






★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
摘要
作为一种实际的解决方案,传统的视觉Transformer(ViTs)被鼓励模拟任意图像块之间的长距离依赖关系,而全局感受野会导致二次计算成本。视觉Transformer的另一个分支利用了受CNN启发的局部注意力,这种注意力只模拟了小领域内的块交互。虽然这样的解决方案降低了计算成本,但它自然会受到较小的感受野的影响,这可能会限制性能。在本研究中,我们探索了有效的视觉Transformer,以寻求计算复杂度和感受野大小之间的一个更好的权衡。通过分析ViT中全局注意力的块交互,我们发现浅层存在局部性和稀疏性两个关键特征,表明ViT浅层全局依赖的建模存在冗余性。因此,我们提出了多尺度扩展注意力(Multi-Scale Dilated Attention, MSDA)来模拟滑动窗口内的局部和稀疏patch的交互。采用金字塔结构,通过将MSDA块在低层叠加,将全局多头自注意块在高层叠加,构造了一个多尺度空洞 Transformer(DilateFormer)。我们的实验结果表明,我们的DilateFormer在各种视觉任务中都取得了最先进的性能。在ImageNet-1K分类任务上,DilateFormer与现有的最先进的模型相比,以减少70%的FLOPs达到了相当的性能。DilateFormer-Base在ImageNet-1K分类任务中的top-1准确率为85.6%,在COCO对象检测/实例分割任务中的达到了53.5% box mAP/ 46.1% mask mAP,在ADE20K语义分割任务中的MS mIoU准确率为51.1%。
1. DilateFormer
本文通过分析传统ViT全局注意力中Image Patch的相互作用,作者发现网络浅层的注意力矩阵有2个特点:局部性、稀疏性,如图2所示,ViT-Small中第3个多头注意力模块的attention map,红色方块表示query patch。从图中可以看出,得分较高的patch稀疏地分布在query patch周围,距离query patch较远的patch得分普遍偏低。可以利用这一特性减少全局注意力模块的冗余性,以降低计算量。

1.1 滑窗空洞注意力(Sliding Window Dilated Attention,SWDA)
滑窗空洞注意力思想非常简单,主要是受空洞卷积的启发,以Query为中心,并利用空洞方式进行采样Key和Value,从而既扩大了窗口注意力感受野,又不增加计算成本。用公式表示如下:
x i j = Attention ( q i j , K r , V r ) = Softmax ( q i j K r T d k ) V r , 1 ≤ i ≤ W , 1 ≤ j ≤ H , \begin{aligned} x_{i j} & =\operatorname{Attention}\left(q_{i j}, K_{r}, V_{r}\right) \\ & =\operatorname{Softmax}\left(\frac{q_{i j} K_{r}^{T}}{\sqrt{d_{k}}}\right) V_{r}, \quad 1 \leq i \leq W, 1 \leq j \leq H, \end{aligned} xij=Attention(qij,Kr,Vr)=Softmax(dkqijKrT)Vr,1≤i≤W,1≤j≤H,
采样的位置计算如下公式所示:
{ ( i ′ , j ′ ) ∣ i ′ = i + p × r , j ′ = j + q × r } − w 2 ≤ p , q ≤ w 2 \begin{array}{c} \left\{\left(i^{\prime}, j^{\prime}\right) \mid i^{\prime}=i+p \times r, j^{\prime}=j+q \times r\right\} \\ -\frac{w}{2} \leq p, q \leq \frac{w}{2} \end{array} {(i′,j′)∣i′=i+p×r,j′=j+q×r}−2w≤p,q≤2w
1.2 多尺度空洞注意力(Multi-Scale Dilated Attention,MSDA)
如图4所示,基于滑窗空洞注意力,本文提出了一种新的多尺度空洞卷积。主要思想是将头分成多个组,使用不同的空洞率来进行多尺度交互。公式表示如下:
h i = SWDA ( Q i , K i , V i , r i ) , 1 ≤ i ≤ n X = Linear ( Concat [ h 1 , … , h n ] ) \begin{array}{c} h_{i}=\operatorname{SWDA}\left(Q_{i}, K_{i}, V_{i}, r_{i}\right), \quad 1 \leq i \leq n \\ X=\operatorname{Linear}\left(\operatorname{Concat}\left[h_{1}, \ldots, h_{n}\right]\right) \end{array} hi=SWDA(Qi,Ki,Vi,ri),1≤i≤nX=Linear(Concat[h1,…,hn])
本文进一步地提出在浅层使用所提出的多尺度空洞注意力,在深层使用原始的注意力机制。同时为了增强局部性和引入位置编码,本文采用了CPE,即使用一个深度可分离卷积来实现。公式表示如下:
X = CPE ( X ^ ) + X ^ = DwConv ( X ^ ) + X ^ , Y = { MSDA ( Norm ( X ) ) + X , at low-level stages, MHSA ( Norm ( X ) ) + X , at high-level stages, Z = MLP ( Norm ( Y ) ) + Y , \begin{array}{l} X=\operatorname{CPE}(\hat{X})+\hat{X}=\operatorname{DwConv}(\hat{X})+\hat{X}, \\ Y=\left\{\begin{array}{l} \operatorname{MSDA}(\operatorname{Norm}(X))+X, \quad \text { at low-level stages, } \\ \operatorname{MHSA}(\operatorname{Norm}(X))+X, \quad \text { at high-level stages, } \end{array}\right. \\ Z=\operatorname{MLP}(\operatorname{Norm}(Y))+Y, \\ \end{array} X=CPE(X^)+X^=DwConv(X^)+X^,Y={MSDA(Norm(X))+X, at low-level stages, MHSA(Norm(X))+X, at high-level stages, Z=MLP(Norm(Y))+Y,
