







一、分析主题:
本分析旨在对数据集进行可视化和 T 检验,以探索数据集中的变量之间的关系和差异。通过可视化数据,我们可以直观地了解数据的分布和趋势,而 T 检验则可以帮助我们确定这些差异是否具有统计学意义。
二、具体分析
对一组数据,进行T-test,保存分析结果,并绘制柱状图
读取数据:
df <- read.csv("C:/Users/Administrator/Desktop/画图t检验r/penguins.csv")
df
# 执行 T 检验
# 对数据进行筛选,去除 sex 列中的缺失值
df1<-df[!is.na(df$sex), ]
t_test_result <- t.test(bill_length_mm ~ sex, data = df1)
t_test_result选择 bill_length_mm 特征进行 T 检验,并根据 sex 列来进行分组。接下来,将保存分析结果并绘制柱状图来展示两组样本的 bill_length_mm 均值差异
df1 <- df[!is.na(df$sex), ]:这行代码的目的是创建一个新的数据框 df1,其中移除了 sex 列中的缺失值 NA。!is.na(df$sex) 用于判断 sex 列中是否存在缺失值,并使用 [ ] 筛选出不包含缺失值的行。
t_test_result <- t.test(bill_length_mm ~ sex, data = df1):这是执行 Student's t-test 的部分。t.test() 函数的参数是一个公式,bill_length_mm ~ sex 表示要比较的数值型变量是 bill_length_mm,而分组的因子是 sex。这里的 data = df1 指定了数据来源是 df1 数据框。
t_test_result:这行代码会打印出执行 Student's t-test 后的结果。结果中包含了 t 统计量的数值、p 值以及检验的置信区间等信息。
接下来可视化
# 绘制柱状图
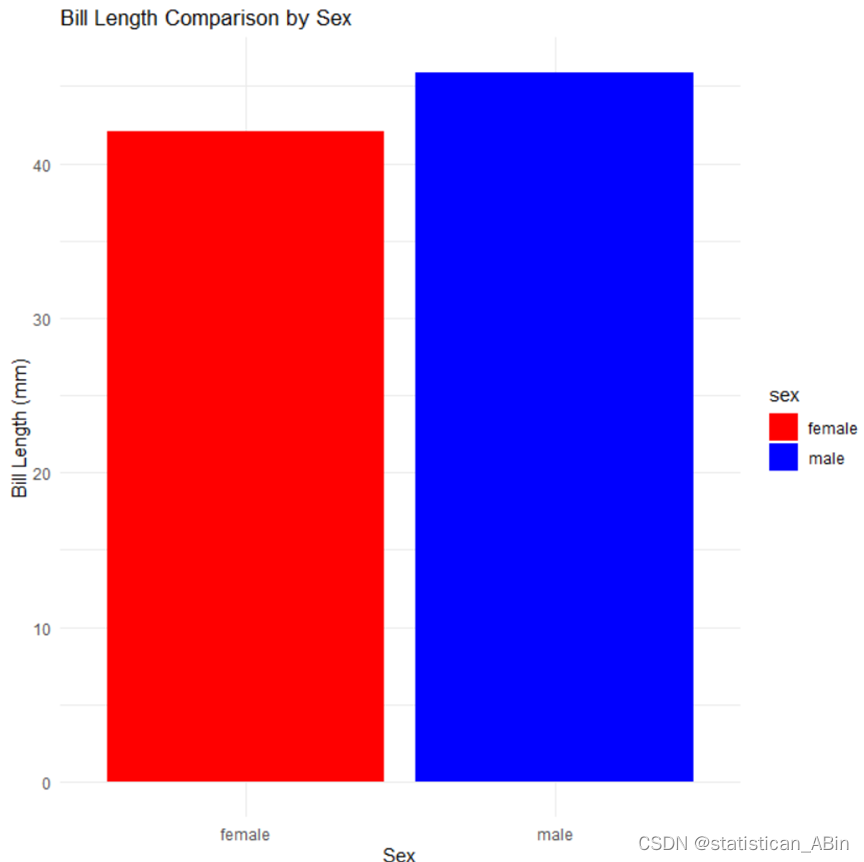
ggplot(df1, aes(x = sex, y = bill_length_mm, fill = sex)) +
geom_bar(stat = "summary", fun = "mean", position = "dodge") +
labs(title = "Bill Length Comparison by Sex",
x = "Sex", y = "Bill Length (mm)") +
theme_minimal() +
scale_fill_manual(values = c("male" = "blue", "female" = "red")) # 自定义颜色ggplot(df1, aes(x = sex, y = bill_length_mm, fill = sex)):使用 ggplot2 创建一个基础图形对象。df1 是数据框,aes() 函数中设置 x 轴为 sex,y 轴为 bill_length_mm,并根据 sex 进行分组。fill = sex 表示用性别进行填充。
geom_bar(stat = "summary", fun = "mean", position = "dodge"):添加柱状图层。stat = "summary" 表示用于计算统计摘要数据,fun = "mean" 表示用平均值来绘制柱状图。position = "dodge" 表示柱状图按性别分组并并列显示。
