








🎩 欢迎来到技术探索的奇幻世界👨💻
📜 个人主页:@一伦明悦-CSDN博客
✍🏻 作者简介: C++软件开发、Python机器学习爱好者
🗣️ 互动与支持:💬评论 👍🏻点赞 📂收藏 👀关注+
如果文章有所帮助,欢迎留下您宝贵的评论,点赞加收藏支持我,点击关注,一起进步!
目录
前言
机器学习聚类分析是一种通过机器学习技术将数据点划分为不同的组或簇的方法。这种方法可以帮助识别数据中的模式、群体或异常情况,从而更好地理解数据的结构和特征。常见的机器学习聚类算法包括K-means、层次聚类、DBSCAN等,它们在不同场景下具有不同的优势和适用性。在进行机器学习聚类分析时,需要考虑数据的特点、选择合适的算法和参数,并对结果进行解释和验证。
正文
01-聚类分析简介
在机器学习中,常见的聚类算法包括:
K-Means 聚类:将数据点分成预先指定的 k 个簇,每个簇具有最小化簇内平方误差的中心点。K-Means 是一种迭代算法,通过不断更新簇中心点来优化聚类结果。
层次聚类:逐步将数据点合并到不断增长的聚类中,形成层次结构。层次聚类可分为凝聚式和分裂式两种方法,分别是自底向上和自顶向下的聚类过程。
谱聚类:基于图论中的谱分析方法,通过构建数据的相似度矩阵,并对其进行特征分解来进行聚类。谱聚类通常适用于数据集中存在非凸形状的聚类结构或者复杂的聚类结构。
均值移位聚类:基于核密度估计的非参数聚类方法,通过寻找数据空间中密度最大化的区域来发现聚类中心。
DBSCAN:基于密度的聚类算法,将高密度区域视为聚类,并通过将低密度区域视为噪声点来实现聚类。
亲密传播聚类:基于图论的聚类方法,通过在数据点之间传播消息来发现聚类中心,并将数据点分配到这些中心。
这些算法各有特点,适用于不同类型的数据和聚类问题。在选择聚类算法时,需要考虑数据的特征、聚类结构的性质以及算法的计算复杂度等因素。下面从一些实例中分析应用过程:
02-基于k-均值聚类的矢量量化实例
基于k-均值聚类的矢量量化是一种常见的聚类算法,它将数据点分成K个簇,并将每个数据点分配到与其最接近的簇中。这种方法通常用于将数据点压缩到较低维度的表示,或者用于图像压缩和图像分析等任务。其原理如下:
初始化: 随机选择K个数据点作为初始的簇中心。
分配: 将每个数据点分配到距离其最近的簇中心所在的簇。
更新: 对每个簇,计算其所有成员的平均值,将这些平均值作为新的簇中心。
重复: 重复步骤2和3,直到簇中心不再发生变化,或者达到最大迭代次数。 k-均值聚类的目标是最小化簇内的平方误差和(SSE),即簇内数据点与其簇中心的距离之和。这种方法的优点是简单易懂,并且对于大型数据集也比较高效。然而,它也有一些缺点,比如对初始簇中心的选择敏感,以及对簇个数K的选择需要一定的先验知识或试验。
下面给出具体代码分析基于k-均值聚类的矢量量化实例,代码如下:这段代码演示了如何使用k-均值聚类算法对图像进行压缩。解释如下:
导入库和模块: 这部分代码导入了所需的库和模块,包括NumPy、SciPy、Matplotlib以及scikit-learn中的cluster模块。
生成数据: 代码中使用了SciPy中的示例图像,将其转换为灰度图像,并将其展平为一维数组(n_samples, n_features)。
应用k-均值聚类: 使用scikit-learn中的KMeans类对数据进行聚类,将图像像素分成了n_clusters个簇。
重构压缩后的图像: 将每个像素分配到所属的簇中心,并根据每个簇的中心值重构图像,从而实现图像的压缩。
显示原始图像和压缩后的图像: 将原始图像和压缩后的图像以及直方图显示出来,以便对比和分析。
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
