







YOLOv12的主要贡献点如下:
1. 构建以注意力机制为核心的框架
YOLOv12提出了以注意力为中心的实时目标检测框架,通过方法论创新和架构改进,打破了传统CNN在YOLO系列中的主导地位。
2. 引入区域注意力模块(Area Attention)
YOLOv12设计了区域注意力模块(A2),将特征图划分为简单的垂直或水平区域,减少了注意力机制的计算复杂度,同时保持了较大的感受野。该模块将注意力机制的计算成本从2n2hd降低到21n2hd,显著提升了检测精度和推理速度。
3. 提出残差高效层聚合网络(R-ELAN)
为解决传统ELAN模块在大规模模型中的优化不稳定性问题,YOLOv12引入了R-ELAN。它通过块级残差设计和特征聚合方法,增强了特征提取能力,降低了计算成本,同时提高了训练稳定性。
4. 架构优化
-
引入FlashAttention技术,优化了注意力机制的内存访问效率,减少了内存读写延迟。
-
调整多层感知机(MLP)比例,从4降至1.2,平衡了注意力机制和前馈网络的计算量。
-
移除位置编码,引入7×7大卷积核作为位置感知模块,提升了模型的效率和性能。
5. 性能提升
YOLOv12在不依赖预训练等额外技术的情况下,实现了更快的推理速度和更高的检测精度。例如,YOLOv12-N在保持更快推理速度的同时,比YOLOv10-N提升了2.1%的mAP,比YOLOv11-N提升了1.2%的mAP。
6. 推动注意力机制在实时检测中的应用
YOLOv12通过技术创新,成功将注意力机制应用于实时目标检测系统中,挑战了基于CNN的设计在YOLO系统中的主导地位,为未来的实时检测系统开辟了新的方向。
目录
博主简介
AI小怪兽,YOLO骨灰级玩家,1)YOLOv5、v7、v8、v9、v10、11优化创新,轻松涨点和模型轻量化;2)目标检测、语义分割、OCR、分类等技术孵化,赋能智能制造,工业项目落地经验丰富;

原创自研系列, 2024、25年计算机视觉顶会创新点
应用系列篇:
23、24年最火系列,加入24年改进点内涵100+优化改进篇,涨点小能手,助力科研,好评率极高
1.YOLOv12介绍

论文:[2502.12524] YOLOv12: Attention-Centric Real-Time Object Detectors
摘要:
