的技能。此外,系统还利用收集到的数据进行监督行为克隆,训练基于视觉的技能策略,使机器人能够通过模仿人类技能自主完成任务。
为实现在实验室外同样可行的数据收集,Chi等[38]提出了直接从人类演示中转移技能到可部署的机器人策略的框架,通过手持夹爪和精心设计的接口,以便携、低成本且信息丰富的方式收集复杂的双手和动态操作演示数据,且学习到的策略与硬件无关,可以跨多个机器人平台部署。在硬件方面,UMI (Universal manipulation interface)使用155°鱼眼镜头增加视野和视觉上下文,以及在夹爪上增加侧镜以提供隐式立体观察;在软件方面,UMI采用推理时延匹配和相对末端执行器轨迹作为动作表示,以处理不同的传感器观察和执行时延,并应用了Diffusion policy[138]来模拟多模态动作分布。实验表明,仅通过改变UMI每个任务的训练数据,就能够实现动态、双手、精确和长期行为的零样本泛化。
4.3 视频学习
互联网的视频包含了巨量的信息,而其中包含的大量人类与环境交互的视频更是能提供大规模的、多样的和真实的行为数据,用于训练具有广泛性和通用性行为能力的模型。但此类视频一般不包含标签,如何有效地提取视频中的动作并用于训练是该方向的重点问题。
文献[32]提出了一种名为VRB的方法,通过利用互联网上的人类行为视频来训练一个视觉可供性(Visual affordance)模型,该模型能够估计人类在场景中的可能交互位置和方式,通过从人类的视频中学习,使得机器人能够更好地理解和预测人类的交互行为。
视频预训练(Video pre-training,VPT)[33]提出了一种预训练方法,通过观察未标记的在线视频来训练能够在序列决策领域(如机器人技术)中行动的智能代理。在机器人领域中,公开可用的数据通常缺乏用于训练行为先验的标签,为了解决这一问题,研究者通过半监督模仿学习的方法,展示了如何利用少量标记数据训练一个逆动力学模型(Inverse dynamics model,IDM),该模型能够准确预测视频中每个时间步的动作。类似地,RoboCLIP[34]提出了一种在线模仿学习方法,该方法能够使用单个视频演示或文本描述来生成奖励函数,从而训练强化学习代理执行机器人操作任务。RoboCLIP的核心思想是利用预训练的视频和语言模型来编码代理行为的视频和任务描述,然后通过计算它们在潜在空间中的相似度得分来生成奖励。这种方法避免了手动设计复杂的奖励函数,并且不需要大量的领域内专家演示。RoboCLIP的优势在于它只需要一个示范,无论是视频还是文本,就能有效地训练代理。此外,它还能利用跨领域的演示,例如使用人类解决任务的视频来生成奖励,这使得RoboCLIP不局限于特定的演示和部署领域。
Wake等[12]提出了一种多模态任务规划器,通过分析人类执行任务的视频,创建可执行的机器人程序,并结合对环境可供性的理解。计算过程从使用GPT-4V分析视频开始,将环境和动作细节转换为文本,随后由GPT-4驱动的任务规划器进行处理。在随后的分析中,视觉系统会根据任务计划重新分析视频,使用开放词汇表的对象检测器来确定对象名称,并关注手−对象关系以检测抓取和释放的时刻。这种时空定位允许视觉系统进一步收集对机器人执行任务有价值的可供性数据(如抓取类型、路径点和身体姿势)。
针对动物数据,Han等[36]提出了一个分层框架,旨在通过预训练模型和强化学习,使四足机器人展现出类似动物的敏捷性和游戏行为。该框架包含3个层次:原始层(Primitive-level)、环境层(Environmental-level)和策略层(Strategic-level)。原始层通过深度生成模型从动物运动数据中学习,生成控制信号,使机器人能够模仿真实动物的行为;环境层则利用原始层的知识,通过感知环境信息来适应不同的地形和障碍;策略层专注于解决复杂的下游任务,如多智能体追逐游戏,通过复用前两层的知识来训练。研究者将训练好的分层控制器应用于MAX机器人,成功地在现实世界中模拟动物行为并穿越复杂障碍,在设计好的多智能体追逐游戏中展示出类似动物的策略和敏捷性。