from sklearn import cluster
try: # SciPy >= 0.16 have face in misc
from scipy.misc import face
face = face(gray=True)
except ImportError:
face = sp.face(gray=True)
n_clusters = 5
np.random.seed(0)
X = face.reshape((-1, 1)) # We need an (n_sample, n_feature) array
k_means = cluster.KMeans(n_clusters=n_clusters, n_init=4)
k_means.fit(X)
values = k_means.cluster_centers_.squeeze()
labels = k_means.labels_
# create an array from labels and values
face_compressed = np.choose(labels, values)
face_compressed.shape = face.shape
vmin = face.min()
vmax = face.max()
# original face
plt.figure(1, figsize=(3, 2.2))
plt.imshow(face, cmap=plt.cm.gray, vmin=vmin, vmax=256)
plt.savefig("../2.png", dpi=500)
# compressed face
plt.figure(2, figsize=(3, 2.2))
plt.imshow(face_compressed, cmap=plt.cm.gray, vmin=vmin, vmax=vmax)
plt.savefig("../3.png", dpi=500)
# equal bins face
regular_values = np.linspace(0, 256, n_clusters + 1)
regular_labels = np.searchsorted(regular_values, face) - 1
regular_values = .5 * (regular_values[1:] + regular_values[:-1]) # mean
regular_face = np.choose(regular_labels.ravel(), regular_values, mode="clip")
regular_face.shape = face.shape
plt.figure(3, figsize=(3, 2.2))
plt.imshow(regular_face, cmap=plt.cm.gray, vmin=vmin, vmax=vmax)
plt.savefig("../4.png", dpi=500)
# histogram
plt.figure(4, figsize=(3, 2.2))
plt.clf()
plt.axes([.01, .01, .98, .98])
plt.hist(X, bins=256, color='.5', edgecolor='.5')
plt.yticks(())
plt.xticks(regular_values)
values = np.sort(values)
for center_1, center_2 in zip(values[:-1], values[1:]):
plt.axvline(.5 * (center_1 + center_2), color='b')
