






摘要:我们推出了PaSa,这是一款由大型语言模型驱动的高级论文搜索代理。PaSa能够自主做出一系列决策,包括调用搜索工具、阅读论文以及选择相关参考文献,从而最终为复杂的学术查询提供全面且准确的结果。我们使用强化学习方法和一个合成数据集AutoScholarQuery对PaSa进行了优化,该数据集包含3.5万个细粒度的学术查询以及来自顶级人工智能会议出版物的相应论文。此外,我们还开发了RealScholarQuery基准,这是一个收集真实世界学术查询的基准,用于评估PaSa在更现实场景中的性能。尽管PaSa是在合成数据上训练的,但在RealScholarQuery上,其表现显著优于现有的基线方法,包括Google、Google Scholar、使用GPT-4进行查询转述的Google、chatGPT(启用搜索功能的GPT-4o)、GPT-o1以及PaSa-GPT-4o(通过提示GPT-4o实现的PaSa)。值得注意的是,PaSa-7B在recall@20指标上比最佳的基于Google的基线方法(即使用GPT-4o的Google)高出37.78%,在recall@50指标上高出39.90%。同时,它在召回率上比PaSa-GPT-4o高出30.36%,在准确率上高出4.25%。模型、数据集和代码可在https://github.com/bytedance/pasa上获取。Huggingface链接:Paper page , 论文链接:2501.10120
1. 引言
1.1 学术论文搜索的挑战
学术论文搜索是科研工作的核心,但它也是一项极具挑战性的信息检索任务。这要求系统具备长尾专业知识、全面的综述性覆盖能力以及处理细粒度查询的能力。例如,对于查询“哪些研究专注于使用基于价值的非平稳强化学习方法,特别是基于UCB的算法?”,尽管像Google Scholar这样的广泛使用的学术搜索系统对于一般查询是有效的,但在处理这些复杂查询时往往表现不佳。因此,研究人员经常需要花费大量时间进行文献综述。
1.2 大型语言模型(LLM)的兴起
随着大型语言模型(LLM)的不断发展,越来越多的研究开始利用LLM来增强信息检索,特别是通过优化或重构搜索查询来提高检索质量。然而,在学术搜索中,过程远不止于简单的检索。人类研究人员不仅使用搜索工具,还深入阅读相关论文并检查引用,以进行全面准确的文献综述。
2. PaSa系统概述
2.1 PaSa的定义与功能
我们推出了PaSa,这是一款由大型语言模型驱动的高级论文搜索代理。PaSa能够自主做出一系列决策,包括调用搜索工具、阅读论文以及选择相关参考文献,从而最终为复杂的学术查询提供全面且准确的结果。
2.2 PaSa的系统架构
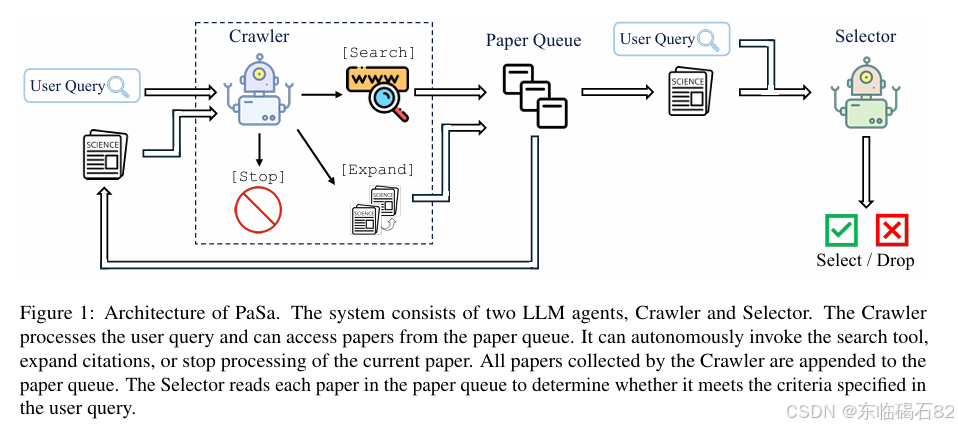
PaSa系统由两个LLM代理组成:Crawler和Selector。对于给定的用户查询,Crawler可以自主地收集相关论文,方法包括利用搜索工具或从当前论文中提取引用,然后将这些论文添加到不断增长的论文队列中。Crawler迭代地处理论文队列中的每篇论文,通过导航引用网络来发现更多相关论文。Selector则仔细阅读论文队列中的每篇论文,以确定其是否满足用户查询的要求。
3. 数据集开发
3.1 AutoScholarQuery数据集
为了有效训练PaSa,我们构建了一个合成但高质量的学术搜索数据集AutoScholarQuery。该数据集从ICLR 2023、ICML 2023、NeurIPS 2023、ACL 2024和CVPR 2024等顶级AI会议出版物中收集了细粒度的学术查询及其对应的相关论文。AutoScholarQuery包含33,511个训练样本、1,000个开发样本和1,000个测试样本。尽管AutoScholarQuery只提供了查询和论文答案,没有展示科学家收集论文的路径,但我们仍可以利用它来进行RL训练以改进PaSa。
3.2 RealScholarQuery基准
为了评估PaSa在更现实场景中的性能,我们还开发了RealScholarQuery基准。该基准包含了50个真实世界的学术查询及其标注的相关论文。这些查询是由AI研究人员在使用PaSa系统后提供的,我们从中随机采样并手动过滤掉过于宽泛的主题,最终收集了50个细粒度和现实的查询。对于每个查询,我们首先手动收集相关论文,然后使用多种方法(包括PaSa、Google、Google Scholar、ChatGPT和GPT-4o转述的Google查询)检索更多论文。最后,专业注释者审查了每个查询的所有候选论文,选择了满足查询特定要求的论文作为最终的相关论文集。
4. 方法论
4.1 Crawler代理
Crawler代理在RL术语中执行一个基于令牌的马尔可夫决策过程(MDP)。其动作空间A对应于LLM的词汇表,其中每个令牌代表一个动作。LLM作为策略模型,代理的状态由当前的LLM上下文和论文队列定义。Crawler代理具有三个注册功能:[Search]、[Expand]和[Stop]。当生成的动作与某个函数名称匹配时,将执行相应的函数,进一步修改代理的状态。
4.1.1 奖励设计
