







目录
一、Flow-Based General Model
1、概述
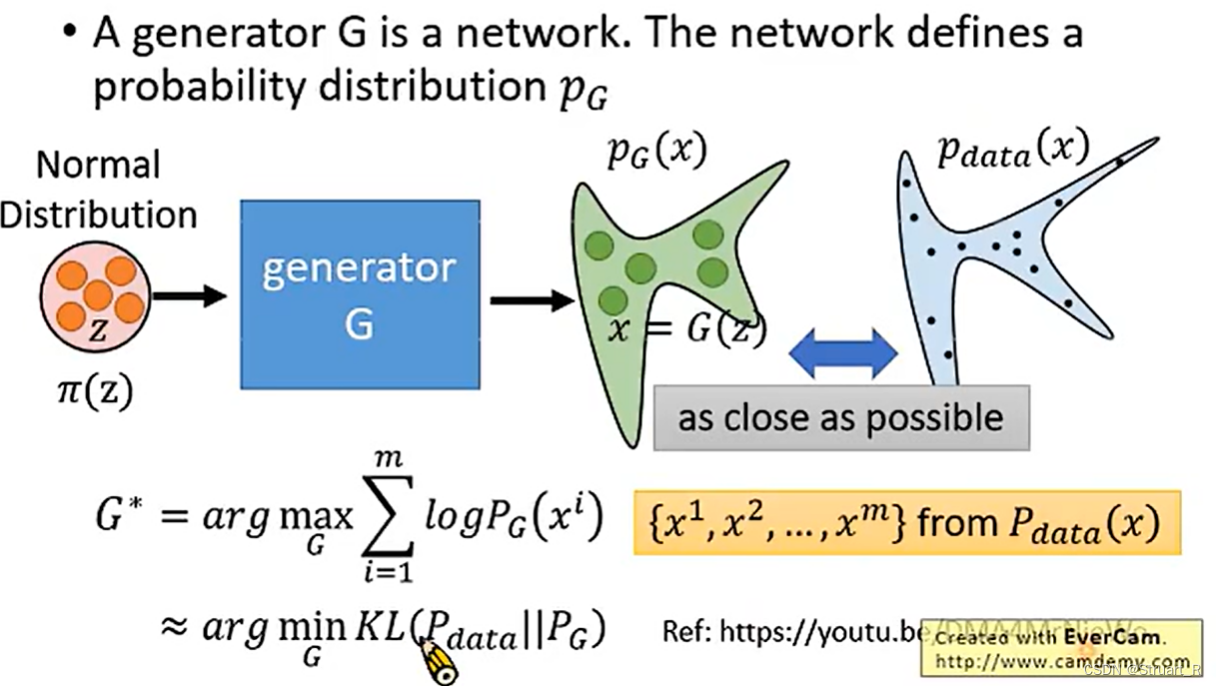
Flow-Based General Model(基于流的生成模型)相较于GAN、VAE和Component-to-Component都有一定的优化。
Flow-Based General Model在训练过程中,将输入数据进行归一化处理得到π(z)(满足正态分布),归一化处理有利于后续生成器(也可以说进行一个函数映射)更加容易的映射到复杂的目标分布。生成器G的目标就是训练一个函数,将标准正态分布映射到目标分布上。
在这之后,模型将采取最大化采样和对数似然的方法(也就是第一个公式)来评估生成器的性能,从而提升使生成样本更加接近目标分布,提升生成器的效果。
而由于求最大值不如最小值容易,所以最大化采样对数似然这个函数近似等于最小化生成样本和真实样本的KL散度值,也就是生成样本和真实样本越接近越好。
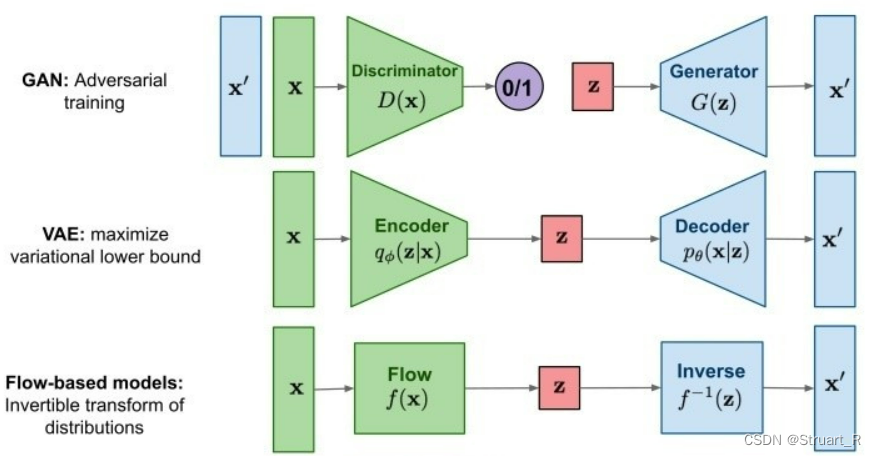
GAN、VAE、FLOW-Based的结构表示:
2、函数映射关系
雅克比行列式:
假定x与z满足这样的关系:
雅克比行列式为:
由于行列式的秩有这种关系存在:
所以也就存在:
结合数学:
由于生成器也可以看做一个函数的映射关系,在假设前提下,结合模型则有,
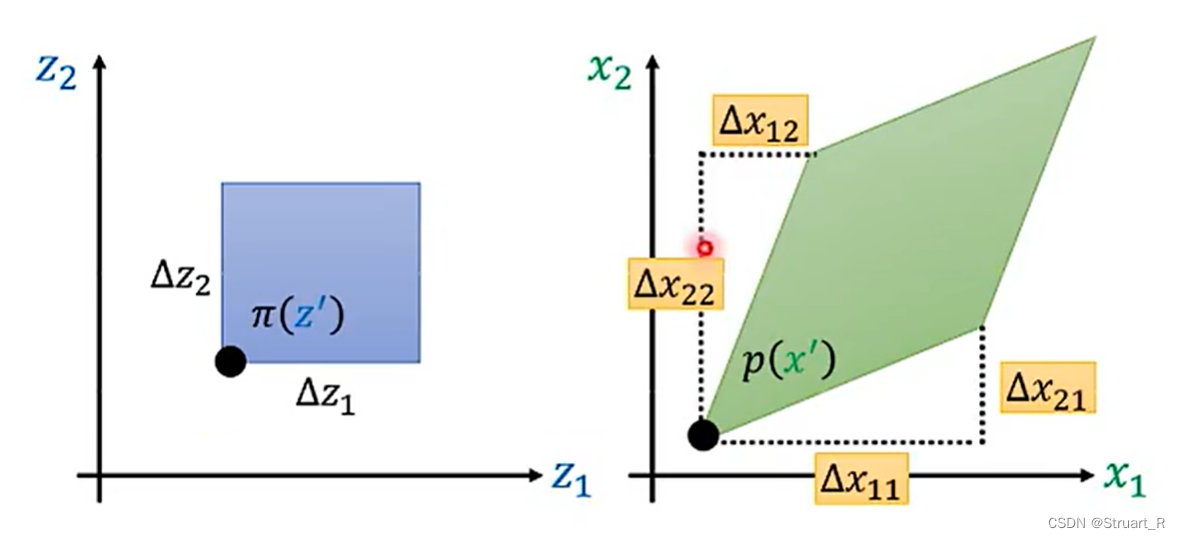
,由下图可知,矩阵的行列式就是图中的面积,而函数的映射变化,也会导致生成器输出的每个向量位置变化,通过计算也可以得到上面的公式成立。
3、Coupling Layer
根据这个公式:,有下面公式成立:
。
由于训练模型过程中,主要使用的是根据z求得x的目标分布,所以,必须求出,也就是求出
,
是要作为训练网络的,必须有前提
是可逆的,满秩的。
而且根据最开始所得计算生成器效果的代价函数也有:
另外生成器也不只可以放一个,也可以进行叠加使用,那么多个G的叠加之后,代价函数的第二项也是进行叠加的,可以见下图。

构造G的网络结构:
(1)限制z与x的维度必须相同,而GAN中z与x可以不同,这也是Flow-Based拉胯的一点。
(2)在Coupling layer中输入数据分成两个部分,分为条件部分和非条件部分,生成器对非条件部分(也就是下图的上层)进行变换生成输出,下图是进行了一次内积和一次相加,通过内积操作可以逐步改变数据的分布,使其逼近目标分布,此时生成器的参数也会不断更新,适应不同数据的分布。
