






摘要:现代大型语言模型(LLMs)在当前硬件上常常遇到通信瓶颈,而非仅仅是计算限制。多头潜在注意力(MLA)机制通过在键值(KV)层中使用低秩矩阵来应对这一挑战,从而允许缓存压缩后的潜在KV状态。这种方法与传统多头注意力相比,显著减少了KV缓存的大小,从而加快了推理速度。此外,MLA采用上投影矩阵来增强表达能力,以额外的计算换取减少的通信开销。尽管MLA在Deepseek V2/V3/R1中已经证明了其效率和有效性,但许多主要的模型提供商仍然依赖分组查询注意力(GQA),并且尚未宣布采用MLA的任何计划。在本文中,我们证明GQA总是可以通过MLA来表示,同时保持相同的KV缓存开销,但反之则不成立。为了促进MLA的更广泛应用,我们引入了TransMLA,这是一种后训练方法,可以将广泛使用的基于GQA的预训练模型(例如LLaMA、Qwen、Mixtral)转换为基于MLA的模型。转换后,模型可以进行额外的训练以增强表达能力,而不会增加KV缓存的大小。此外,我们计划开发针对MLA的推理加速技术,以保持转换后模型的低延迟,从而实现对Deepseek R1更高效的知识蒸馏。Huggingface链接:Paper page,论文链接:2502.07864
一、引言与研究背景
近年来,大型语言模型(LLMs)已成为提高生产效率不可或缺的工具。随着开源模型的兴起,如AI@Meta的LLaMA、Mistral、Qwen等,它们与闭源模型之间的性能差距正在逐渐缩小。LLMs的有效性主要归因于Next Token Prediction任务,其中模型需要预测序列中的下一个词,并通过计算每个词与前序词之间的注意力来实现。
然而,随着模型规模的增大,键值(KV)对的缓存开销急剧增加,导致内存和通信瓶颈问题日益突出。例如,LLaMA-65B模型在8位KV量化下,需要超过86GB的GPU内存来存储512K个词元,这远远超过了单个H100-80GB GPU的容量。因此,如何减少KV缓存的大小,提高模型的推理速度,成为当前研究的重要方向。
二、相关工作
为了解决LLMs中的KV缓存问题,研究人员提出了多种注意力修改方法。这些方法大致可以分为以下几类:
-
线性注意力机制:如Linear Transformer、RWKV和Mamba等,它们通过将标准注意力机制替换为与序列长度线性相关的机制来减少内存需求。然而,这种方法可能会降低模型的表达能力,导致在需要复杂、长距离词元依赖关系的任务中性能下降。
-
动态词元剪枝:如LazyLLM、A2SF和SnapKV等,它们通过选择性地修剪掉不重要的词元来减少内存使用。虽然这种方法可以提高效率,但存在丢弃关键词元的风险,特别是对于需要深入理解远距离上下文的任务。
-
剪枝头维度:如SliceGPT、Sheared和Simple Pruning等,它们通过减少注意力头的数量或每个头的维度来降低内存使用。然而,过度剪枝可能会损害模型捕捉重要词元关系的能力。
-
跨层共享KV表示:如YONO、MiniCache和MLKV等,它们通过在不同层之间重用相同的KV缓存来降低内存使用。虽然这种方法可以显著降低内存需求并加快推理速度,但跨层共享缓存可能会因不同层的注意力模式不同而影响性能。
-
KV量化技术:如GPTQ、Kivi和KVQuant等,它们通过将KV向量存储在较低位格式中来减少内存使用和计算开销。这种方法可以在几乎不损失性能的情况下实现更长的上下文和更快的推理速度。
三、Multi-head Latent Attention(MLA)机制
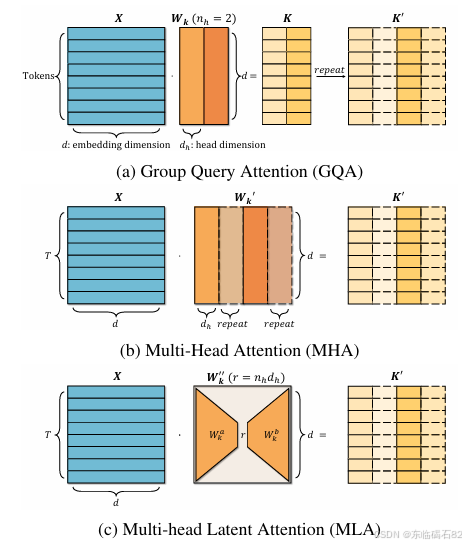
3.1 Multi-head Attention(MHA)与Group Query Attention(GQA)