长期以来,提升YOLO框架的网络架构至关重要,但相关改进主要聚焦于基于CNN的优化,尽管注意力机制已被证实具备更卓越的建模能力。这种现状源于注意力模型在速度上始终无法与CNN模型相媲美。本研究提出了一种以注意力机制为核心的YOLO框架——YOLOv12,在保持与先前CNN模型相当速度的同时,充分释放了注意力机制的性能优势。
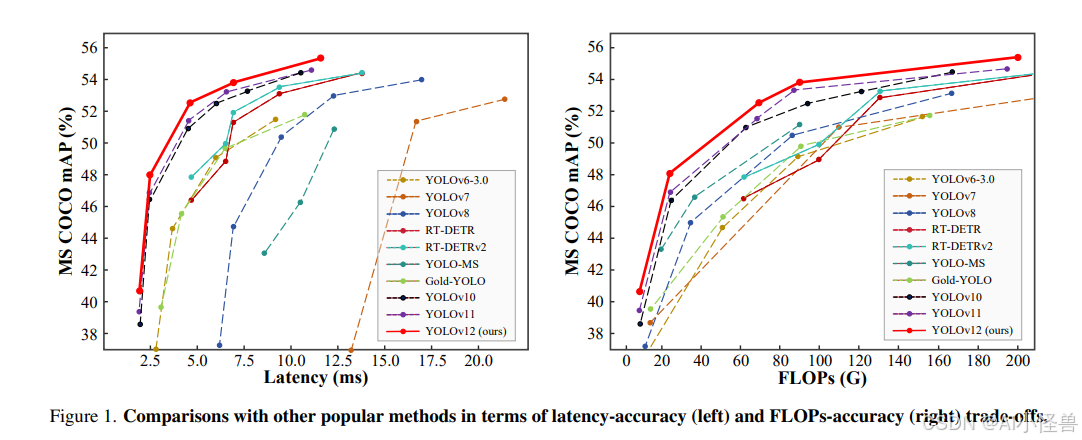
YOLOv12在保持具有竞争力的推理速度下,其准确率超越了所有主流实时目标检测器。具体而言,YOLOv12-N在T4 GPU上以1.64ms的推理延迟实现了40.6%的mAP,相较先进的YOLOv10-N/YOLOv11-N分别提升2.1%/1.2%的mAP,同时保持相近速度。该优势在其他模型规模上同样显著。相较于改进DETR的端到端实时检测器,YOLOv12也展现出优越性:例如YOLOv12-S以42%的速度优势超越RT-DETR-R18/RT-DETRv2-R18,仅需36%的计算量和45%的参数量。更多对比详见图1。
本文旨在解决这些挑战,并进一步构建了一个以注意力为中心的YOLO框架,即YOLOv12。我们引入了三项关键改进。首先,我们提出了一个简单高效的区域注意力模块(A²),它以一种非常简单的方式在保持较大感受野的同时减少了注意力的计算复杂度,从而提高了速度。其次,我们引入了残差高效层聚合网络(R-ELAN),以应对注意力机制(尤其是大规模模型)引入的优化挑战。R-ELAN在原始ELAN的基础上引入了两项改进:(i)基于块的残差设计与缩放技术;(ii)重新设计的特征聚合方法。第三,我们在传统注意力机制的基础上进行了一些架构改进,以适应YOLO系统。我们升级了传统的注意力中心架构,包括:引入FlashAttention以解决注意力的内存访问问题,移除位置编码等设计以使模型更快速、更简洁,将MLP比率从4调整为1.2以平衡注意力机制和前馈网络之间的计算量,从而获得更好的性能,减少堆叠块的深度以促进优化,以及尽可能多地利用卷积操作来发挥其计算效率。
总之,YOLOv12的贡献可以概括为以下两点:1)它建立了一个以注意力为中心的、简单而高效的YOLO框架,通过方法创新和架构改进,打破了CNN模型在YOLO系列中的主导地位。2)YOLOv12在不依赖预训练等额外技术的情况下,实现了快速推理速度和更高的检测精度的最新成果,展现了其潜力。
1.1 区域注意力模块
