







 本文详细介绍了如何在YOLOv5中应用ShuffleAttention、ECA、EffectiveSE和SE注意力机制,通过在common.py和yolo.py中加入相应代码,并配置yaml文件,提升了模型性能。ShuffleAttention结合了组卷积、空间和通道注意力,ECA模块则提出了一种轻量级通道注意力,EffectiveSE是对SE的改进,减少了通道信息损失。实验证明,这些改进在目标检测任务中带来了性能提升。
本文详细介绍了如何在YOLOv5中应用ShuffleAttention、ECA、EffectiveSE和SE注意力机制,通过在common.py和yolo.py中加入相应代码,并配置yaml文件,提升了模型性能。ShuffleAttention结合了组卷积、空间和通道注意力,ECA模块则提出了一种轻量级通道注意力,EffectiveSE是对SE的改进,减少了通道信息损失。实验证明,这些改进在目标检测任务中带来了性能提升。
目录
1.3 yolov5s_ShuffleAttention.yaml
1. ShuffleAttention

论文:https://arxiv.org/pdf/2102.00240.pdf
提出了一个有效的Shuffle Attention(SA)模块来解决此问题,该模块采用Shuffle单元有效地结合了两种类型的注意力机制。具体而言,SA首先将通道维分组为多个子特征,然后再并行处理它们。然后,对于每个子特征,SA利用Shuffle Unit在空间和通道维度上描绘特征依赖性。之后,将所有子特征汇总在一起,并采用“channel shuffle”运算符来启用不同子特征之间的信息通信。
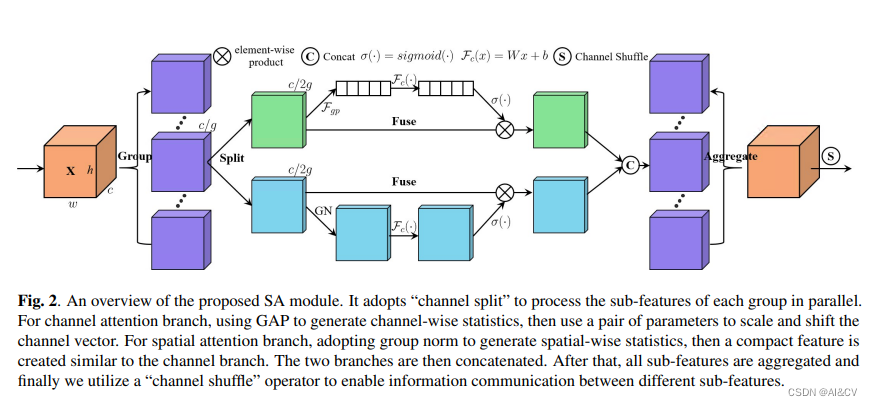
SA的设计思想结合了组卷积(为了降低计算量),空间注意力机制(使用GN实现),通道注意力机制(类似SENet),ShuffleNetV2(使用Channel Shuffle融合不同组之间的信息)
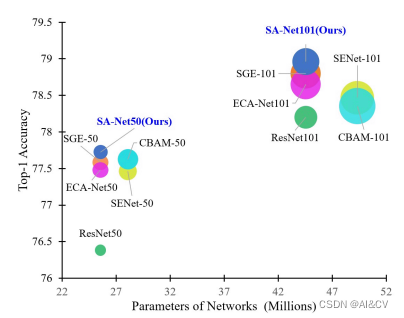
可以看到,要比ECA-Net等模型效果更好,并且要比baseline ResNet50的top1高出1.34%。同样的在ResNet-101为基础添加SA模块,也要比baseline 的top1要高出了0.76%。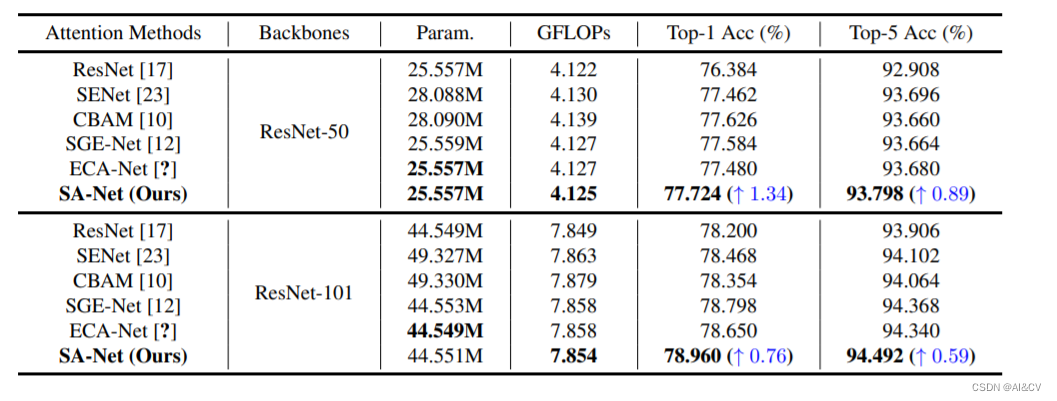
1.1 加入 common.py中
###################### ShuffleAttention #### start by AI&CV ###############################
import torch
from torch import nn
from torch.nn import init
from torch.nn.parameter import Parameter
class ShuffleAttention(nn.Module):
def __init__(self, channel=512, reduction=16, G=8):
super().__init__()
self.G = G
self.channel = channel
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))
self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sigmoid = nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
@staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# flatten