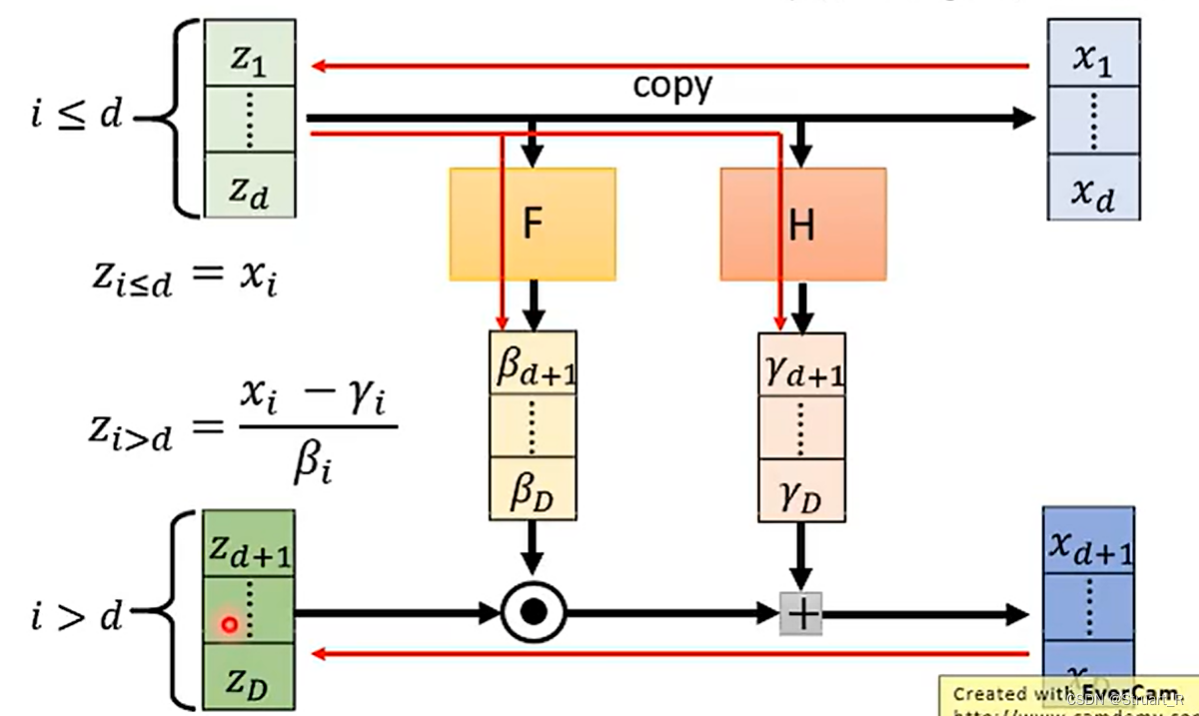
(3)另外也可以正反接多个Coupling layer结构,来促进网络融合,如下图。
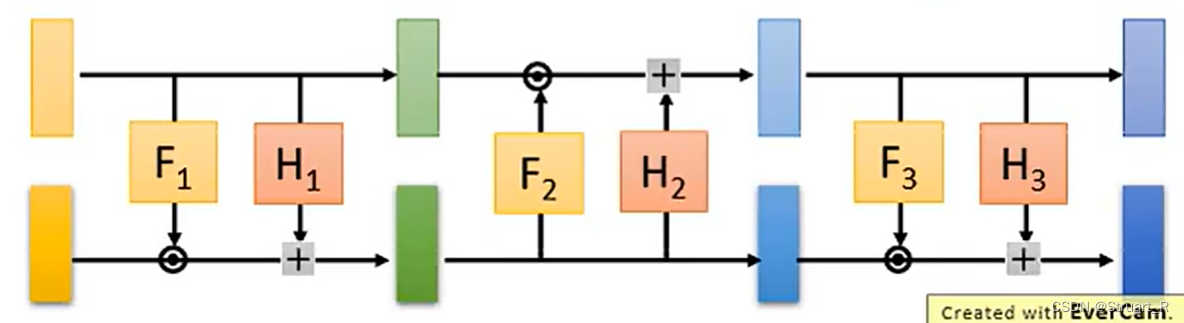
4、Glow
Glow(Generative Flow)是一种基于Flow-Based model的思想,Glow论文中提出了Coupling layer和1*1 卷积。其中1*1卷积在后来的网络结构中仍然广泛使用来打乱channels。
另外Glow的变换都是可逆的,可以满足Flow-Based General Model中生成器G的可逆性。
二、Diffusion Model
1、概述
Diffusion Model是一种广义的扩散生成模型,包含DDPM、DDIM和Stable Diffusion、DALLE2等大模型。
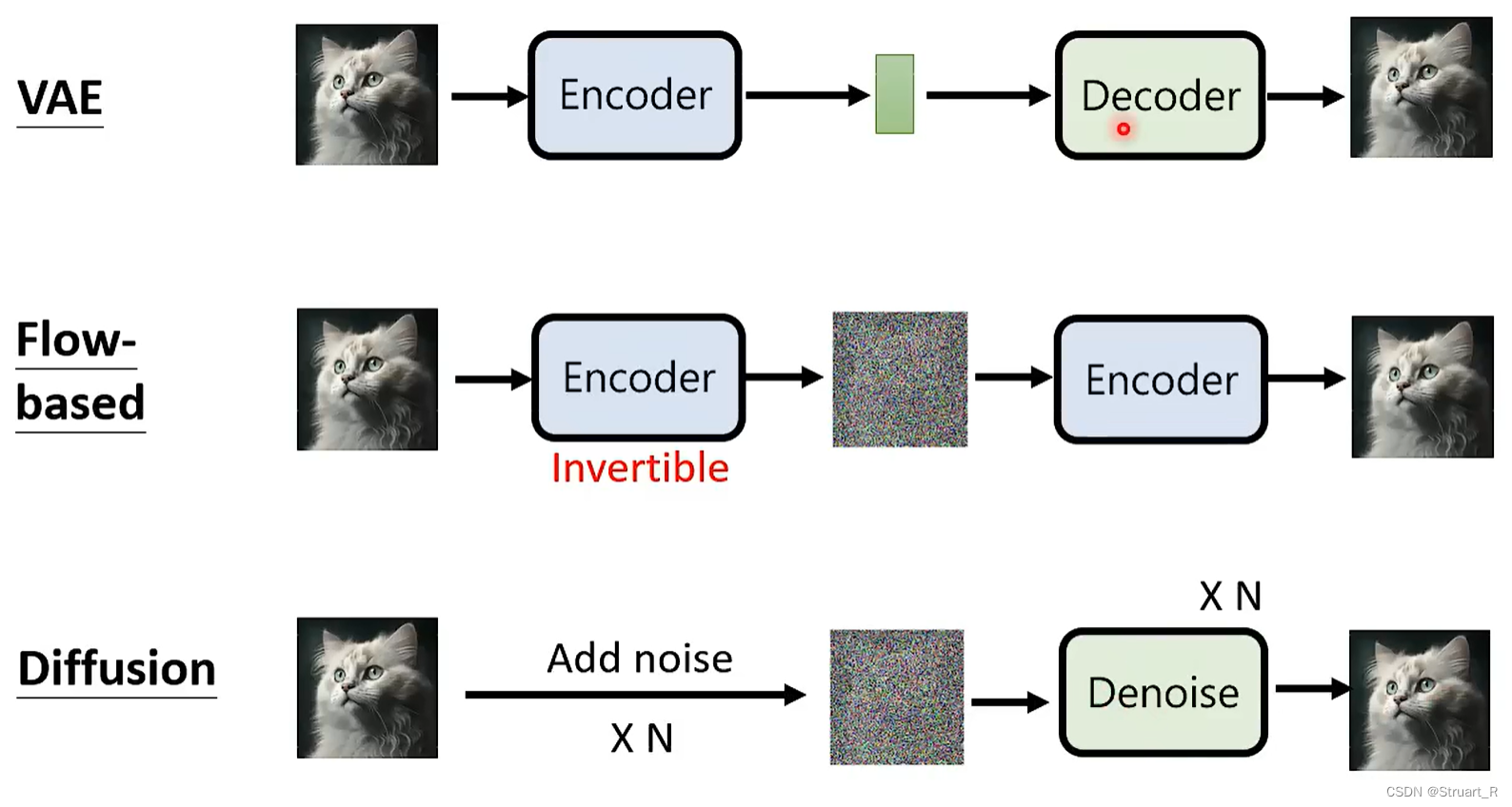