一种简单的降低传统注意力计算成本的方法是使用线性注意力机制,它将传统注意力的复杂度从二次降低到线性。对于一个具有维度(n, h, d)的视觉特征f,其中n是标记的数量,h是头的数量,d是头的大小,线性注意力将复杂度从2n²hd降低到2nhd²,由于n > d,从而降低了计算成本。然而,线性注意力存在全局依赖性退化、不稳定性和对分布的敏感性等问题。此外,由于低秩瓶颈,当应用于输入分辨率为640×640的YOLO时,它只能提供有限的速度优势。
另一种有效降低复杂度的方法是局部注意力机制(例如,Shift Window、交叉注意力和轴向注意力),如图2所示。这些方法将全局注意力转换为局部注意力,从而降低了计算成本。然而,将特征图划分为窗口可能会引入额外开销或缩小感受野,从而影响速度和精度。
在本研究中,我们提出了一种简单而高效的区域注意力模块(Area Attention Module)。如图2所示,将分辨率为(H, W)的特征图划分为大小为(H/l, W)或(H, W/l)的l个段。这种方法消除了显式的窗口划分,仅需要一个简单的重塑操作,从而实现了更快的速度。我们通过实验将l的默认值设置为4,将感受野缩小到原来的1/4,但仍然保持了较大的感受野。通过这种方法,注意力机制的计算成本从2n²hd降低到1/2 n²hd。我们证明,尽管复杂度为n²,但当n固定为640时(输入分辨率增加时n会增大),这种设计仍然足够高效,能够满足YOLO系统的实时性要求。有趣的是,我们发现这种改进对性能的影响微乎其微,但却显著提高了速度。

1.2 残差高效层聚合网络
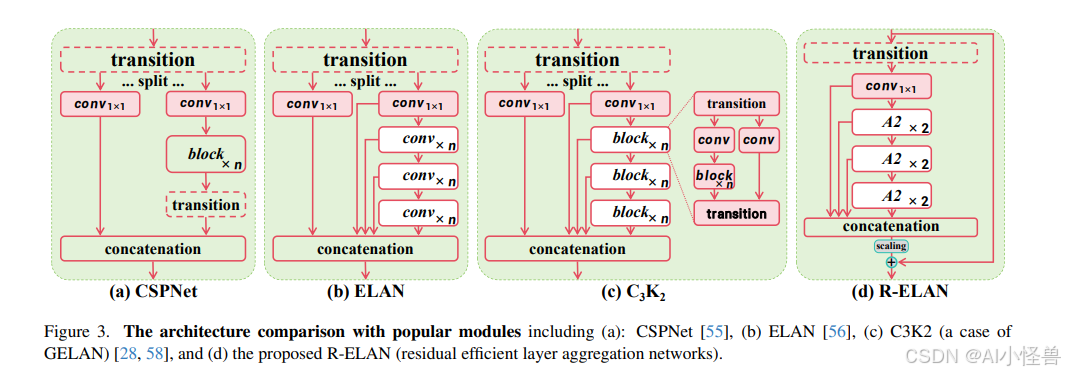
高效层聚合网络(Efficient Layer Aggregation Networks,简称ELAN)旨在改善特征聚合。如图3(b)所示,ELAN将转换层(一个1×1卷积)的输出拆分,将其中一个分支通过多个模块进行处理,然后将所有输出进行拼接,并应用另一个转换层(1×1卷积)以对齐维度。然而,正如文献[57]所分析的,这种架构可能会引入不稳定性。我们认为,这种设计会导致梯度阻塞,并且缺乏从输入到输出的残差连接。此外,我们围绕注意力机制构建了网络,这带来了额外的优化挑战。在实验中,L级和X级模型要么无法收敛,要么保持不稳定,即使使用Adam或AdamW优化器也是如此。