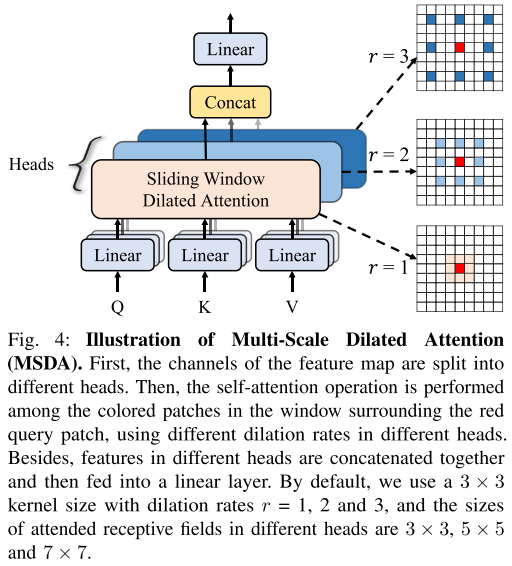
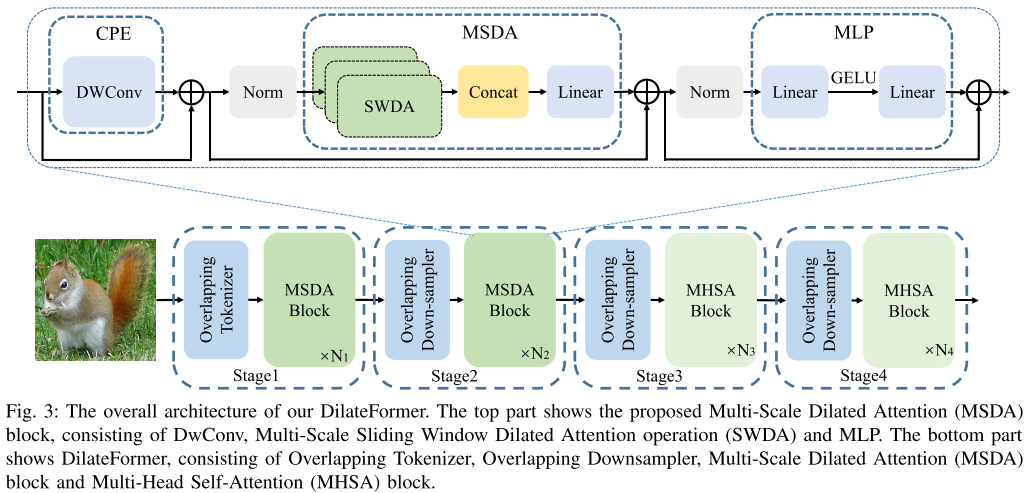
1.3 空洞Transformer(DilateFormer)
基于以上模块,本文提出了一种新的Transformer——DilateFormer。总体架构如图3所示。
2. 代码复现
2.1 下载并导入所需的库
!pip install paddlex
%matplotlib inline
import paddle
import paddle.fluid as fluid
import numpy as np
import matplotlib.pyplot as plt
from paddle.vision.datasets import Cifar10
from paddle.vision.transforms import Transpose
from paddle.io import Dataset, DataLoader
from paddle import nn
import paddle.nn.functional as F
import paddle.vision.transforms as transforms
import os
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import paddlex
from functools import partial
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.Resize((230, 230)),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomResizedCrop(224, scale=(0.6, 1.0)),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
paddlex.transforms.MixupImage(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
paddle.vision.set_image_backend('cv2')
# 使用Cifar10数据集
train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)
print("train_dataset: %d" % len(train_dataset))
print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000
val_dataset: 10000
batch_size=128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 模型的创建
2.3.1 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
2.3.2 DropPath
def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training:
return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor
return output
class DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
2.3.3 DilateFormer模型的创建
class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None,act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class DilateAttention(nn.Layer):
"Implementation of Dilate-attention"
def __init__(self, head_dim, qk_scale=None, attn_drop=0, kernel_size=3, dilation=1):
super().__init__()
self.head_dim = head_dim
self.scale = qk_scale or head_dim ** -0.5
self.kernel_size=kernel_size
self.unfold = nn.Unfold(kernel_sizes=kernel_size, strides=1, paddings = dilation * (kernel_size-1) // 2, dilations=dilation)
self.attn_drop = nn.Dropout(attn_drop)
self.softmax = nn.Softmax(axis=-1)
def forward(self,q, k, v):
#B, C//3, H, W
B, d, H, W = q.shape
q = q.reshape([B, d//self.head_dim, self.head_dim, 1 ,H*W]).transpose((0, 1, 4, 3, 2)) # B,h,N,1,d
k = self.unfold(k).reshape([B, d//self.head_dim, self.head_dim, self.kernel_size*self.kernel_size, H*W]).transpose((0, 1, 4, 2, 3)) #B, h, N, d, k*k
attn = (q @ k) * self.scale # B, h, N, 1, k*k
attn = self.softmax(attn)
attn = self.attn_drop(attn)
v = self.unfold(v).reshape([B, d//self.head_dim, self.head_dim, self.kernel_size*self.kernel_size, H*W]).transpose((0, 1, 4, 3, 2)) # B, h, N, k*k, d
x = (attn @ v).transpose((0, 2, 1, 3, 4)).reshape((B, H, W, d))
return x
class MultiDilatelocalAttention(nn.Layer):
"Implementation of Dilate-attention"
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None,
attn_drop=0.,proj_drop=0., kernel_size=3, dilation=[1, 2, 3]):
super().__init__()
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.dilation = dilation