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.size()
# group into subfeatures
x = x.view(b * self.G, -1, h, w) # bs*G,c//G,h,w
# channel_split
x_0, x_1 = x.chunk(2, dim=1) # bs*G,c//(2*G),h,w
# channel attention
x_channel = self.avg_pool(x_0) # bs*G,c//(2*G),1,1
x_channel = self.cweight * x_channel + self.cbias # bs*G,c//(2*G),1,1
x_channel = x_0 * self.sigmoid(x_channel)
# spatial attention
x_spatial = self.gn(x_1) # bs*G,c//(2*G),h,w
x_spatial = self.sweight * x_spatial + self.sbias # bs*G,c//(2*G),h,w
x_spatial = x_1 * self.sigmoid(x_spatial) # bs*G,c//(2*G),h,w
# concatenate along channel axis
out = torch.cat([x_channel, x_spatial], dim=1) # bs*G,c//G,h,w
out = out.contiguous().view(b, -1, h, w)
# channel shuffle
out = self.channel_shuffle(out, 2)
return out
###################### ShuffleAttention #### end by AI&CV ###############################1.2 加入yolo.py中:
elif m is ShuffleAttention:
c1, c2 = ch[f], args[0]
if c2 != nc:
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, *args[1:]]1.3 yolov5s_ShuffleAttention.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, ShuffleAttention, [1024]], # 24
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.ECA

论文:https://arxiv.org/pdf/1910.03151.pdf
本文的贡献总结如下:
- 对SE模块进行了剖析,并分别证明了避免降维和适当的跨通道交互对于学习高性能和高效率的通道注意力是重要的。
- 在以上分析的基础上,提出了一种高效通道注意模块(ECA),在CNN网络上提出了一种极轻量的通道注意力模块,该模块增加的模型复杂度小,提升效果显著。
- 在ImageNet-1K和MS COCO上的实验结果表明,本文提出的方法具有比目前最先进的CNN模型更低的模型复杂度,与此同时,本文方法却取得了非常有竞争力的结果。
作者设计了一个高效的channel attention机制,该方法保留了原有的通道一对一权重更新,并且通过local cross-channel interaction来提升结果。此外作者还设计了一个自动调节kernel size的机制来决定交叉学习的覆盖率。通过该ECA模块,作者在几乎一样的参数上获得了分类top-1 acc 2%的提升
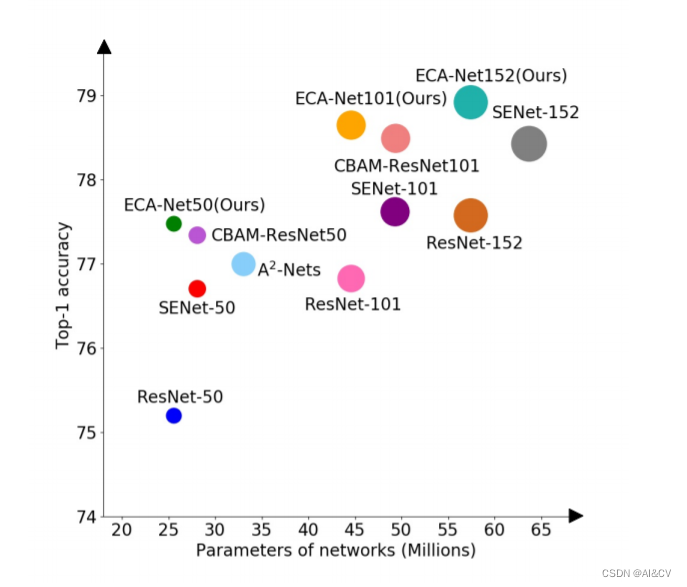