for center_1, center_2 in zip(regular_values[:-1], regular_values[1:]):
plt.axvline(.5 * (center_1 + center_2), color='b', linestyle='--')
plt.savefig("../5.png", dpi=500)
plt.show()
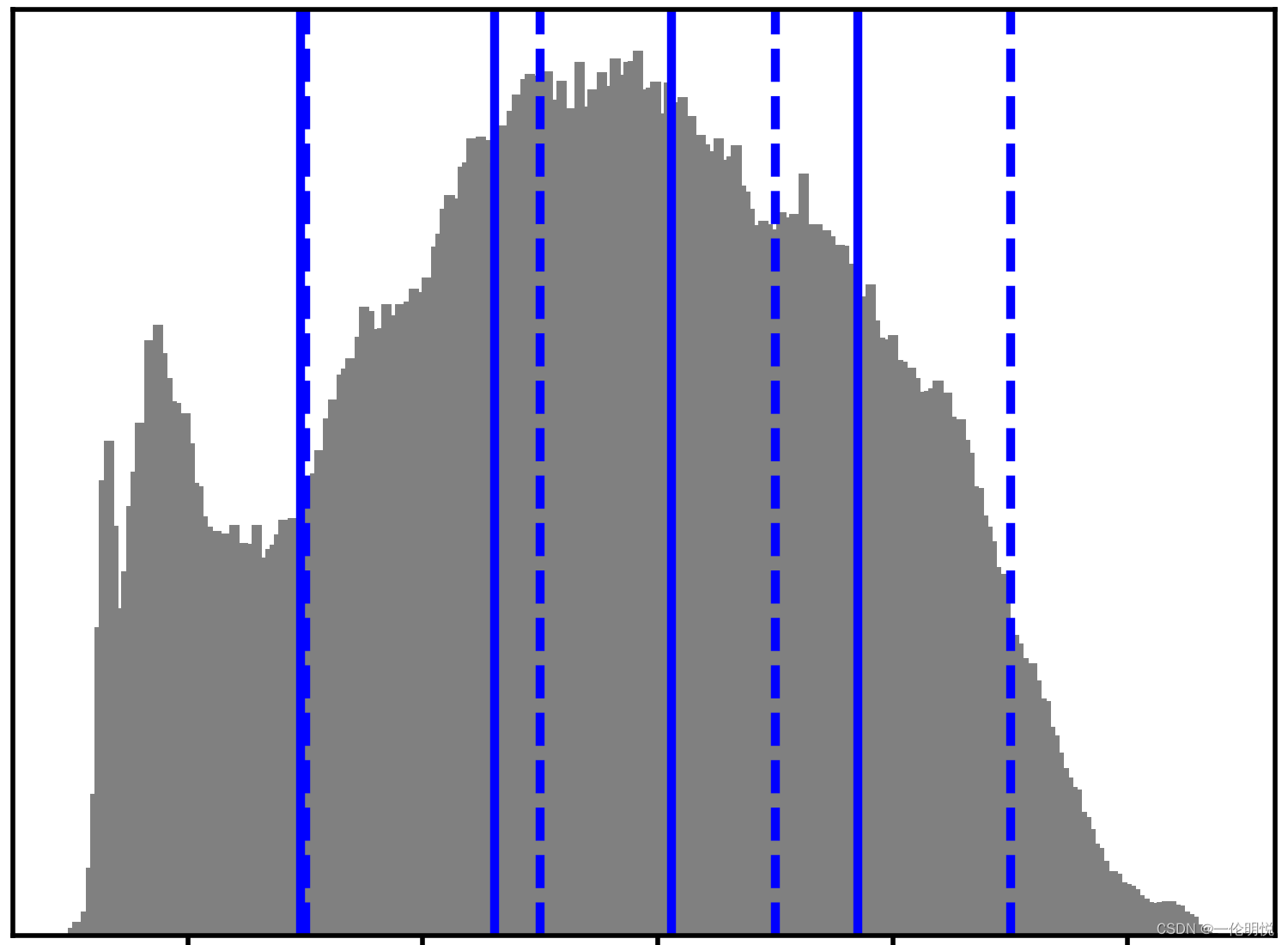
示例运行如下图所示:
第一张图像: 原始图像,保持了原始图像的细节和质量。
第二张图像: 经过k-均值聚类压缩后的图像,可以看到图像失去了一些细节和清晰度,但整体轮廓仍然可识别。
第三张图像: 将原始图像的像素值分成了n_clusters个等距区间,并用每个区间的均值代替,以此作为压缩后图像的像素值。因此,该图像的颜色变得更加平滑,失去了一些细节。
第四张图像: 显示了原始图像的直方图,并用蓝色实线表示k-均值聚类得到的簇中心,用蓝色虚线表示等距区间的中心。可以看出,k-均值聚类的簇中心主要集中在直方图的高峰处。



03-基于亲密传播聚类算法的数据聚类实例
Affinity Propagation(亲和传播)是一种聚类算法,它不需要指定聚类的数量,而是通过数据点之间的相似性来自动确定簇的数量和簇的中心。其原理如下:
相似度矩阵: 首先,计算每对数据点之间的相似度,得到一个相似度矩阵。相似度可以使用欧氏距离、余弦相似度等度量。
消息传递: 然后,每个数据点都向其他数据点发送消息,表示其希望成为其他数据点的聚类中心。这些消息基于数据点之间的相似度以及其他数据点对当前数据点的选择。
责任传递: 在接收到其他数据点的消息后,每个数据点会更新一个“责任值”,表示其选择成为其他数据点聚类中心的程度。
可用性传递: 同时,每个数据点还会更新一个“可用性值”,表示其被其他数据点选择为聚类中心的程度。
聚类中心确定: 迭代更新责任值和可用性值,直到收敛。最终,数据点中的一些点会被选择为聚类中心,而其他点则会被分配到最近的聚类中心所在的簇中。
亲和传播聚类算法的优点是不需要指定聚类的数量,并且对初始值不敏感。然而,它的计算复杂度较高,且对于大型数据集可能不太适用。
下面给出具体代码分析一下应用过程:这段代码演示了如何使用Scikit-Learn中的Affinity Propagation聚类算法对生成的样本数据进行聚类,并通过一系列指标和可视化来评估聚类结果。解释如下:
from sklearn.cluster import AffinityPropagation: 导入Affinity Propagation聚类算法。
from sklearn import metrics: 导入评估聚类结果的指标。
from sklearn.datasets import make_blobs: 导入用于生成聚类样本数据的函数。
生成样本数据:centers = [[1, 1], [-1, -1], [1, -1]]: 定义聚类中心。X, labels_true = make_blobs(...): 生成300个样本数据,其中包含3个聚类中心,每个聚类中心周围有一定的方差(通过cluster_std指定),同时返回真实的标签labels_true作为参考。
进行Affinity Propagation聚类:af = AffinityPropagation(preference=-50).fit(X): 使用Affinity Propagation算法拟合数据。cluster_centers_indices = af.cluster_centers_indices_: 获取聚类中心的索引。labels = af.labels_: 获取每个数据点的聚类标签。