self.kernel_size = kernel_size
self.scale = qk_scale or head_dim ** -0.5
self.num_dilation = len(dilation)
assert num_heads % self.num_dilation == 0, f"num_heads{num_heads} must be the times of num_dilation{self.num_dilation}!!"
self.qkv = nn.Conv2D(dim, dim * 3, 1, bias_attr=qkv_bias)
self.dilate_attention = nn.LayerList(
[DilateAttention(head_dim, qk_scale, attn_drop, kernel_size, dilation[i])
for i in range(self.num_dilation)])
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
x = x.transpose((0, 3, 1, 2))# B, C, H, W
qkv = self.qkv(x).reshape((B, 3, self.num_dilation, C//self.num_dilation, H, W)).transpose((2, 1, 0, 3, 4, 5))
x = x.reshape((B, self.num_dilation, C//self.num_dilation, H, W)).transpose((1, 0, 3, 4, 2))
# num_dilation, B, H, W, C//num_dilation
for i in range(self.num_dilation):
x[i] = self.dilate_attention[i](qkv[i][0], qkv[i][1], qkv[i][2]) # B, H, W,C//num_dilation
x = x.transpose((1, 2, 3, 0, 4)).reshape((B, H, W, C))
x = self.proj(x)
x = self.proj_drop(x)
return x
class DilateBlock(nn.Layer):
"Implementation of Dilate-attention block"
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0., attn_drop=0.,
drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm, kernel_size=3, dilation=[1, 2, 3]):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.mlp_ratio = mlp_ratio
self.kernel_size = kernel_size
self.dilation = dilation
self.pos_embed = nn.Conv2D(dim, dim, 3, padding=1, groups=dim)
self.norm1 = norm_layer(dim)
self.attn = MultiDilatelocalAttention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, kernel_size=kernel_size, dilation=dilation)
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.pos_embed(x)
x = x.transpose((0, 2, 3, 1)) # B H W C
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
x = x.transpose((0, 3, 1, 2))
#B, C, H, W
return x
class GlobalAttention(nn.Layer):
"Implementation of self-attention"
def __init__(self, dim, num_heads=8, qkv_bias=False,
qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(axis=-1)
def forward(self, x):
B, H, W, C = x.shape
qkv = self.qkv(x).reshape((B, H * W, 3, self.num_heads,
C // self.num_heads)).transpose((2, 0, 3, 1, 4))
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose((0, 1, 3, 2))) * self.scale
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose((0, 2, 1, 3)).reshape((B, H, W, C))
x = self.proj(x)
x = self.proj_drop(x)
return x
class GlobalBlock(nn.Layer):
"""
Implementation of Transformer
"""
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0.,
attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,
):
super().__init__()
self.pos_embed = nn.Conv2D(dim, dim, 3, padding=1, groups=dim)
self.norm1 = norm_layer(dim)
self.attn = GlobalAttention(dim, num_heads=num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop)
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.pos_embed(x)
x = x.transpose((0, 2, 3, 1)) # B H W C
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
x = x.transpose((0, 3, 1, 2))
return x
class PatchEmbed(nn.Layer):
"""Image to Patch Embedding.