在AutoScholarQuery训练集上对Crawler进行RL训练,其中每个实例包含一个查询q和对应的论文集P。从查询q开始,Crawler生成一个轨迹τ=(s1, a1, ..., sT, aT)。在每个时间步t,我们表示当前的论文队列为Qt。执行动作at后,Crawler将一组新论文(p1, p2, ..., pnt)添加到论文队列中。如果at=[Stop],则集合为空。
动作at在状态st下的奖励定义为:
r(st, at) = α × Σnti=1I(q, pi, t) - c(at)
其中,I(q, pi, t)=1如果pi匹配查询q且不在Qt中,否则为0。α是奖励系数,c(at)是动作at的成本。
为了缓解稀疏奖励问题,我们使用Selector作为Crawler的辅助奖励模型。修订后的指示函数I(q, pi, t)定义为:
I(q, pi, t) = 1, if (Selector(q, pi) = 1 or pi ∈ P) and pi ∉ Qt
0, otherwise
4.1.2 RL训练
训练Crawler的主要挑战之一是采样给定查询的完整轨迹所需的时间较长。为了解决这个问题,我们定义了一个会话作为从会话初始状态开始并以[Stop]动作结束的子轨迹。我们识别了两种会话初始状态:Sq(仅包含查询)和Sq+p(包含查询和论文)。
在PPO训练期间,我们估计会话中的返回值使用蒙特卡罗采样:
ˆRt = Σti+1−1−tk=0γk0r(st+k, at+k) + γ1Σnt+kj=1ˆVϕ(Sq+pj) - β · logπθ(at|st)πsft(at|st)
4.2 Selector代理
Selector代理是一个LLM代理,它接受两个输入:一个学术查询和一篇研究论文(包括标题和摘要)。它生成两个输出:(1)一个单一的决策令牌d,为"True"或"False",表示论文是否满足查询;(2)一个包含m个令牌的理由r=(r1, r2, ..., rm),用于支持该决策。理由有两个目的:通过联合训练模型以生成决策和解释来提高决策准确性,以及通过提供PaSa应用中的推理来提高用户信任。
5. 实验
5.1 实验设置
我们基于Qwen2.5-7b模型顺序训练了Selector和Crawler,以开发最终的代理PaSa-7b。Selector使用训练数据集进行了一轮监督微调,学习率为1e-5,批量大小为4,在8个NVIDIA-H100 GPU上运行。Crawler的训练过程包括两个阶段:首先进行一轮模仿学习,然后在第二阶段应用PPO训练。
5.2 基线与评估
我们在AutoScholarQuery测试集和RealScholarQuery上对PaSa进行了评估,并将其与以下基线进行了比较:Google、Google Scholar、使用GPT-4o进行查询转述的Google、chatGPT(启用搜索功能的GPT-4o)、GPT-o1以及PaSa-GPT-4o(通过提示GPT-4o实现的PaSa)。
5.2.1 主要结果
在AutoScholarQuery测试集上,PaSa-7b在所有基线中表现最佳。与最强的基线PaSa-GPT-4o相比,PaSa-7b在召回率上提高了9.64%,精度相当。与最佳的基于Google的基线(即使用GPT-4o的Google)相比,PaSa-7b在recall@20、recall@50和recall@100上分别提高了33.80%、38.83%和42.64%。
在RealScholarQuery上,PaSa-7b在更现实的学术搜索场景中表现出更大的优势。与PaSa-GPT-4o相比,PaSa-7b在召回率上提高了30.36%,在精度上提高了4.25%。与最佳的基于Google的基线相比,PaSa-7b在recall@20、recall@50和recall@100上分别提高了37.78%、39.90%和39.83%。
5.3 消融研究
我们通过消融研究评估了探索引用网络、RL训练以及使用Selector作为奖励模型的各自贡献。结果表明,移除Crawler的[Expand]动作会导致召回率显著下降,RL训练提高了召回率,移除Selector作为辅助奖励模型也会导致召回率下降。
6. 结论
我们介绍了PaSa,一款旨在为复杂学术查询提供全面准确结果的新型论文搜索代理。PaSa在AGILE强化学习框架内实现,并使用了我们开发的AutoScholarQuery和RealScholarQuery数据集进行优化和评估。实验结果表明,PaSa在所有基线中表现最佳,显著提高了学术搜索的效率和准确性。
7. 未来工作
尽管PaSa已经取得了显著的成果,但仍有许多改进空间。例如,我们可以探索更复杂的策略来提高PaSa的性能,或者将其扩展到其他领域的学术搜索。此外,我们还可以进一步研究如何使PaSa更好地与人类研究人员协作,以进一步提高文献综述的效率和质量。
通过不断优化和改进,PaSa有望成为科研工作中不可或缺的工具,帮助研究人员更快更准确地找到他们所需的相关论文和信息。

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









