






摘要:我们提出了一种新方法,系统地映射大型语言模型中连续层间由稀疏自编码器发现的特征,这一方法拓展了先前关于层间特征联系的研究。通过使用无数据的余弦相似度技术,我们追踪了特定特征在每个阶段是如何持续、转变或首次出现的。这种方法生成了特征演变的细粒度流图,使得对模型计算的细粒度可解释性和机制性洞察成为可能。至关重要的是,我们展示了这些跨层特征图如何通过放大或抑制选定特征来直接引导模型行为,从而在文本生成中实现有针对性的主题控制。综上所述,我们的研究结果凸显了一个因果性、跨层可解释性框架的实用性,该框架不仅阐明了特征在前向传递过程中是如何发展的,还为大型语言模型的透明操控提供了新手段。Huggingface链接:Paper page,论文链接:2502.03032
1. 引言
1.1 研究背景
大型语言模型(LLMs)在生成连贯文本方面表现出色,但其如何存储和转换语义信息仍然在很大程度上是不透明的。先前的研究表明,神经网络经常将概念编码为隐藏表示中的线性方向,而稀疏自编码器(SAEs)可以在LLMs的情况下将这些方向分解为单义特征。然而,大多数方法仅分析单一层或仅关注残差流,对特征在多层中的出现和转变探讨不足。
1.2 研究目的
本文提出了一种无数据的方法,基于余弦相似度,将SAE特征对齐到大型语言模型的不同模块(如MLP、注意力机制和残差流)中,以捕捉特征在整个模型中的起源、传播或消失形式,即“流图”。这种方法旨在增强对LLMs可解释性和可控性的理解。
2. 预备知识
2.1 线性表示假设
隐藏状态h可以表示为稀疏线性组合的特征f,这些特征位于线性子空间中。每个特征的影响由其大小∥f∥编码。在前向传递过程中,模型通常只使用这些子空间中的一小部分。
2.2 SAE与转码器
SAE可以将模型的隐藏状态分解为稀疏加权和的可解释特征。转码器(Transcoders)与SAE相似,但它们重构的是不同的目标,通常是MLP的可解释近似。
2.3 不同层的特征
同一模型的不同层上训练的SAE特征之间存在相互联系。早期层的特征往往是低级别的,指示单词特性,而后期层的特征通常是高级别的,指导模型行为。
3. 方法
3.1 动机
尽管SAE提供了人类可解释的特征,但它们并没有解释这些特征如何相互作用或模型计算是如何进行的。理解这一点对于更精确地操控模型至关重要。
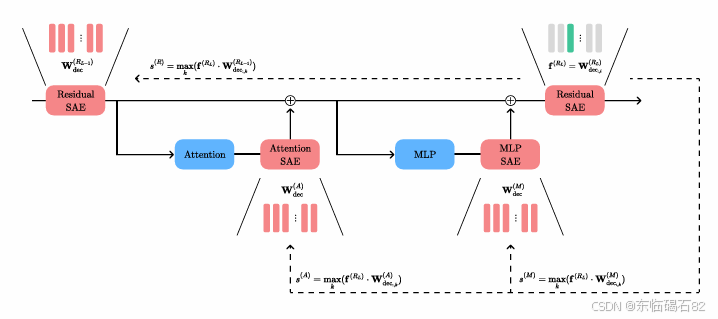
3.2 特征匹配
本文采用了一种无数据的基于SAE权重的方法,使用余弦相似度来匹配不同层之间的特征。这种方法假设SAE是在结构对齐的隐藏状态上训练的。
3.3 追踪特征演变
通过计算目标特征与其他层或模块之间的最大余弦相似度,可以推断出特征与前一层或模块的关系。本文还构建了特征从初始层到最终层的流图,以追踪特征语义属性的演变。
3.4 识别线性特征电路
模型行为可以分解为执行特定任务的计算子网络,称为电路。本文的方法有助于识别潜在电路,其中MLP和注意力模块以线性方式添加或删除特征。
3.5 模型操控
流图还可以帮助通过识别要操纵的特征集来引导模型朝向期望的行为。通过仔细检查构建的流图,可以更好地理解和预测操控后的模型行为。
4. 实验设置
4.1 模型与SAE
本文的主要实验使用Gemma22B模型和Gemma Scope SAE包,还测试了LLama Scope模型。
4.2 实验概述
本文设计了实验来分析残差特征如何在模型层间出现、传播和被操控。具体目标包括:确定特征在不同模型组件中的起源、评估停用前置特征是否真正停用其后代特征、以及使用这些见解来引导模型生成朝向或远离特定主题。
5. 结果
5.1 特征起源的识别
通过验证余弦相似度关系与特征激活相关性的一致性,本文确认了单层分析模式的有效性。实验结果表明,特征组在不同层之间的分布存在差异,可能反映了模型内部信息处理的特性。
5.2 特征停用
本文通过直接干预隐藏状态来测量特征与其前置特征之间的因果关系。实验结果显示,选择最相似的前置特征(top 1方法)在停用目标特征方面表现出色,而随机选择前置特征则效果较差。
5.3 模型操控
本文通过多层干预来测试是否可以阻止或激活特定主题的生成。实验结果表明,多层干预在实现期望结果方面优于单层干预,表明分布在多个层上的小干预可能比单一层上的大干预更有效。