为了解决这一问题,我们提出了残差高效层聚合网络(Residual Efficient Layer Aggregation Networks,简称R-ELAN),如图3(d)所示。与之相对,我们在整个模块中引入了一个从输入到输出的残差捷径,并引入了一个缩放因子(默认值为0.01)。这种设计类似于层缩放(layer scaling),它被引入用于构建深度视觉变换器。然而,将层缩放应用于每个区域注意力机制并不能克服优化挑战,反而会引入延迟的增加。这表明,注意力机制的引入并不是收敛的唯一原因,而是ELAN架构本身,这也验证了我们提出R-ELAN设计的合理性。
我们还设计了一种新的聚合方法,如图3(d)所示。原始的ELAN层通过先将输入传递给一个转换层,然后将其拆分为两部分来处理模块的输入。其中一部分会进一步通过后续模块进行处理,最终将这两部分拼接在一起以产生输出。相比之下,我们的设计应用了一个转换层来调整通道维度,并生成一个单一的特征图。这个特征图随后通过后续模块进行处理,最后进行拼接,形成了一个瓶颈结构。这种方法不仅保留了原始的特征融合能力,还减少了计算成本以及参数/内存的使用。
1.3 架构改进
在本节中,我们将介绍YOLOv12的整体架构以及对传统注意力机制的一些改进。其中部分改进并非我们首次提出。
许多以注意力为中心的视觉变换器采用了平面式架构,而我们保留了之前YOLO系统的分层设计,并证明了其必要性。我们移除了主干网络最后阶段堆叠的三个块,这一设计出现在近期版本中。相反,我们仅保留了一个R-ELAN块,减少了总块数,从而有助于优化。我们从YOLOv11中继承了主干网络的前两个阶段,并且没有使用提出的R-ELAN。
此外,我们对传统注意力机制中的若干默认配置进行了修改,以更好地适配YOLO系统。这些修改包括:将MLP比率从4调整为1.2(或对于N-、S-、M级模型为2),以更好地分配计算资源,从而提升性能;采用nn.Conv2d+BN代替nn.Linear+LN,以充分利用卷积操作的效率;移除位置编码;引入一个大尺寸可分离卷积(7×7,即位置感知器),以帮助区域注意力感知位置信息。这些改进的有效性将在第4.5节中验证。
1.4 实验结果
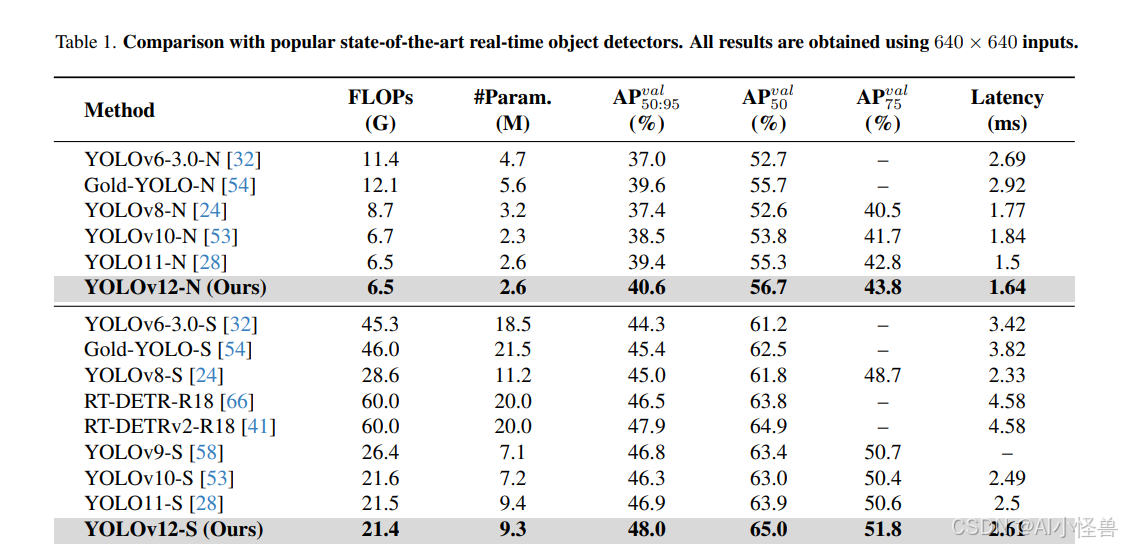
我们在表1中展示了YOLOv12与其他流行的实时检测器之间的性能比较。