结束语
具身智能作为未来智能系统的关键发展方向,通过与物理环境的紧密互动,正逐步展现出超越传统离身智能的潜力。本综述聚焦于揭示基础模型如何推动具身智能的演进。在感知与理解方面,端到端模型实现了对复杂环境的深入理解与动态适应;在规划层面,从需求级到动作级,大模型通过生成任务计划和序列化动作,展示了具身智能在复杂任务执行中的自主性和灵活性,实现感知、规划和动作的闭环,彰显了具身智能的高级认知与执行能力;在数据获取方面,模拟器、人类演示和互联网视频成为具身智能训练的重要资源,通过模拟环境和自动生成技术,加速了技能学习和测试,为具身智能提供了丰富的训练场景和数据,促进了技能的多样化和泛化。
在具身智能取得极大进展的同时,许多挑战也亟待解决,这些挑战不仅制约了技术的广泛应用,还对进一步的研究方向提出了深刻的要求。这些挑战包括:
1)真实数据稀缺。真实世界数据的获取是具身智能系统训练和验证的关键。与虚拟环境相比,实体环境的数据收集面临着成本高、标注难、多样性不足等问题。此外,环境的多变性和不确定性要求模型能够泛化至未见情景,这进一步加剧了对大规模多样化数据的需求,尤其是对非实验室环境的数据收集,这类数据更加真实、复杂,对于训练能够适应多种环境的机器人尤为关键。如UMI[38]设计的数据采集框架便极大方便了非实验室环境下的采集,而Open X-Embodiement[55]综合全球实验室数据构造的包含各类机器人、各类任务的数据集也为具身智能的训练提供了极大便利。未来如何提高真实数据收集的便利性、如何增大数据集的规模、如何像在模拟器中一样自动化地获取数据将是非常具有前景的研究方向。
2)推理速度。大模型的庞大参数量带来了强大的零样本推理能力,但也带来了推理速度较慢的问题,目前使用大模型进行控制的工作往往无法做到实时响应,对实际应用产生了极大限制。一些工作如ALOHA[37]、RT-1[53]使用轻量级的模型解决此类问题,但获得实时性的同时也损失了泛化性。未来一个可能的研究方向是使用大模型高层规划 + 小模型底层控制的方式规避推理速度的问题,或是对模型本身进行剪枝、量化等优化操作[139]。
3)具身多智能体协同。面对现实世界中诸如灾难救援、智慧城市管理、群体机器人协作等高度复杂的任务,单一具身智能体往往难以有效应对,如何设计有效的通信与协调框架,使各具身智能机器人之间高效沟通并综合各局部信息进行整合决策将是一个具有极大前景的研究方向。近期,AutoRT[140]构造了一个自动化数据采集框架作为机器人协调器,可以自动地指定一个或多个机器人在环境中执行适当的任务并收集真实数据,AutoRT在多个建筑物中对20多个机器人提出指令,并收集了77 k个真实机器人场景,这些场景均通过远程操作和自主机器人策略获得。解决具身多智能体的协同问题不仅能在上述复杂的应用领域取得成效,也能为机器人数据的高效收集提供新的思路。
大模型的引入极大增强了具身智能的感知精度、理解深度、规划智能及数据利用效率,使其在家庭服务、医疗、教育、工业等领域的应用前景广阔。然而,挑战依然存在,包括真实数据稀缺、实时推理、多智能体协同等挑战仍需持续探索与优化。在可预见的未来,融合基础模型的具身智能系统将更深入地融入人类生活。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 5092
5092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