6. 讨论
6.1 特征起源的识别
本文的结果表明,线性方向的相似性确实是激活相关性的良好代理,并且这些组的结构在不同层之间存在差异,可能反映了模型内部信息处理的特性。
6.2 特征停用
本文确认了top 1相似性在提供因果依赖性方面的价值,并得出结论,不同的组对停用某些前置特征的反应不同,表明它们具有不同的机制特性,并可能表现出类似电路的行为。
6.3 模型操控
本文表明,如果想在评估过程中减少特定特征,通常需要调整其幅度。然而,实现显著减少可能需要大幅调整,这可能会改变隐藏状态的分布。通过了解哪些特征有助于减少想要减少的特征,可以做出多个较小的调整,从而避免对隐藏状态整体分布造成剧烈变化。
7. 相关工作
多篇文献探讨了语言模型中的特征电路。一些工作提出了通过修剪模块间连接来找到电路的方法,而另一些工作则使用梯度或稀疏自编码器来识别特征级别的电路。与这些工作相比,本文提出了一种直观且可解释的无数据方法,用于多层操控,并能够追踪特征跨层的演变以及通过定位预训练的SAE权重来识别计算电路。
8. 结论
本文提出了一种使用在不同模块和层上训练的SAE来找到由SAE特征组成的计算图的方法。通过实验验证,这些图可以描述大多数特征动态。最后,本文展示了这些图如何用于操控模型行为,从而改进了使用SAE对LLMs的操控。
9. 影响声明
本文的工作提供了一种系统地识别和操控大型语言模型中潜在特征的方法,从而推动了可控生成领域的发展。这种改进的可控性对AI系统的对齐、可解释性和安全部署具有积极影响,因为它允许开发人员引导模型远离有害或偏见性输出。然而,类似技术也可能被滥用,用于绕过安全保障或利用隐藏模型路径。因此,持续的研究和开放讨论对于可控生成至关重要。
细节补充
9.1 实验细节
- 特征起源识别:本文在四个数据集上进行了实验,包括FineWeb、TinyStories、AutoMathText和PythonGithubCode。对于每个数据集,随机选择样本和令牌,并迭代每个激活特征以确定其组。
- 特征停用:本文在FineWeb数据集的样本上应用了特征停用实验,选择了第6、12和18层,并随机采样多达25个特征进行停用。评估指标包括成功停用率和激活变化分数。
- 模型操控:在操控实验中,本文选择了与特定主题相关的特征集,并构建了从第0层到第25层的流图。通过比较单层操控和累积操控方法,本文评估了不同操控策略对主题存在和语言质量的影响。
9.2 额外结果
- 特征起源识别的额外结果:实验结果显示,“From nowhere”组在所有组中最为普遍,这可能是由于某些特征的偶发激活或匹配错误。此外,注意力模块组的缺失可能是由于本文的训练程序。
- 特征停用的额外结果:top 5方法检测到比其他方法更多的激活前置特征,并检测到更多的组合组。停用残差前置特征在“From RES & MLP”和“From RES & ATT”组中以几乎相等的概率也停用了对应模块上的前置特征或完全停用了目标特征。
- 模型操控的额外结果:在不同层上进行操控的实验结果显示,不同层的表现不同,并且最佳层有时位于初始特征所在层之外。此外,本文还测试了另一个主题的激活,并发现第5层的特征在所有层中给出了最佳结果,尽管初始选择的特征中没有一个位于该层。
9.3 跨模型实验
本文还使用Llama Scope SAE包评估了所提出的方法,并发现结果与Gemma Scope的结果基本一致,尽管存在一些差异,如注意力特征的分布更为均匀。
9.4 流图示例
本文提供了几个有趣的流图示例,如粒子物理图、伦敦图和婚礼与婚姻图。这些流图不仅展示了特征语义的演变,还解释了某些操控程序的结果。
9.5 匹配与转码器的相似性
本文通过比较不同方法来研究匹配与转码器之间的相似性。实验结果显示,余弦相似度在性能上优于其他方法,包括基于排列的匹配和基于转码器的过渡映射。
综上所述,本文提出了一种创新的方法来分析大型语言模型中特征的跨层演变,并通过构建特征流图来增强模型的可解释性和可控性。实验结果验证了该方法的有效性,并为未来的研究提供了新的视角和方向。

















 47
47

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