对于N级模型,YOLOv12-N在平均精度(mAP)上分别比YOLOv6-3.0-N、YOLOv8-N、YOLOv10-N和YOLOv11高出3.6%、3.3%、2.1%和1.2%,同时保持了相似甚至更少的计算量和参数量,并实现了每张图像1.64毫秒的快速延迟速度。
对于S级模型,YOLOv12-S在计算量为21.4G FLOPs、参数量为9.3M的情况下,实现了48.0%的mAP,每张图像的延迟为2.61毫秒。它在性能上分别超越了YOLOv8-S、YOLOv9-S、YOLOv10-S和YOLOv11-S,分别提升了3.0%、1.2%、1.7%和1.1%,同时保持了相似或更少的计算量。与端到端检测器RT-DETR-R18和RT-DETRv2-R18相比,YOLOv12-S在性能上具有可比性,但推理速度更快,计算成本更低,参数量更少。
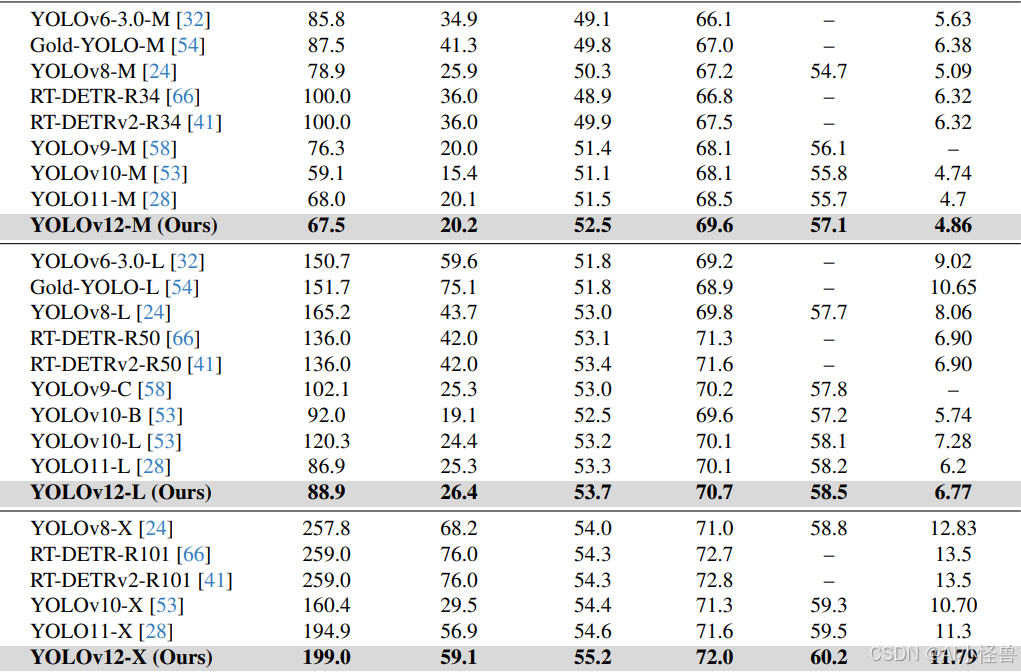
对于M级模型,YOLOv12-M在计算量为67.5G FLOPs、参数量为20.2M的情况下,实现了52.5%的mAP性能和4.86毫秒/图像的推理速度。与GoldYOLO-M、YOLOv8-M、YOLOv9-M、YOLOv10、YOLOv11以及RT-DETR-R34/RT-DETRv2-R34相比,YOLOv12-M具有显著优势。
对于L级模型,YOLOv12-L在减少31.4G FLOPs的情况下,仍然超越了YOLOv10-L。YOLOv12-L在FLOPs和参数量相当的情况下,以0.4%的mAP优势击败了YOLOv11。此外,YOLOv12-L在速度更快的情况下,FLOPs减少了34.6%,参数量减少了37.1%,优于RT-DERT-R50/RT-DERTv2-R50。
对于X级模型,YOLOv12-X在性能上分别比YOLOv10-X和YOLOv11-X高出0.8%和0.6%,同时保持了相当的推理速度、计算量和参数量。YOLOv12-X再次以更快的速度、更少的FLOPs(减少23.4%)和更少的参数(减少22.2%)超越了RT-DETR-R101/RT-DETRv2-R101。
特别地,如果使用FP32精度对L级和X级模型进行评估(需要单独保存为FP32格式),YOLOv12将实现约0.2%的mAP提升。这意味着YOLOv12-L/X将分别报告33.9%和55.4%的mAP。
1.4.1 消融研究
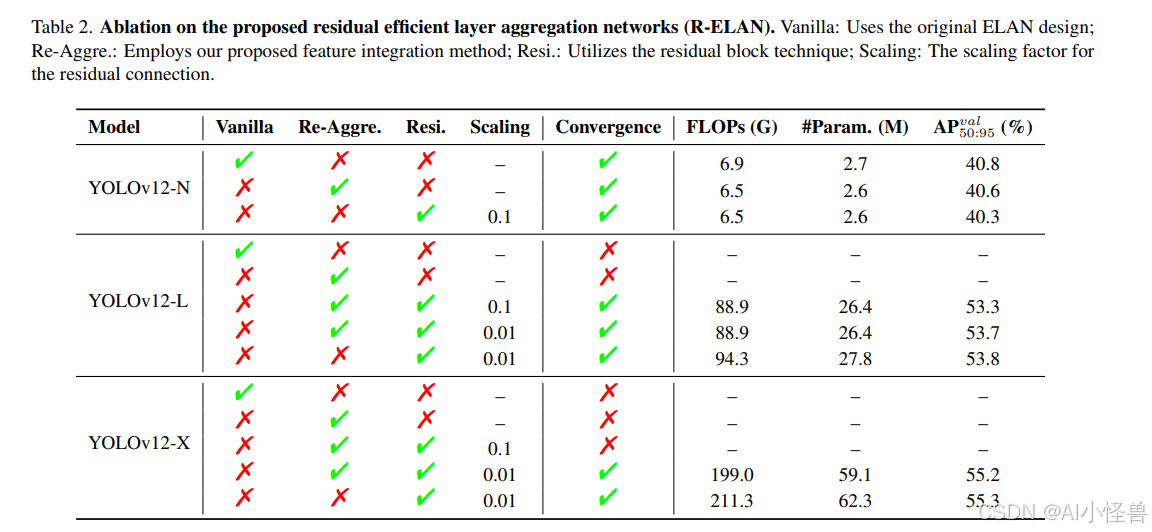