评估聚类结果:使用各种评估指标(同种性、完整性、V-量、调整后的兰特指数、调整后的相互信息、轮廓系数)来量化聚类的性能。
绘制聚类结果的可视化图像:首先导入绘图相关的库和函数。循环遍历每个聚类并使用不同颜色进行可视化。绘制聚类中心和聚类之间的连线,以及每个数据点的位置。
from sklearn.cluster import AffinityPropagation
from sklearn import metrics
from sklearn.datasets import make_blobs
# #############################################################################
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=300, centers=centers, cluster_std=0.5,
random_state=0)
# #############################################################################
# Compute Affinity Propagation
af = AffinityPropagation(preference=-50).fit(X)
cluster_centers_indices = af.cluster_centers_indices_
labels = af.labels_
n_clusters_ = len(cluster_centers_indices)
print('估计的集群数: %d' % n_clusters_)
print("同种: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("完整性: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-量: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("调整后的兰特指数: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("调整后的相互信息: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels))
print("轮廓系数: %0.3f"
% metrics.silhouette_score(X, labels, metric='sqeuclidean'))
# 运行结果如下:
估计的集群数: 3
同种: 0.872
完整性: 0.872
V-量: 0.872
调整后的兰特指数: 0.912
调整后的相互信息: 0.871
轮廓系数: 0.753
# #############################################################################
# Plot result
import matplotlib.pyplot as plt
from itertools import cycle
plt.close('all')
plt.figure(1)
plt.clf()
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
for k, col in zip(range(n_clusters_), colors):
class_members = labels == k
cluster_center = X[cluster_centers_indices[k]]
