






摘要:监督式微调(SFT)和强化学习(RL)是基础模型后训练中广泛使用的技术。然而,它们在增强模型泛化能力方面的作用尚不清楚。本文研究了SFT和RL在泛化与记忆方面的差异,重点关注基于文本的规则变体和视觉变体。我们引入了GeneralPoints,一种算术推理纸牌游戏,并采用V-IRL,一个真实世界的导航环境,来评估通过SFT和RL训练的模型如何在文本和视觉领域泛化到未见过的变体。我们发现,尤其是在基于结果的奖励下进行训练时,RL能够在基于规则的文本和视觉变体中都实现泛化。相比之下,SFT倾向于记忆训练数据,并且在泛化到分布外场景时表现不佳。进一步的分析揭示,RL提高了模型的底层视觉识别能力,从而增强了其在视觉领域的泛化能力。尽管RL在泛化方面表现更优,但我们发现SFT对于有效的RL训练仍然至关重要;SFT稳定了模型的输出格式,使后续的RL能够实现其性能提升。这些发现展示了RL在复杂、多模态任务中获取可泛化知识的能力。Huggingface链接:Paper page,论文链接:2501.17161
1. 引言
本文探讨了监督式微调(SFT)和强化学习(RL)在基础模型后训练中的作用,特别是它们对模型泛化能力的影响。随着OpenAI、Google等公司在基础模型领域的快速发展,SFT和RL作为后训练技术被广泛应用。然而,这两种技术在提升模型泛化能力方面的具体作用尚不清晰,这对于构建可靠且鲁棒的AI系统是一个关键挑战。
本文的研究聚焦于两个方面的泛化:基于文本的规则泛化和视觉泛化。对于文本规则,研究模型将学习到的规则(以文本指令形式给出)应用于规则变体的能力;对于视觉语言模型(VLMs),视觉泛化衡量模型在给定任务中面对视觉输入变化(如颜色和空间布局)时的性能一致性。
2. 相关工作
后训练技术:后训练对于提升模型性能至关重要,常用的方法包括大规模监督式微调(SFT)和强化学习(RL)。SFT通过任务特定的、通常是指令格式的数据集来适应预训练模型,使其适应下游任务。例如,FLAN展示了在多样化指令微调数据集上的微调显著增强了未见任务的零样本性能。另一方面,RL主要用于使模型与人类偏好对齐或训练基础模型解决特定任务。
记忆与泛化:在大型语言模型(LLMs)和视觉语言模型(VLMs)中,记忆与泛化的相互作用已有研究。LLMs可能记忆训练数据,而泛化则反映了模型输出分布与预训练数据分布之间的差异。先前研究表明,LLMs在简单、知识密集型任务上容易过拟合,而在复杂、推理密集型任务上表现出更好的泛化能力。
推理能力提升:一些研究展示了LLMs通过预计算推理图在自回归生成之前发展出超越训练数据的推理技能,这为泛化提供了有力证据。然而,这些研究主要关注LLMs,而本文则在不同模态(单模态和多模态)设置下,比较不同后训练范式对记忆与泛化的影响。
3. 基础概念
强化学习术语:本文采用经典RL文献中的标准符号,包括状态空间S、动作空间A、奖励函数r和每集最大步数T。目标是学习一个策略π,以最大化整体回报。
RL在LLM/VLM中的应用:本文采用多回合RL设置进行基础模型训练,定义了验证器VER来评估模型输出并生成基于结果的奖励函数。对于需要视觉输入的模型(VLM),状态空间S定义为文本和图像空间的笛卡尔积。
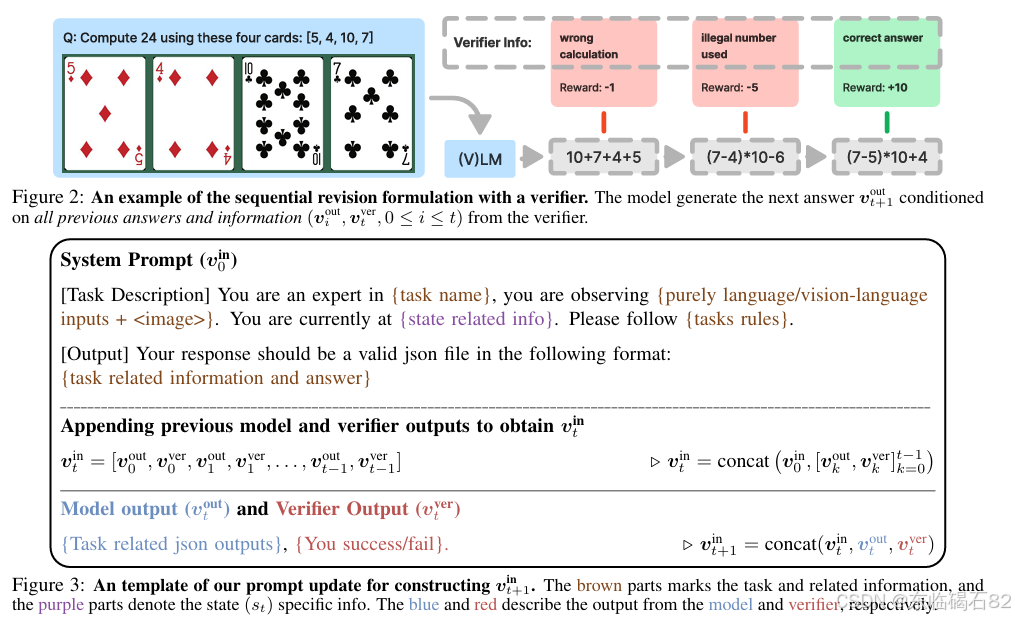
顺序修订:本文采用顺序修订公式来建模状态-动作转移,即在每个时间步,输入提示v_in^t由系统提示和所有先前的模型和验证器输出组成。
4. 评估任务
为了评估不同后训练方法的泛化能力,本文选择了两个任务:GeneralPoints和V-IRL。
GeneralPoints:这是一个新设计的环境,用于评估算术推理能力。每个状态包含四张牌,以文本或图像形式呈现。目标是生成一个等于目标数(默认为24)的等式,且每张牌只能使用一次。通过引入规则变体(如将'J'、'Q'、'K'解释为不同的数字)和视觉变体(如改变牌的颜色),研究模型在规则泛化和视觉泛化方面的能力。