ECA(ECA-Net)是一种新的卷积神经网络结构,它的优势在于以下几点:
-
能够有效地捕捉长距离依赖关系。ECA-Net引入了一种新的通道注意力机制,可以对不同通道的特征进行加权,从而使网络能够更好地捕捉长距离依赖关系。
-
参数量小、计算效率高。ECA-Net的参数量比传统的卷积神经网络更小,同时也能够在保证准确率的前提下大大提高计算效率。
-
可以适应不同的输入尺寸。ECA-Net可以适应不同的输入尺寸,因此在处理不同大小的图像时具有很好的适应性。
总的来说,ECA-Net是一种非常有前途的卷积神经网络结构,它具有良好的性能和高效的计算能力,可以在计算机视觉等领域得到广泛的应用。
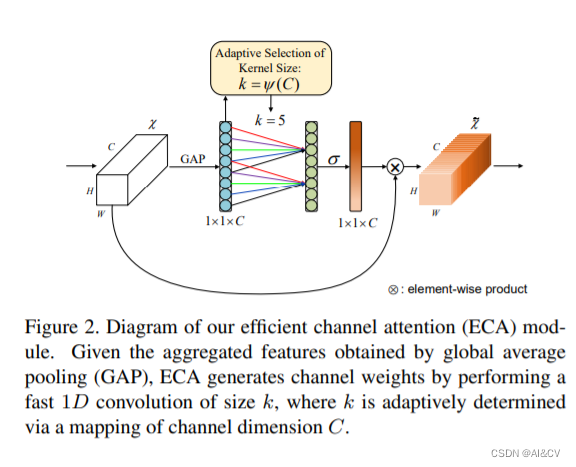
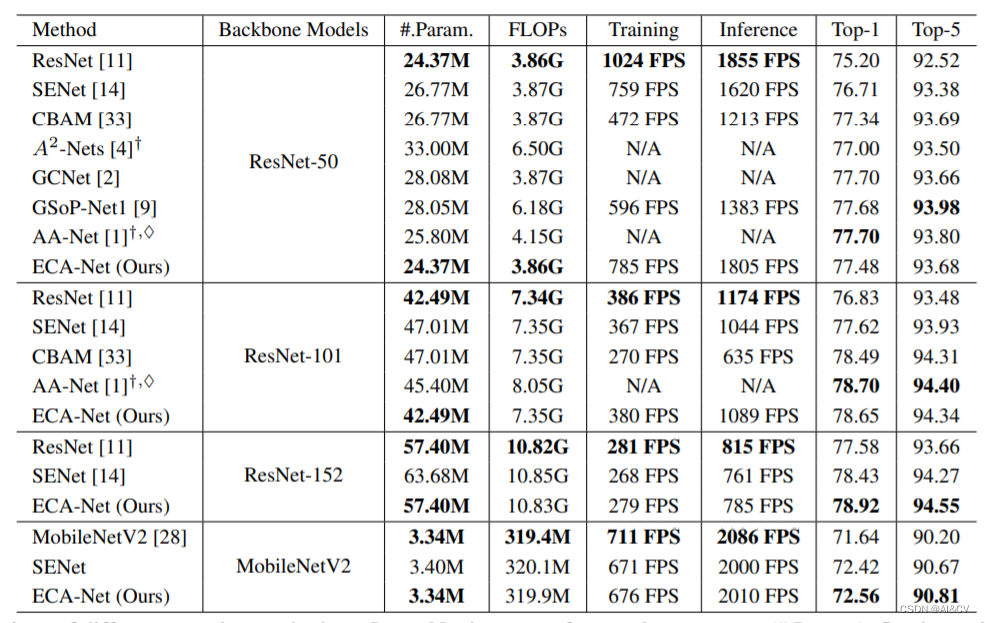
比较了不同的注意力方法在ImageNet数据集上的网络参数(param),浮点运算每秒(FLOPs),训练或推理速度(帧每秒,FPS), Top-1/Top-5的准确性(%)。
 2.1 加入
2.1 加入 common.py中
###################### ECAAttention #### start by AI&CV ###############################
class ECAAttention(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, c1, k_size=3):
super(ECAAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
###################### ECAAttention #### end by AI&CV ###############################2.2 加入yolo.py中:
def parse_model(d, ch, verbose=True): 加入以下代码
elif m is ECAAttention:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, *args[1:]]2.3 yolov5s_ECAAttention.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, ECAAttention, [1024]], # 24
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
3.SENet

Squeeze-and-Excitation Networks(SENet)是由自动驾驶公司Momenta在2017年公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率。这个结构是2017 ILSVR竞赛的冠军,top5的错误率达到了2.251%,比2016年的第一名还要低25%,可谓提升巨大。
SE是指"Squeeze-and-Excitation",是一种用于增强卷积神经网络(CNN)的注意力机制。SE网络结构由Jie Hu等人在2018年提出,其核心思想是在卷积神经网络中引入一个全局的注意力机制,以自适应地学习每个通道的重要性。
SE网络通过两个步骤来实现注意力机制:压缩和激励。在压缩步骤中,SE网络会对每个通道的特征图进行全局池化,将其压缩成一个标量。在激励步骤中,SE网络会通过一个全连接层,将压缩后的特征向量转换为一个权重向量,用于对每个通道的特征图进行加权。
通过引入SE模块,CNN可以自适应地学习每个通道的重要性,从而提高模型的表现能力。SE网络在多个图像分类任务中取得了很好的效果,并被广泛应用于各种视觉任务中。