plt.plot(X[class_members, 0], X[class_members, 1], col + '.')
plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col,
markeredgecolor='k', markersize=14)
for x in X[class_members]:
plt.plot([cluster_center[0], x[0]], [cluster_center[1], x[1]], col)
plt.title('估计的集群数: %d' % n_clusters_)
plt.savefig("../5.png", dpi=500)
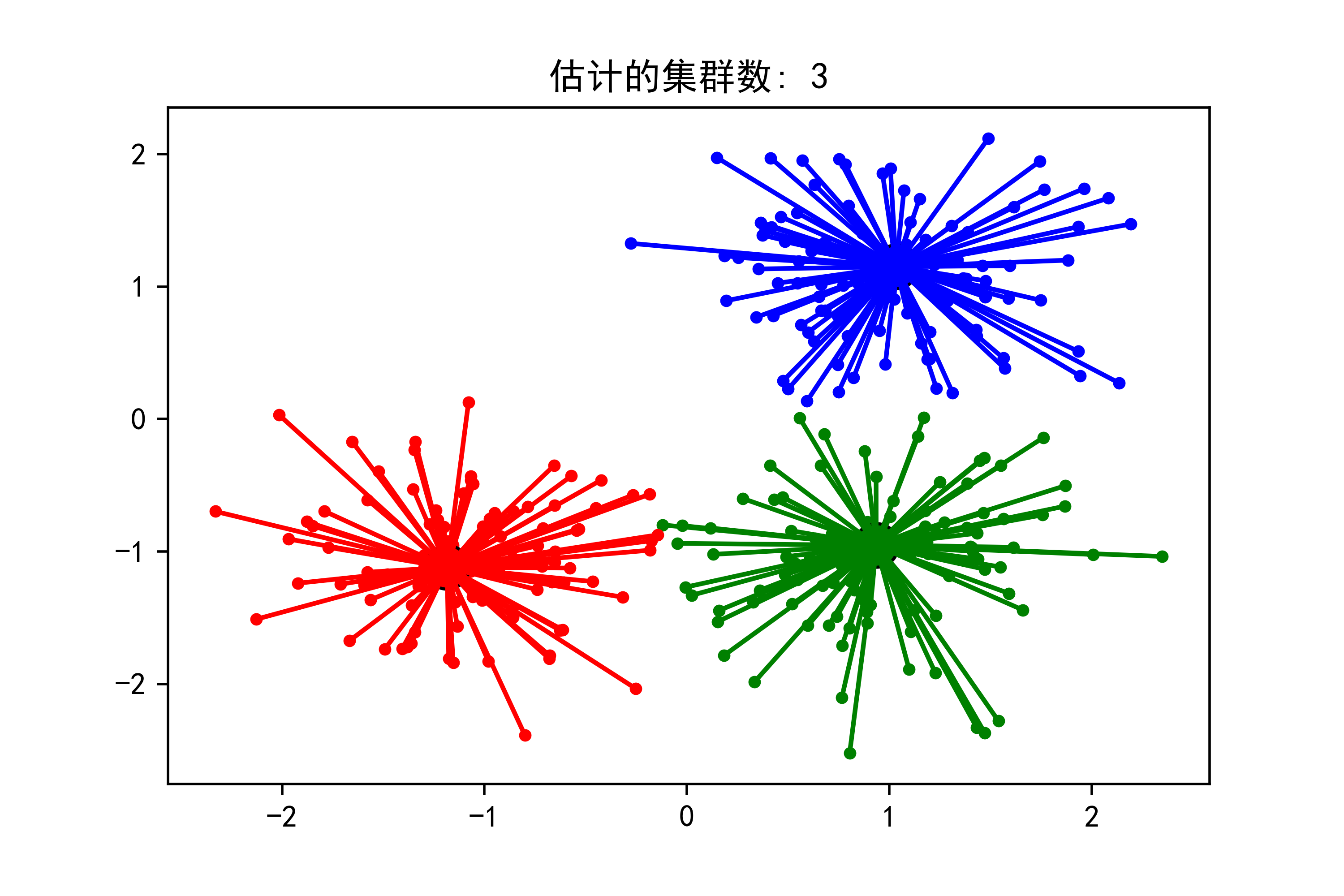
plt.show()示例运行结果如下图所示:
每个颜色代表一个聚类簇,其中大圆点表示聚类中心。
小圆点表示数据点,通过与相应聚类中心之间的连线展示了它们的归属关系。
04-基于带结构和无结构的凝聚聚类算法的实例
凝聚聚类(Agglomerative Clustering)是一种自底向上的层次聚类方法,它将每个数据点视为一个初始聚类,然后逐步将相邻的聚类合并,直到满足某种停止条件为止。在凝聚聚类中,有两种常见的链接方式:带结构的凝聚聚类和无结构的凝聚聚类。
带结构的凝聚聚类:
链接方式(Linkage Criteria):带结构的凝聚聚类通过定义一种相似度度量来衡量两个聚类之间的距离。常见的链接方式包括单链接(single linkage)、完全链接(complete linkage)和平均链接(average linkage)等。
合并策略:该方法从两个最相似的聚类开始,逐步合并距离最近的聚类,直到满足某种停止条件为止。
停止条件:停止条件可以是达到指定的聚类数量,或者当某个距离阈值被达到时停止合并。
无结构的凝聚聚类:
相似度度量:与带结构的凝聚聚类不同,无结构的凝聚聚类不依赖于预定义的相似度度量,而是根据数据点之间的距离来进行合并。
合并策略:该方法根据一定的合并策略(如最小距离或最大距离)来选择哪些聚类应该合并在一起,直到满足某种停止条件为止。
停止条件:通常是达到指定的聚类数量或者当某个距离阈值被达到时停止合并。
凝聚聚类的优点包括易于理解和实现,适用于不同类型的数据,并且可以灵活地选择链接方式和停止条件来适应特定的数据结构和应用场景。然而,凝聚聚类的缺点是它的时间复杂度较高,尤其是对于大型数据集,计算成本可能较高。
下面给出具体代码分析应用过程:这段代码用于生成凝聚聚类的可视化结果,并分析了不同连接方式和连接性对聚类结果的影响。
代码作用解释:
导入必要的库,包括时间、绘图和数值计算库,以及凝聚聚类和k最近邻图的模块。
生成样本数据:在二维平面上生成样本点,这些点呈螺旋形状分布。
创建k最近邻图:使用k最近邻图作为连接性的一种表示方法,用于凝聚聚类中的连接性参数。
遍历不同的连接性和聚类数量组合,以及不同的连接方式,对每种情况进行凝聚聚类,并绘制可视化结果。
import time
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import AgglomerativeClustering
from sklearn.neighbors import kneighbors_graph
# Generate sample data
n_samples = 1500
np.random.seed(0)
t = 1.5 * np.pi * (1 + 3 * np.random.rand(1, n_samples))
x = t * np.cos(t)
y = t * np.sin(t)
X = np.concatenate((x, y))