V-IRL:这是一个真实世界的导航任务,用于评估模型的空间推理能力。任务包括纯语言描述版本(V-IRL-L)和包含视觉输入的版本(V-IRL-VL)。通过改变动作空间(如使用绝对方向或相对方向)和视觉观察(如在不同城市的路线中导航),研究模型在规则泛化和视觉泛化方面的能力。
5. 实验结果
规则泛化:实验结果显示,RL在所有任务(包括单模态和多模态任务)中均能在分布外(OOD)规则变体上实现性能提升,而SFT则表现出性能下降。例如,在GeneralPoints任务中,RL在未见过的规则变体上成功率提高了+3.5%,而SFT则下降了-8.1%。在V-IRL任务中,RL在未见过的规则变体上准确率提高了+11.0%,而SFT则下降了-79.5%。
视觉泛化:在视觉分布外任务中,RL同样表现出泛化能力,而SFT则表现不佳。例如,在GeneralPoints-VL任务中,RL在未见过的视觉变体上成功率提高了+17.6%,而SFT则下降了-9.9%。在V-IRL-VL任务中,RL在未见过的视觉变体上准确率提高了+61.1%,而SFT则下降了-5.6%。此外,本文的多回合RL方法还在V-IRL迷你基准测试上达到了最先进的性能,准确率提高了+33.8%。
视觉识别能力:进一步分析表明,RL提高了模型的底层视觉识别能力,从而增强了其在视觉领域的泛化能力。随着RL计算量的增加,模型的视觉识别准确率和整体性能均有所提高,而SFT则表现出相反的趋势。
SFT在RL训练中的作用:尽管RL在泛化方面表现更优,但本文发现SFT对于有效的RL训练仍然至关重要。在没有SFT初始化的情况下,直接应用RL会导致训练失败,因为基础模型无法正确跟随指令。SFT稳定了模型的输出格式,使后续的RL能够实现其性能提升。
验证迭代的作用:实验结果显示,增加验证迭代次数可以提高RL的泛化能力。在相同的计算预算下,随着验证迭代次数的增加,RL在分布外性能上的提升也更加显著。
6. 结论与讨论
本文通过大量实验展示了RL在获取可泛化知识方面的能力,尤其是在复杂、多模态任务中。相比之下,SFT倾向于记忆训练数据,并且在泛化到分布外场景时表现不佳。尽管如此,SFT对于有效的RL训练仍然至关重要,因为它稳定了模型的输出格式。
然而,本文也指出了研究中的一些挑战和局限性。例如,在特定任务(如GeneralPoints-VL)中,SFT未能达到与RL相当的分布内性能。此外,RL在极端欠拟合或过拟合的初始检查点上表现有限。未来的研究需要进一步探讨这些挑战,并改进后训练技术以提高模型的泛化能力。
7. 对实际应用的启示
本文的研究结果对实际应用具有重要启示。对于需要处理复杂、多模态任务的AI系统,采用RL作为后训练技术可能更为合适,因为它能够获取可泛化知识并在未见过的变体上实现良好性能。然而,为了确保RL训练的有效性,可能仍然需要首先应用SFT来稳定模型的输出格式。此外,通过增加验证迭代次数和采用基于结果的奖励函数等方法,可以进一步提高RL的泛化能力。
8. 未来研究方向
未来的研究可以进一步探讨以下几个方面:
- 优化SFT和RL的结合:研究如何更好地结合SFT和RL以充分发挥它们的优势,同时避免各自的局限性。
- 提高模型的泛化能力:探索新的后训练技术和方法,以提高模型在未见过的变体上的性能。
- 理解模型的记忆与泛化机制:深入研究模型在记忆和泛化方面的内部机制,以指导后训练技术的设计和优化。
- 跨模态泛化:研究模型在不同模态(如文本、图像、音频等)之间的泛化能力,以推动多模态AI系统的发展。
综上所述,本文通过对SFT和RL在基础模型后训练中的比较研究,为理解这两种技术在增强模型泛化能力方面的作用提供了重要见解,并为未来的研究指明了方向。

















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