"""
def __init__(self, img_size=224, in_chans=3, hidden_dim=16,
patch_size=4, embed_dim=96):
super().__init__()
img_size = (img_size, img_size)
patch_size = (patch_size, patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.img_size = img_size
# Conv stem
self.proj = nn.Sequential(
nn.Conv2D(in_chans, hidden_dim, kernel_size=3, stride=1,
padding=1, bias_attr=False), # 224x224
nn.BatchNorm2D(hidden_dim),
nn.GELU( ),
nn.Conv2D(hidden_dim, int(hidden_dim*2), kernel_size=3, stride=2,
padding=1, bias_attr=False), # 112x112
nn.BatchNorm2D(int(hidden_dim*2)),
nn.GELU( ),
nn.Conv2D(int(hidden_dim*2), int(hidden_dim*4), kernel_size=3, stride=1,
padding=1, bias_attr=False), # 112x112
nn.BatchNorm2D(int(hidden_dim*4)),
nn.GELU( ),
nn.Conv2D(int(hidden_dim*4), embed_dim, kernel_size=3, stride=2,
padding=1, bias_attr=False), # 56x56
)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x) # B, C, H, W
return x
class PatchMerging(nn.Layer):
""" Patch Merging Layer.
"""
def __init__(self, in_channels, out_channels, norm_layer=nn.BatchNorm2D):
super().__init__()
self.proj = nn.Sequential(
nn.Conv2D(in_channels, out_channels, kernel_size=3, stride=2, padding=1),
norm_layer(out_channels),
)
def forward(self, x):
#x: B, C, H ,W
x = self.proj(x)
return x
class Dilatestage(nn.Layer):
""" A basic Dilate Transformer layer for one stage.
"""
def __init__(self, dim, depth, num_heads, kernel_size, dilation,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0.,
attn_drop=0., drop_path=0., act_layer=nn.GELU,
norm_layer=nn.LayerNorm, downsample=True):
super().__init__()
# build blocks
self.blocks = nn.LayerList([
DilateBlock(dim=dim, num_heads=num_heads,
kernel_size=kernel_size, dilation=dilation,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)])
# patch merging layer
self.downsample = PatchMerging(dim, int(dim * 2)) if downsample else nn.Identity()
def forward(self, x):
for blk in self.blocks:
x = blk(x)
x = self.downsample(x)
return x
class Globalstage(nn.Layer):
""" A basic Transformer layer for one stage."""