X += .7 * np.random.randn(2, n_samples)
X = X.T
knn_graph = kneighbors_graph(X, 30, include_self=False)
for connectivity in (None, knn_graph):
for n_clusters in (30, 3):
plt.figure(figsize=(10, 4))
for index, linkage in enumerate(('average',
'complete',
'ward',
'single')):
plt.subplot(1, 4, index + 1)
model = AgglomerativeClustering(linkage=linkage,
connectivity=connectivity,
n_clusters=n_clusters)
t0 = time.time()
model.fit(X)
elapsed_time = time.time() - t0
plt.scatter(X[:, 0], X[:, 1], c=model.labels_,
cmap=plt.cm.nipy_spectral)
plt.title('linkage=%s\n(time %.2fs)' % (linkage, elapsed_time),
fontdict=dict(verticalalignment='top'))
plt.axis('equal')
plt.axis('off')
plt.subplots_adjust(bottom=0, top=.83, wspace=0,
left=0, right=1)
plt.suptitle('n_cluster=%i, connectivity=%r' %
(n_clusters, connectivity is not None), size=17)
plt.savefig("../5.png", dpi=500)
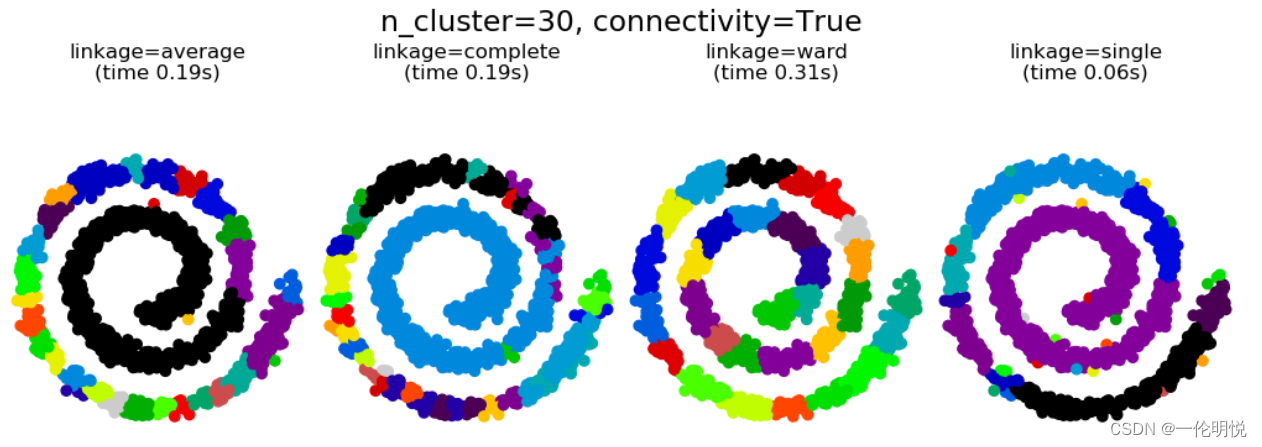
plt.show()示例运行结果如下图所示:
图像分为四个子图,分别对应四种连接方式:average、complete、ward、single。
每个子图展示了相应连接方式下的聚类结果,用不同颜色表示不同的聚类簇。
图像标题显示了连接方式和聚类时间,可以看出不同连接方式的聚类耗时不同。
图像底部的标题指示了聚类数量和连接性是否被考虑。
可以观察到,不同连接方式下的聚类结果差异较大,特别是在聚类数量较少时,这表明连接方式对最终的聚类结果有较大影响。
在连接方式为ward时,聚类簇更加紧凑且形状更规则,而在连接方式为single时,聚类簇较为分散。



05-基于谱聚类算法对图像进行光谱聚类
谱聚类(Spectral Clustering)是一种基于图论和特征向量分解的聚类方法,通常用于处理非凸形状和不规则分布的数据集。下面是关于谱聚类的详细分析和介绍:
算法原理:
构建相似度图:首先根据数据点之间的相似度构建一个相似度矩阵或者图,通常使用高斯核函数或者k最近邻方法来度量相似度。
拉普拉斯矩阵:将相似度矩阵转换为拉普拉斯矩阵,其中有三种常见的形式:无标准化拉普拉斯、对称归一化拉普拉斯和随机游走归一化拉普拉斯。
特征向量分解:对拉普拉斯矩阵进行特征值分解,得到对应的特征向量。
聚类:根据特征向量进行聚类,通常选取前k个特征向量作为聚类的输入,然后通过K-means等方法将这些特征向量聚类成k个簇。
优点:
适应性强:谱聚类适用于各种形状的数据集,包括非凸形状和不规则分布的数据。
效果好:对于高维数据或者数据集中存在复杂结构时,谱聚类通常能取得比较好的聚类效果。