Diffusion Model中比较出众的就是Denoising Diffusion Probabilistic Model(DDPM),通过迭代地应用一系列难以逆转的噪声操作来生成样本。训练中首先通过将原始图片添加迭代多次噪音生成高噪音图,再经过多次迭代的Denoise去噪生成图像。
由于DDPM可以逐步添加噪音,控制噪声的变化速度,所以生成过程是可控的,也不需要类似VAE的低维度隐变量操作,可以获得更加真实和清晰图像。
DDPM关键是训练了一个噪声模型,而没有使用过去一成不变的Encoder-Decoder的结构,使得训练和推理更加高效。
DDPM模型相比于早期的若干模型,在训练模型的高效性和稳定性上大大提高,并降低了生成模型的模式坍塌问题。
2、前向过程
前向过程也就是扩散过程,通过对原始图像添加噪声得到扩散后的图片,也就是在破坏图片。由论文中可知,每一步的扩散过程如下公式:
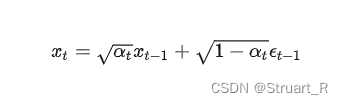
也可以根据计算,
标准满足正态分布,得到:

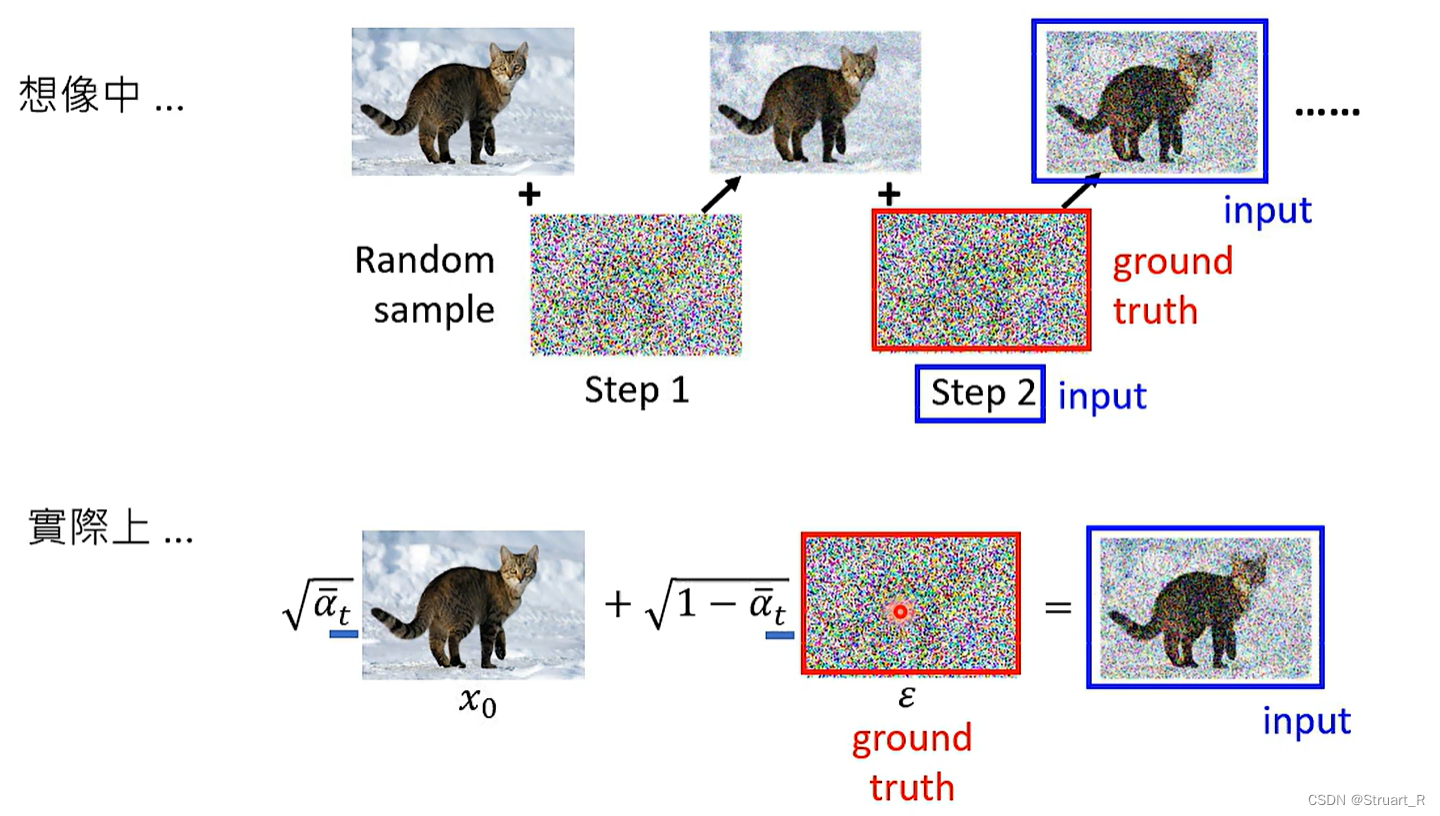
也可以参照下图的图示的扩散模型。
3、反向过程
反向过程就是去噪过程,所谓的去噪denoise,并不是输入第1000轮的生成图像,输出一个与第999轮的近似的生成图像,而是生成与添加噪音接近的噪声图,最后进行降噪(也就是做减法)。
