







YOLOv12是YOLO(You Only Look Once)系列的一种新版本,专注于目标检测任务。与其他版本的YOLO相比,YOLOv12可能会有一些特别的优化和新特性,但具体的改进需要通过最新的论文或官方发布来确认。假设你指的是基于YOLOv12进行的姿态识别(例如摔倒、站立等动作)的关键点数据集训练,这个过程涉及使用YOLOv12模型识别和定位人体关键点,以便于分析人体姿态。
下面是一份关于“摔倒、站立等姿态识别”任务中,如何利用YOLOv12训练关键点数据

一、目标检测与姿态识别概述
在计算机视觉领域,姿态识别是指通过分析图像或视频中的人体姿势,判断人体的运动状态或行为。摔倒、站立等动作的识别对于许多应用具有重要意义,尤其在安防、健康监测和智能家居等领域。例如,摔倒检测可以帮助老年人群体在发生意外时及时求助,站立姿态识别可以用于监控等场景。
为了实现这些目标,计算机视觉中的目标检测技术发挥了重要作用,YOLO系列模型尤其突出。YOLOv12则是YOLO模型家族中的一员,借助于高效的检测能力和快速的推理时间,能够在不同环境下对图像中的目标进行精准的定位和分类。
二、YOLOv12架构概述

YOLOv12基于卷积神经网络(CNN),结合了多种优化技术,在检测精度和速度上取得了平衡。YOLO系列的特点是将图像分为网格,每个网格负责预测物体的边界框以及相应的类别。YOLOv12的优化可能包括更高效的特征提取、更好的尺度适应性以及对不同任务(如姿态识别)的适应性。
YOLOv12在处理人体关键点识别任务时,会通过人体部位的关键点标注来定位不同的关节或部位。这一任务通常涉及通过特定的关键点数据集进行训练。具体来说,YOLOv12将图像中的人体划分为不同的区域,识别出各个关节的位置,并根据这些位置判断人体的姿态。
三、关键点数据集
要训练YOLOv12进行姿态识别,首先需要合适的数据集。常见的人体关键点数据集包括COCO(Common Objects in Context)、MPII(Max Planck Institute for Informatics)、LSP(Leeds Sports Pose)等。这些数据集标注了人体的关键点,如头部、肩膀、肘部、手腕、膝盖等。
对于摔倒、站立等特定动作的识别,可能需要专门的数据集。这些数据集可能会标注不同姿势下的关键点,帮助模型学习在这些姿势下关节和骨骼的相对位置。

四、YOLOv12的关键点检测与姿态识别
YOLOv12训练人体关键点数据集的过程可以分为以下几个步骤:
-
数据预处理与增强:在开始训练之前,需要对关键点数据集进行预处理。这可能包括图像的缩放、旋转、裁剪、翻转等数据增强技术。数据增强有助于提高模型的泛化能力,使得模型在不同角度、光照和背景下都能准确识别关键点。
-
模型训练:训练过程中,YOLOv12会通过反向传播算法不断调整网络中的参数,使其能够准确预测人体的关键点位置。YOLOv12的损失函数可能会包括定位损失和关键点回归损失两部分,确保模型不仅能准确地预测物体边界框,还能在框内定位到正确的关节位置。
-
多任务学习:除了检测姿势的关键点,YOLOv12可能还需要同时完成其他任务,如姿态分类(摔倒、站立、坐下等)。为此,模型可能采用多任务学习的策略,即在同一网络中同时进行多项任务的学习。这样的多任务训练不仅提高了姿态识别的精度,还能增强模型对多种姿势的适应能力。
-
评估与优化:训练完成后,使用验证集对模型进行评估,计算关键点的预测精度。常用的评估指标包括平均精度(AP)、关键点准确度(PCK)等。如果精度不够高,可以进一步调整网络架构,增加数据集的多样性,或者采用更高级的优化方法,如学习率衰减、正则化等。
def parse_opt():
"""Parse command line arguments."""
parser = argparse.ArgumentParser()
parser.add_argument('--source', type=str, required=True, help='video file path')
return parser.parse_args()
def main(opt):
"""Main function."""
run(**vars(opt))
if __name__ == '__main__':
opt = parse_opt()
main(opt)
五、应用场景与挑战
YOLOv12进行姿态识别,尤其是摔倒与站立识别,可以应用于以下几个场景:
- 老年人健康监测:通过摄像头实时监控老年人的行为,在发生摔倒时能够迅速发出警报,提供及时帮助。
- 安防监控:在公共场所或家庭中,通过监控视频判断人员是否有异常行为,如摔倒或长时间保持某一姿势。
- 智能家居:智能家居系统可以根据人的站立、坐下或摔倒姿势做出响应,例如自动开关灯或调节温度。
然而,YOLOv12在姿态识别任务中仍面临一些挑战:

- 复杂背景和遮挡:在复杂背景或多人场景下,可能存在姿势被遮挡或难以识别的情况。
- 姿态变换:摔倒、站立等动作的关键点位置变化较大,模型需要能有效适应这些动态变化。
- 数据集的多样性:为提高准确度,需要涵盖多种姿态、不同环境条件和多样化的关键点标注。
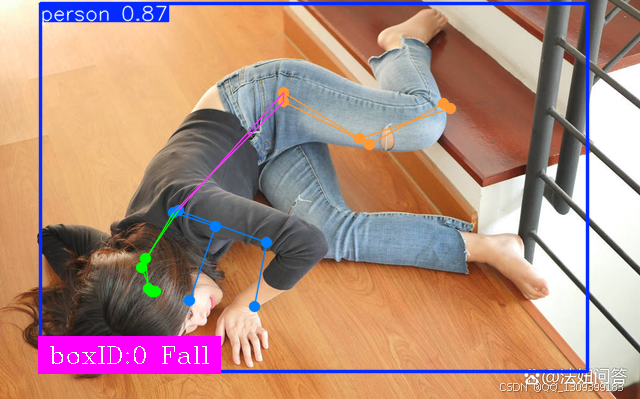
六、总结
YOLOv12作为一个高效的目标检测框架,在姿态识别任务中具有很大的潜力。通过使用标注有关键点的训练数据集,YOLOv12能够有效地识别并分类不同的姿态,如摔倒和站立。这对于老年人监护、安防监控等领域有着广泛的应用前景。然而,面对背景复杂、姿态多变等挑战,仍然需要进一步优化和创新,以提高模型的准确性和鲁棒性。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