无需事先知道簇数量:相比于K-means等方法,谱聚类不需要提前知道聚类的数量,而是通过特征向量的分布情况进行聚类。
缺点:
计算复杂度高:谱聚类对于大型数据集的计算复杂度相对较高,尤其是在特征向量分解的过程中。
参数选择需谨慎:需要谨慎选择相似度计算方法、拉普拉斯矩阵的形式等参数,否则可能影响聚类结果。
应用领域:
图像分割:谱聚类在图像分割领域有着广泛的应用。
社交网络分析:用于发现社交网络中的社区结构。
生物信息学:应用于蛋白质相互作用网络分析等领域。
总的来说,谱聚类是一种强大的聚类方法,适用于处理复杂结构的数据集,并在图像分割、社交网络分析等领域有着广泛的应用。但需要注意参数选择和计算效率方面的问题。
谱聚类是一种基于图论的聚类算法,它将数据看作是图上的节点,通过节点之间的相似度(通常使用距离或相似度矩阵表示)构建图,然后利用图的特征向量进行聚类。具体步骤包括:
构建相似度矩阵:根据数据点之间的相似度计算得到相似度矩阵,通常使用高斯核函数或者 k 近邻法来度量相似度。
构建拉普拉斯矩阵:基于相似度矩阵构建拉普拉斯矩阵,一般有多种构建方法,常用的是标准化的拉普拉斯矩阵。
计算特征向量:对拉普拉斯矩阵进行特征值分解,得到特征向量,并选择其中特定数量的特征向量作为聚类的特征。
利用 K-means 或者其他聚类方法对特征向量进行聚类。
谱聚类的优点包括对任意形状的簇能够很好地聚类,并且不受维度的影响。但是,它的计算复杂度较高,特别是在大规模数据集上的计算成本较高。此外,谱聚类的参数选择和簇的个数选择也需要一定的经验和技巧。
下面给出具体代码分析应用过程:这段代码用于对图像进行光谱聚类,并绘制聚类结果的可视化图像。下面是对代码的详细解释:
代码解释:
导入必要的库,包括时间、数值计算、图像处理和光谱聚类相关的模块。
加载硬币图像,并对其进行平滑处理和重缩放。
将重缩放后的图像转换为图的表示形式。对图进行加权处理,这里使用指数加权,调节了beta和eps参数。
定义聚类数量,并遍历不同的标签分配方式(‘kmeans’和’discretize’)进行光谱聚类。
绘制聚类结果的可视化图像,其中每个聚类用不同的颜色表示。
import time
import numpy as np
from distutils.version import LooseVersion
from scipy.ndimage.filters import gaussian_filter
import matplotlib.pyplot as plt
import skimage
from skimage.data import coins
from skimage.transform import rescale
from sklearn.feature_extraction import image
from sklearn.cluster import spectral_clustering
# these were introduced in skimage-0.14
if LooseVersion(skimage.__version__) >= '0.14':
rescale_params = {'anti_aliasing': False, 'multichannel': False}
else:
rescale_params = {}
# load the coins as a numpy array
orig_coins = coins()
smoothened_coins = gaussian_filter(orig_coins, sigma=2)
rescaled_coins = rescale(smoothened_coins, 0.2, mode="reflect",