去噪公式如下:
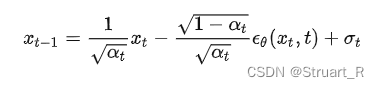
其中,也是一个高斯噪声,是用于表示估测和实际的差距,在DDPM模型中一般使用U-Net来生成这个差距。 在DDPM模型中,去噪过程初始时
值较大,噪声水平较高,生成的样本也与真实样本之间差距较大,而随着训练的进行,
值逐渐减小,噪声水平降低,生成的样本也与真实样本之间的差距较小,生成样本质量更高,模型效果更好。

4、训练获得噪声估计模型
扩散模型中训练的噪声估计模型,也就是,使其预测的噪声与最初加的噪声越接近越好。在论文中用L2范数来估计这个损失函数。
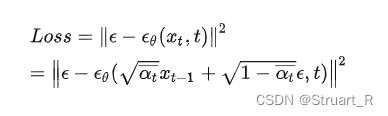
5、生成图片
根据论文伪代码所写,先任意选取一个正态分布中的噪声,再一步步通过噪声模型估计噪声,并将原模型利用去噪公式恢复到
。

下图就是论文中CIFAR10通过不同随机噪音去噪得到的图片。

三、马尔科夫链
这里再提到马尔科夫链其实有点晚了,但是还是应该介绍一下。
马尔科夫链:简而言之就是变量序列的随机变量之间,存在一种特殊的关系,后一时刻的随机变量只依赖于前一刻的随机变量,则称这个随机变量序列具有马尔科夫性,称为马尔科夫链。

在DDPM中,马尔科夫链被用于模拟噪声变化的过程,噪声也是一个随时间变化的马尔科夫链,初始时,噪声水平高,而随着训练进行,噪声水平降低,马尔科夫链的转移概率矩阵可以描述噪声水平从一个step到另一个step的变化规律,从而优化生成模型生成高质量样本。
四、DDIM
DDIM(Diffusion-Decomposed Importance Sampling)为扩散采样算法,目的是从扩散模型中高效生成高质量样本。
DDIM不在是马尔科夫链,而是在DDPM下做了改进,目的是加速迭代速度。
同样的策略还有PLMS策略,也是对DDPM算法进行改进。
另外,后续的Stable Diffusion中也利用DDPM来训练模型,用DDIM来进行快速采样,加快速度。
参考视频:(正课)Diffusion Model 原理剖析 (3_4) (optional)_哔哩哔哩_bilibili














 3902
3902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