def __init__(self, dim, depth, num_heads, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,
downsample=True):
super().__init__()
# build blocks
self.blocks = nn.LayerList([
GlobalBlock(dim=dim, num_heads=num_heads,
mlp_ratio=mlp_ratio,qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)])
# patch merging layer
self.downsample = PatchMerging(dim, int(dim*2)) if downsample else nn.Identity()
def forward(self, x):
for blk in self.blocks:
x = blk(x)
x = self.downsample(x)
return x
class Dilateformer(nn.Layer):
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dim=96,
depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], kernel_size=3, dilation=[1, 2, 3],
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.1,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6),
dilate_attention=[True, True, False, False],
downsamples=[True, True, True, False]):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
norm_layer = norm_layer or partial(nn.LayerNorm, epsilon=1e-6)
#patch embedding
self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size,
in_chans=in_chans, embed_dim=embed_dim)
dpr = [x.item() for x in paddle.linspace(0, drop_path, sum(depths))]
self.stages = nn.LayerList()
for i_layer in range(self.num_layers):
if dilate_attention[i_layer]:
stage = Dilatestage(dim=int(embed_dim * 2 ** i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
kernel_size=kernel_size,
dilation=dilation,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=downsamples[i_layer]
)
else:
stage = Globalstage(dim=int(embed_dim * 2 ** i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=downsamples[i_layer]
)
self.stages.append(stage)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1D(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
tn = nn.initializer.TruncatedNormal(std=.02)
zeros = nn.initializer.Constant(0.)
ones = nn.initializer.Constant(1.)
if isinstance(m, nn.Linear):
tn(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
zeros(m.bias)
elif isinstance(m, (nn.Conv1D, nn.Conv2D)):
tn(m.weight)
if m.bias is not None:
zeros(m.bias)
elif isinstance(m, (nn.LayerNorm, nn.GroupNorm)):
zeros(m.bias)
ones(m.weight)
def forward_features(self, x):
x = self.patch_embed(x)
for stage in self.stages:
x = stage(x)
x = x.flatten(2).transpose((0, 2, 1))
x = self.norm(x) # B L C
x = self.avgpool(x.transpose((0, 2, 1))) # B C 1
x = paddle.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
2.3.4 模型的参数
# DilateFormer-T
model = Dilateformer(depths=[2, 2, 6, 2], embed_dim=72, num_heads=[ 3, 6, 12, 24], num_classes=10)