• R-ELAN。表2通过YOLOv12-N/L/X模型评估了所提出的残差高效层聚合网络(R-ELAN)的有效性。结果揭示了两个关键发现:(i)对于小型模型(如YOLOv12-N),残差连接对收敛没有影响,但会降低性能。相比之下,对于大型模型(YOLOv12-L/X),残差连接对稳定训练至关重要。特别是,YOLOv12-X需要一个最小的缩放因子(0.01)来确保收敛。(ii)所提出的特征融合方法在保持相当性能的同时,有效地降低了模型的复杂性,仅略微减少了FLOPs和参数量。
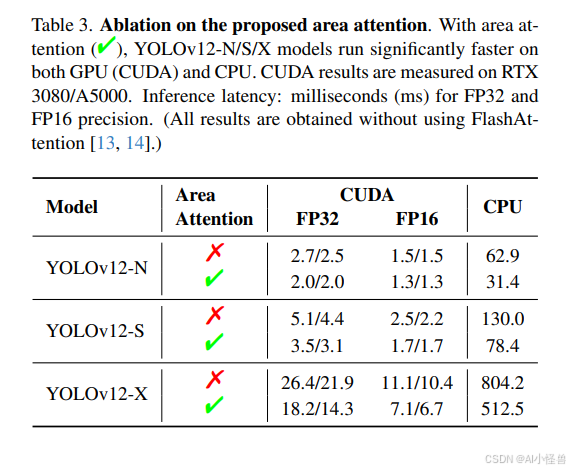
• 区域注意力(Area Attention)。我们进行了消融实验以验证区域注意力的有效性,结果如表3所示。实验在YOLOv12-N/S/X模型上进行,分别测量了在GPU(CUDA)和CPU上的推理速度。CUDA结果使用RTX 3080和A5000显卡测试,而CPU性能则在Intel Core i7-10700K @ 3.80GHz上测量。实验结果表明,区域注意力显著提升了推理速度。例如,在RTX 3080上使用FP32精度时,YOLOv12-N的推理时间减少了0.7毫秒。这种性能提升在不同模型和硬件配置下均得到了一致的体现。需要注意的是,本次实验中未使用FlashAttention,因为其会显著缩小速度差异。
1.4.2 速度对比
表4展示了在不同GPU上对推理速度的比较分析,评估了YOLOv9、YOLOv10、YOLOv11和我们的YOLOv12在RTX 3080、RTX A5000和RTX A6000上使用FP32和FP16精度时的性能。为了确保结果的一致性,所有测试均在同一硬件上进行,且YOLOv9和YOLOv10的评估使用了ultralytics的集成代码库。结果显示,YOLOv12在推理速度上显著高于YOLOv9,同时与YOLOv10和YOLOv11相当。例如,在RTX 3080上,YOLOv9报告的推理时间为2.4毫秒(FP32)和1.5毫秒(FP16),而YOLOv12-N的推理时间分别为1.7毫秒(FP32)和1.1毫秒(FP16)。其他配置下也呈现出类似的趋势。
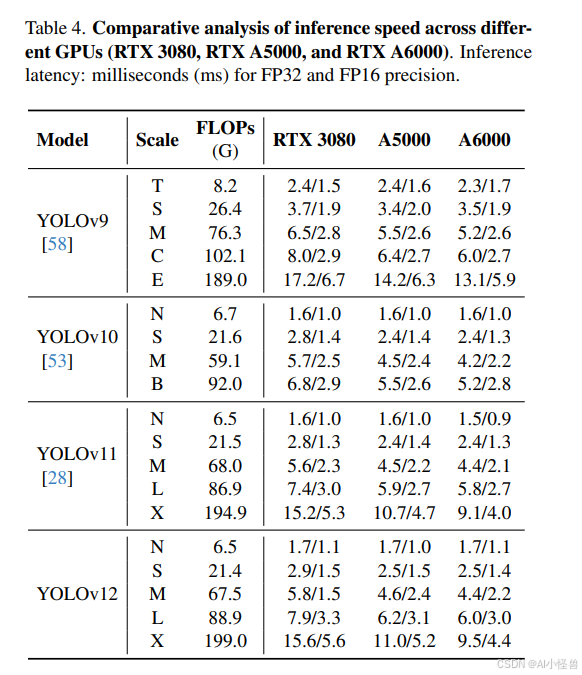
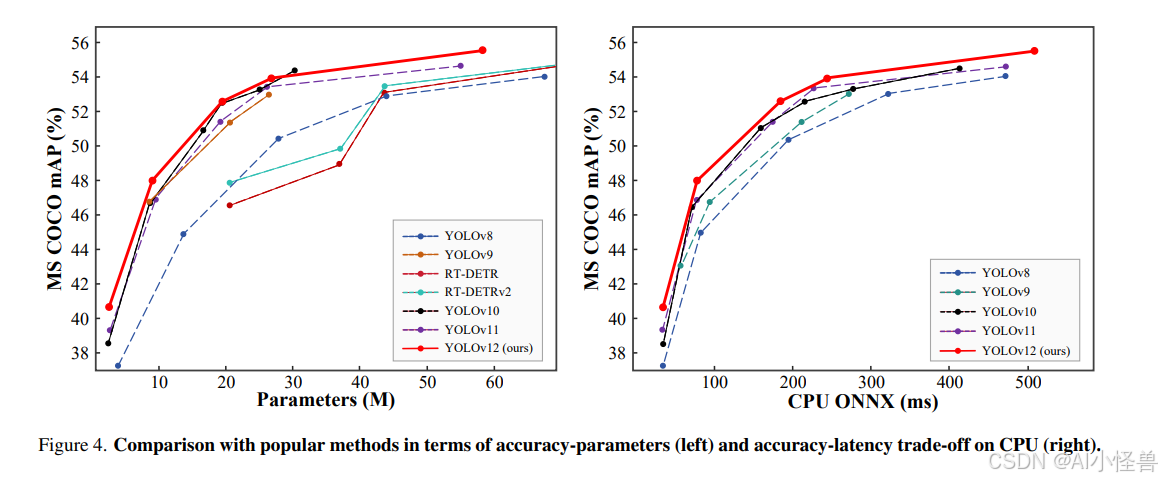