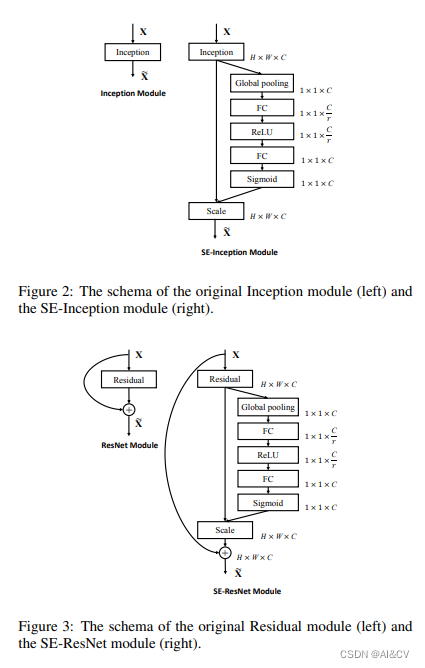
3.1 加入 common.py中
###################### SENet #### start by AI&CV ###############################
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
def __init__(self, channel=512,reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
###################### SENet #### end by AI&CV ###############################
3.2 加入yolo.py中:
def parse_model(d, ch, verbose=True): 加入以下代码
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF,DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, CNeB, nn.ConvTranspose2d, DWConvTranspose2d, C3x, C2f,CARAFE,
conv_bn_relu_maxpool, DWConvblock, Shuffle_Block,
EMA_attention,GlobalContext,GatherExcite, CoordAtt, EffectiveSE)3.3 yolov5s_SEAttention.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, SEAttention, [1024]], # 24
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
4. EffectiveSE

论文: https://arxiv.org/pdf/1911.06667.pdf
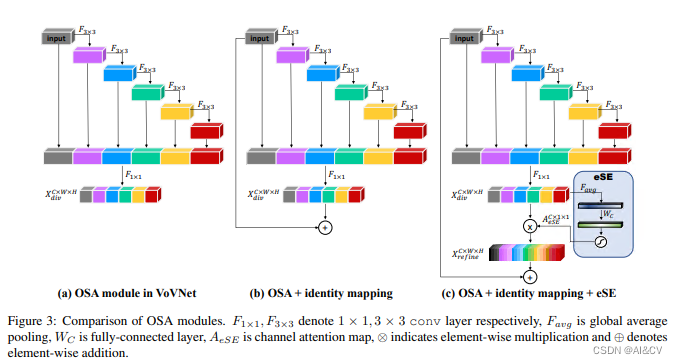
EffectiveSE是一种用于图像分类的卷积神经网络结构,它是SENet(Squeeze-and-Excitation Networks)的改进版本。EffectiveSE借鉴了SENet的思想,通过学习一种“通道注意力”,来自适应地调整每个通道的权重,以提高网络的性能。
EffectiveSE的网络结构包含了多个模块,其中最核心的是所谓的“通道注意力模块”,它由两个部分组成:Squeeze和Excitation。Squeeze部分是一个全局平均池化层,用于将每个通道的特征图压缩为一个标量。Excitation部分是一个多层感知机(MLP),用于学习每个通道的权重,并将其乘以原始特征图,以产生加权的特征图。
EffectiveSE在SENet的基础上进行了改进,将SE模块应用于ResNet和ResNeXt等经典网络结构中,并使用了一种新的损失函数来训练网络。实验证明,EffectiveSE相比于SENet和其他经典网络结构,具有更高的分类精度和更快的收敛速度
ESE(Effective Squeeze and Extraction) layer是模型中的一个block,基于SE(Squeeze and Extraction)而来。与SE的区别在于,ESE block只有一个fc层,《CenterMask : Real-Time Anchor-Free Instance Segmentation》的作者注意到SE模块有一个缺点:由于维度的减少导致的通道信息损失。为了避免这种大模型的计算负担,se的2个fc层需要减少通道维度。特别的,当第一个fc层使用r减少输入特征通道,将通道数从c变为c/r的时候,第二个fc层又需要扩张减少的通道数到原始的通道c.在这个过程中,通道维度的减少导致了通道信息的损失。因而,effective SE仅仅使用一个通道数为c的fc层代替了两个fc层,避免了通道信息DE丢失;