**rescale_params)
graph = image.img_to_graph(rescaled_coins)
beta = 10
eps = 1e-6
graph.data = np.exp(-beta * graph.data / graph.data.std()) + eps
N_REGIONS = 25
for assign_labels in ('kmeans', 'discretize'):
t0 = time.time()
labels = spectral_clustering(graph, n_clusters=N_REGIONS,
assign_labels=assign_labels, random_state=42)
t1 = time.time()
labels = labels.reshape(rescaled_coins.shape)
plt.figure(figsize=(5, 5))
plt.imshow(rescaled_coins, cmap=plt.cm.gray)
for l in range(N_REGIONS):
plt.contour(labels == l,
colors=[plt.cm.nipy_spectral(l / float(N_REGIONS))])
plt.xticks(())
plt.yticks(())
title = '光谱聚类: %s, %.2fs' % (assign_labels, (t1 - t0))
print(title)
plt.title(title)
plt.savefig("../5.png", dpi=500)
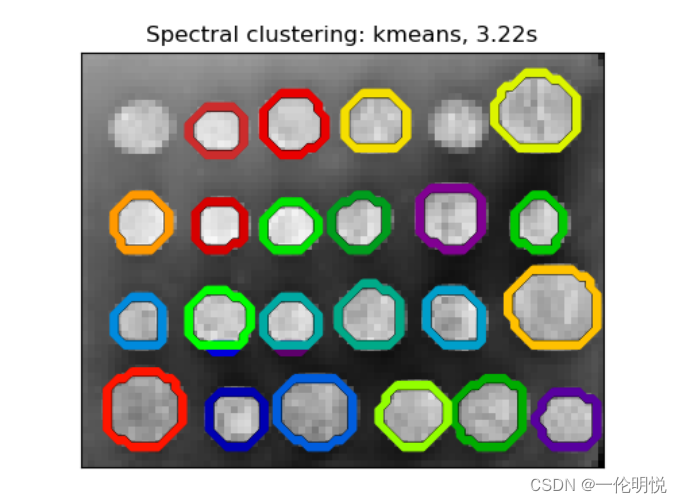
plt.show()示例运行结果如下图所示:
图像展示了两种不同的光谱聚类方法(‘kmeans’和’discretize’)的结果。
每个图像中的轮廓表示一个聚类簇,不同的颜色代表不同的聚类。
图像标题显示了光谱聚类的方法和耗时。
在’kmeans’方法下,轮廓较为清晰,每个聚类簇之间的区分度较高。
而在’discretize’方法下,轮廓略显模糊,聚类簇之间的界限不够清晰。
整体上,光谱聚类在图像分割中展现了较好的效果,能够有效地将图像中的不同区域进行划分。

总结
综上所述,四种聚类算法的总结如下:
K-均值聚类:
算法原理:通过迭代将数据点分配到K个簇中,使得每个数据点与所属簇的中心点的距离最小化。
优点:简单易实现,计算效率高,适用于大型数据集。
缺点:对初始中心点的选择敏感,对异常值敏感,对非凸形状的簇效果较差。
亲密传播聚类算法:
算法原理:基于数据点之间的相似度进行传播,每个数据点根据其相似度向周围的数据点传播消息,最终形成聚类簇。
优点:无需预先确定簇的数量,适用于非凸形状的数据集,对初始参数不敏感。
缺点:对于大型数据集计算复杂度高,需要占用大量内存。
带结构和无结构的凝聚聚类:
算法原理:根据数据点之间的相似度或距离进行层次性合并,形成聚类簇。
优点:能够处理不同形状和大小的簇,不需要预先指定簇的数量。
缺点:在处理大型数据集时,计算复杂度较高,可能需要较长的时间。
谱聚类:
算法原理:基于图论和特征向量分解,通过将数据点表示为图的形式进行聚类。
优点:适用于处理非凸形状和不规则分布的数据集,无需预先知道簇的数量。
缺点:计算复杂度较高,对于大型数据集的处理效率不高,参数选择需谨慎。
总的来说,每种聚类算法都有其特点和适用场景。在选择算法时,需要根据数据集的特点、聚类需求以及计算资源等因素进行综合考虑。
















 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











