







1、TPA理论
注意力机制(Attention mechanism)通常结合神经网络模型用于序列预测,使得模型更加关注历史信息与当前输入信息的相关部分。时序模式注意力机制(Temporal Pattern Attention mechanism, TPA)由 Shun-Yao Shih 等提出(Shih, Shun-Yao, Sun, Fan-Keng, Lee, Hung-yi. Temporal Pattern Attention for Multivariate Time Series Forecasting[J]. 2019.arXiv:1809.04206),其通过使用 CNN 滤波器提取输入信息中的定长时序模式,使用评分函数确定各时序模式的权值,根据权值的大小得到最后的输出信息。TPA机制的框图如图 1所示
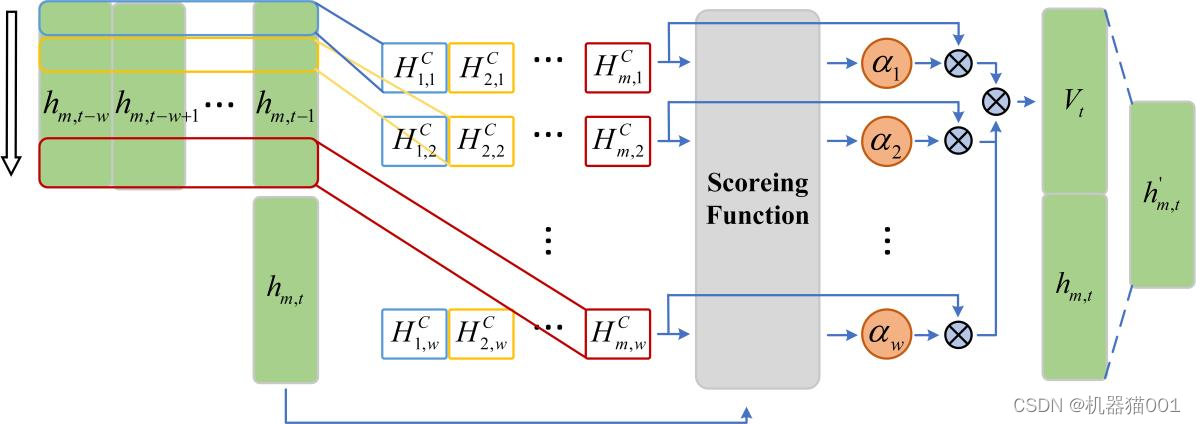
图1 TPA机制
TPA 机制的实现包含以下三个过程,具体参考文献《Shih, Shun-Yao, Sun, Fan-Keng, Lee, Hung-yi. Temporal Pattern Attention for Multivariate Time Series Forecasting》
(1)时序模式的获取
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1695
1695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