paddle.summary(model, (1, 3, 224, 224))

# DilateFormer-S
model = Dilateformer(depths=[3, 5, 8, 3], embed_dim=72, num_heads=[ 3, 6, 12, 24], num_classes=10)
paddle.summary(model, (1, 3, 224, 224))

# DilateFormer-B
model = Dilateformer(depths=[4, 8, 10, 3], embed_dim=96, num_heads=[ 3, 6, 12, 24], num_classes=10)
paddle.summary(model, (1, 3, 224, 224))

2.4 训练
learning_rate = 0.0003
n_epochs = 50
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model'
# DilateFormer-T
model = Dilateformer(depths=[2, 2, 6, 2], embed_dim=72, num_heads=[ 3, 6, 12, 24], num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
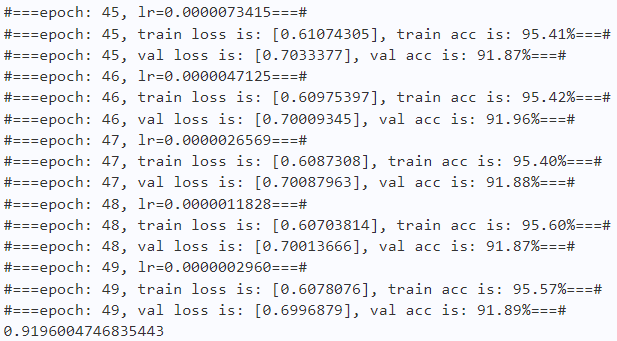
2.5 结果分析
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
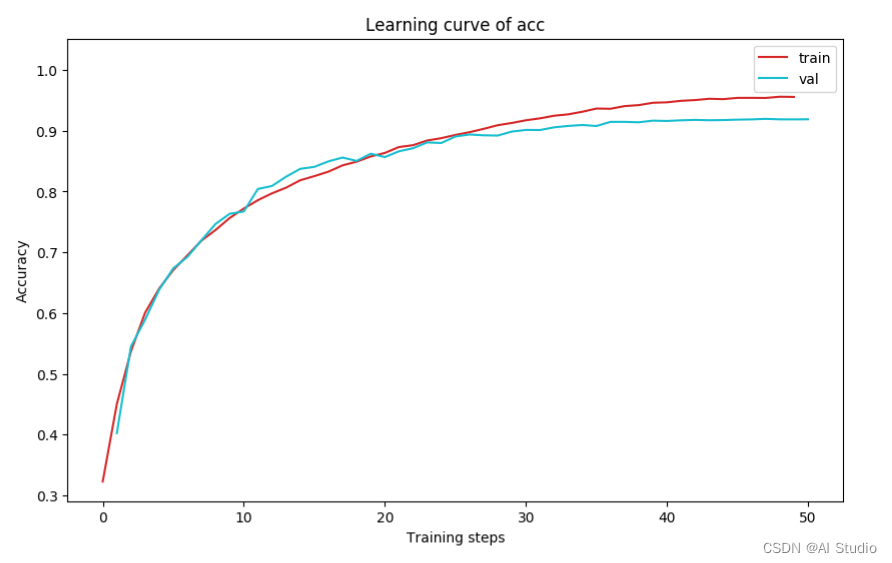
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
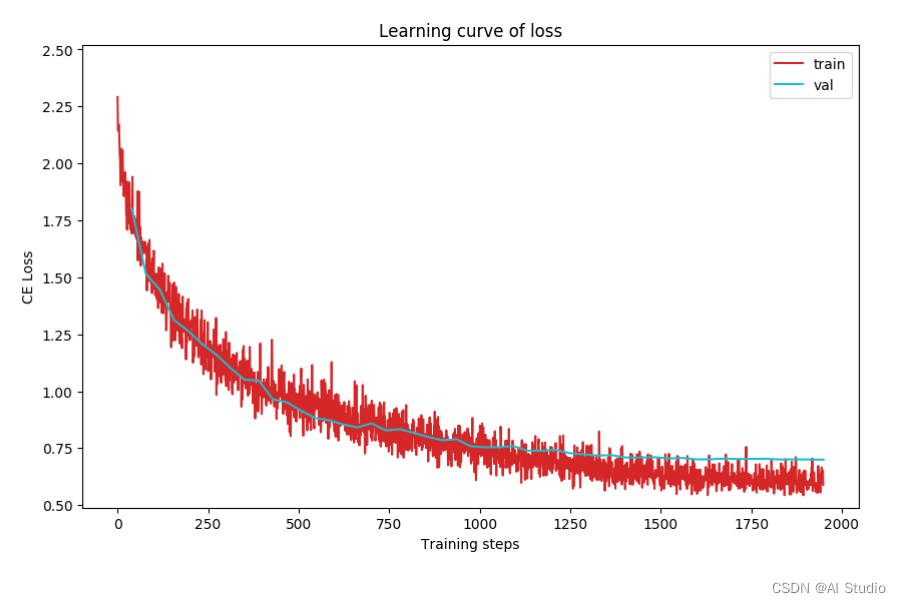
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model'
model = Dilateformer(depths=[2, 2, 6, 2], embed_dim=72, num_heads=[ 3, 6, 12, 24], num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:338
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [
'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog',
'horse', 'ship', 'truck']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if paddle.is_tensor(img):
ax.imshow(img.numpy())
else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i])
return axes
work_path = 'work/model'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = Dilateformer(depths=[2, 2, 6, 2], embed_dim=72, num_heads=[ 3, 6, 12, 24], num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

!pip install interpretdl
import interpretdl as it
work_path = 'work/model'
model = Dilateformer(depths=[2, 2, 6, 2], embed_dim=72, num_heads=[ 3, 6, 12, 24], num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
lime = it.LIMECVInterpreter(model)
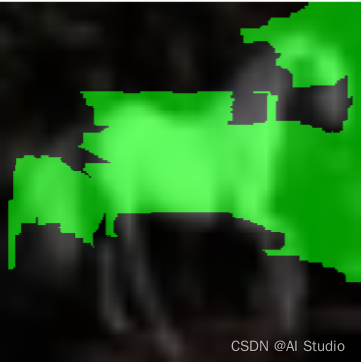
lime_weights = lime.interpret(X.numpy()[3], interpret_class=y.numpy()[3], batch_size=100, num_samples=10000, visual=True)
100%|██████████| 10000/10000 [01:19<00:00, 125.09it/s]

lime_weights = lime.interpret(X.numpy()[13], interpret_class=y.numpy()[13], batch_size=100, num_samples=10000, visual=True)
100%|██████████| 10000/10000 [01:20<00:00, 124.62it/s]
:20<00:00, 124.62it/s]
总结
本文通过对原始Transformer进行分析,发现早期阶段注意力有两个特性——稀疏性和局部性,这导致在早期阶段使用原始注意力会造成大量冗余。由此本文受空洞卷积启发,使用空洞注意力来扩大窗口注意力的感受野,同时不增加计算成本。
参考文献
此文章为搬运
原项目链接

















 1232
1232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