4.1 加入 common.py中
###################### EffectiveSE #### end by AI&CV ###############################
import torch
from torch import nn as nn
from timm.models.layers.create_act import create_act_layer
class EffectiveSE(nn.Module):
def __init__(self, channels, add_maxpool=False, gate_layer='hard_sigmoid'):
super(EffectiveSE, self).__init__()
self.add_maxpool = add_maxpool
self.fc = nn.Conv2d(channels, channels, kernel_size=1, padding=0)
self.gate = create_act_layer(gate_layer)
def forward(self, x):
x_se = x.mean((2, 3), keepdim=True)
if self.add_maxpool:
# experimental codepath, may remove or change
x_se = 0.5 * x_se + 0.5 * x.amax((2, 3), keepdim=True)
x_se = self.fc(x_se)
return x * self.gate(x_se)
###################### EffectiveSE #### end by AI&CV ############################### 4.2 加入yolo.py中:
def parse_model(d, ch): 加入以下代码
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF,DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, CNeB, nn.ConvTranspose2d, DWConvTranspose2d, C3x, C2f,CARAFE,
conv_bn_relu_maxpool, DWConvblock, Shuffle_Block,
EMA_attention,GlobalContext,GatherExcite, CoordAtt, SEAttention, EffectiveSE) #attention4.3 yolov5s_EffectiveSE.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, EffectiveSE, [1024]], # 24
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
5.总结
本文介绍了四种注意力机制,分别是:ShuffleAttention、ECA、EffectiveSE、SE,并最终引入到Yolov5。同时在数据集下测试,均能涨点,涨点幅度为ShuffleAttention>ECA>EffectiveSE>SE


















 4975
4975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











