







MoE(Mixture of Experts)架构、Qwen架构与Llama架构的对比与解释
这三种架构在深度学习中各有特色,尤其是在处理大规模语言模型和模型效率方面。以下是对它们的详细解释和对比:
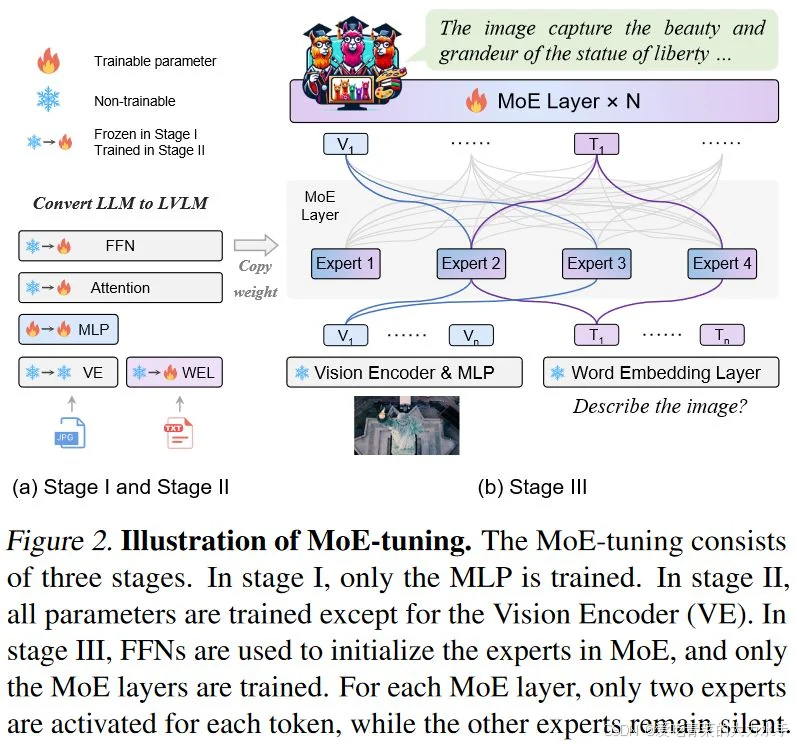
1. MoE(Mixture of Experts)架构
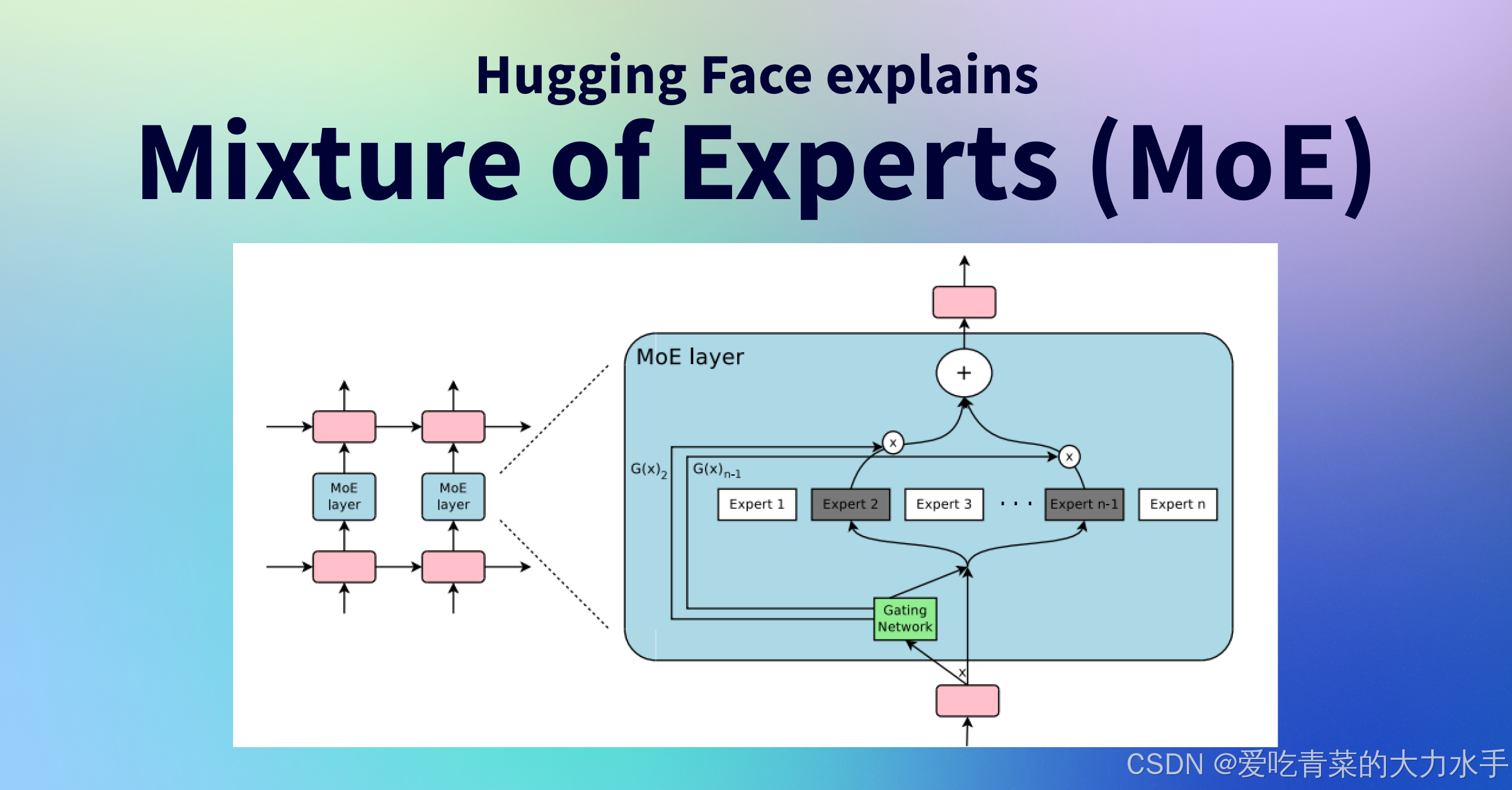
定义与特点:
- MoE架构是一种混合专家模型(Mixture of Experts),旨在提高大规模语言模型的效率。
- MoE架构的基本思想是将模型分成多个专家(子模型),每个专家专注于特定的任务。通过在每个输入数据样本上选择少量的专家进行计算,从而减少计算负载并提高效率。
- 稀疏激活:MoE模型并不是同时激活所有专家,而是根据输入的特定特征选择一部分专家进行计算。
- 例如:对于一个输入文本,只有少数几个专家被激活并处理这个输入,其他专家不参与计算,从而节省计算资源。
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 688
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