图4提供了更多的对比分析。左侧子图展示了YOLOv12与其他流行方法在精度与参数量之间的权衡对比。YOLOv12建立了一个超越其他同类方法的主导边界,甚至超过了YOLOv10——一个以显著更少参数为特征的YOLO版本,这充分展示了YOLOv12的高效性。
在右侧子图中,我们比较了YOLOv12与之前YOLO版本在CPU上的推理延迟(所有结果均在Intel Core i7-10700K @ 3.80GHz上测量)。如图所示,YOLOv12在不同硬件平台上展现出更具优势的边界,超越了其他竞争对手,突显了其在多样化硬件平台上的高效性。
1.4.3 诊断与可视化
我们在表5a至表5h中对YOLOv12的设计进行了诊断。除非另有说明,这些诊断均在YOLOv12-N上进行,默认从头开始训练600个周期。

1.5 结论
本研究介绍了YOLOv12,它成功地将传统上被认为不适用于实时需求的以注意力为中心的设计引入到YOLO框架中,实现了在延迟与准确性之间的最先进权衡。为了实现高效推理,我们提出了一种新颖的网络,该网络利用区域注意力来降低计算复杂度,并通过残差高效层聚合网络(R-ELAN)来增强特征聚合。此外,我们对传统注意力机制的关键组件进行了优化,以更好地适应YOLO的实时性要求,同时保持高速性能。
因此,YOLOv12通过有效结合区域注意力、R-ELAN和架构优化,实现了最先进的性能,显著提升了准确性和效率。全面的消融研究进一步验证了这些创新的有效性。本研究挑战了基于CNN的设计在YOLO系统中的主导地位,并推动了注意力机制在实时目标检测中的集成,为更高效、更强大的YOLO系统铺平了道路。
1.6 不足(限制)
YOLOv12需要使用FlashAttention,而FlashAttention目前仅支持以下NVIDIA GPU架构:Turing、Ampere、Ada Lovelace和Hopper。具体支持的GPU型号包括但不限于:T4、Quadro RTX系列、RTX 20系列、RTX 30系列、RTX 40系列、RTX A5000/A6000、A30/A40、A100、H100。
1.7 环境配置难点
YOLOv12需要使用FlashAttention,而windows编译(flash_attn)此环境存在着一点的难点,本博客后续会讲述如何在windows编译此环节,请后续关注!!!


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