labs(title = "Bill Length Comparison by Sex", x = "Sex", y = "Bill Length (mm)"):添加图表的标题和坐标轴标签。
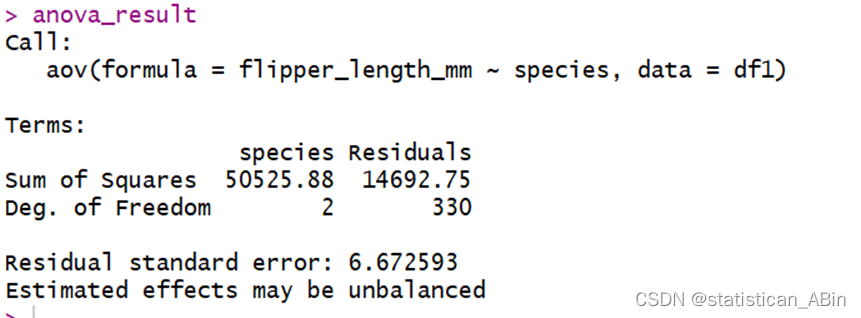
接下来选择 flipper_length_mm 特征进行单因素方差分析,并绘制相应的图表
anova_result 变量将包含ANOVA的分析结果,其中包括不同物种对 flipper_length_mm 的影响是否显著。如果想要查看ANOVA结果的具体信息,你可以直接打印 anova_result 变量,它将显示ANOVA分析的摘要信息。
ANOVA 结果通常包含 F 值、p 值以及其他统计指标
绘制箱线图叠加散点图
# 绘制箱线图叠加散点图
ggplot(df1, aes(x = species, y = flipper_length_mm, fill = species)) +
geom_boxplot() +
geom_jitter(position = position_jitter(width = 0.3), color = "black", size = 2) +
labs(title = "Flipper Length Comparison by Species",
x = "Species", y = "Flipper Length (mm)") +
theme_minimal() +
scale_fill_manual(values = c("Adelie" = "blue", "Biscoe" = "green", "Dream" = "red")) # 自定义颜色
ggplot(df1, aes(x = species, y = flipper_length_mm, fill = species)):创建一个基础图形对象。df1 是数据框,aes() 函数中设置 x 轴为 species,y 轴为 flipper_length_mm,并根据 species 进行分组。fill = species 表示用不同的物种进行填充。
三、小结
-
数据集可视化:通过绘制柱状图、折线图、箱线图等图表,我们可以直观地展示数据的分布和趋势。例如,柱状图可以用于比较不同类别之间的数量差异,折线图可以用于展示时间序列数据的变化趋势,箱线图可以用于展示数据的离散程度和异常值。可视化数据可以帮助我们发现数据中的模式和趋势,从而更好地理解数据。
-
T 检验:T 检验是一种常用的统计方法,用于比较两个或多个样本的均值是否存在显著差异。通过计算 T 统计量和 P 值,我们可以确定这些差异是否具有统计学意义。在进行 T 检验时,我们需要确保样本的独立性、正态性和方差齐性。如果这些条件不满足,我们可能需要使用其他统计方法或进行数据转换。
通过对数据集进行可视化和 T 检验,我们可以更好地理解数据的分布和趋势,以及变量之间的关系和差异。这些分析结果可以为进一步的研究和决策提供参考。在进行数据分析时,我们应该根据数据的特点和研究目的选择合适的可视化方法和统计方法,并对结果进行合理的解释和讨论。















 5790
5790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