Multi-head Attention(MHA)是Transformer模型中的核心组件,它通过多个独立的注意力头并行计算注意力,然后将结果拼接起来。每个注意力头都有自己的查询(Q)、键(K)和值(V)矩阵。
Group Query Attention(GQA)是MHA的一种变体,旨在减少KV缓存的开销。它将查询头分成多个组,每个组共享一个键和值对。这种方法通过减少键和值头的数量来降低KV缓存的大小,但可能会牺牲模型的表达能力。
3.2 MLA机制概述
MLA机制通过在KV层中使用低秩矩阵来应对LLMs中的通信瓶颈问题。它利用低秩分解将键和值矩阵分解为两个较小的矩阵的乘积,从而允许缓存压缩后的潜在KV状态。这种方法显著减少了KV缓存的大小,加快了推理速度。
具体来说,MLA机制首先通过线性变换将输入序列映射到查询、键和值空间。然后,它利用低秩分解将键和值矩阵分解为两个矩阵的乘积,其中一个矩阵的维度远小于原始矩阵。在推理过程中,MLA只需要存储这个较小的矩阵作为KV缓存,然后通过将其与另一个矩阵相乘来恢复完整的键和值矩阵。
此外,MLA还采用上投影矩阵来增强表达能力。这个上投影矩阵将压缩后的KV状态映射回原始维度,从而允许模型在保持低KV缓存大小的同时,仍然具有足够的表达能力。
四、TransMLA方法
尽管MLA在Deepseek V2/V3/R1中已经证明了其效率和有效性,但许多主要的模型提供商仍然依赖GQA。为了促进MLA的更广泛应用,本文提出了TransMLA方法,这是一种后训练方法,可以将广泛使用的基于GQA的预训练模型转换为基于MLA的模型。
4.1 GQA到MLA的等价转换
本文首先证明了对于相同的KV缓存开销,MLA的表达能力总是大于GQA。具体来说,任何GQA配置都可以等价地转换为MLA表示,但反之不然。这一结论为将基于GQA的模型转换为基于MLA的模型提供了理论基础。
在等价转换过程中,TransMLA方法首先将GQA中的键矩阵进行复制,以匹配查询头的数量。然后,它将这个复制后的键矩阵分解为两个较小矩阵的乘积,从而得到MLA中的低秩表示。通过这种方法,TransMLA可以在不增加KV缓存大小的情况下,将基于GQA的模型转换为基于MLA的模型。
4.2 模型转换与微调
在将基于GQA的模型转换为基于MLA的模型后,TransMLA方法进一步对模型进行微调,以增强其表达能力。在微调过程中,只训练键、值和输出层的权重,以保持模型的稳定性和收敛性。
实验结果表明,经过转换和微调后的MLA模型在下游任务上表现出了显著的性能提升。特别是在数学和编码任务上,MLA模型的准确率明显高于原始的GQA模型。这一结果表明,MLA不仅能够减少KV缓存的大小,还能够提高模型的表达能力。
五、实验与结果分析
5.1 实验设置
为了验证TransMLA方法的有效性,本文在Qwen2.5框架上进行了实验。Qwen2.5是一个开源的LLM框架,支持多种模型配置和下游任务。在实验中,我们选择了Qwen2.5-7B和Qwen2.5-14B两种模型配置,并将它们转换为基于MLA的模型。
在转换过程中,我们调整了权重矩阵的维度,以匹配MLA的低秩表示。然后,我们使用SmolTalk指令微调数据集对转换后的模型进行训练。SmolTalk是一个包含数学和编码任务的丰富指令微调数据集,适合用于评估模型的表达能力。
5.2 实验结果
实验结果表明,经过转换和微调后的MLA模型在训练过程中表现出了更低的损失值,这表明MLA模型具有更强的数据拟合能力。此外,在测试集上,MLA模型的准确率也明显高于原始的GQA模型。特别是在数学和编码任务上,MLA模型的准确率提升尤为显著。
为了进一步验证MLA的有效性,我们还进行了消融实验。在消融实验中,我们使用恒等映射初始化来扩展键和值矩阵的维度,而不使用低秩分解。实验结果表明,这种方法的性能提升远小于使用低秩分解的MLA模型。这一结果进一步证明了低秩分解在提高模型表达能力方面的关键作用。
六、结论与未来工作
本文提出了TransMLA方法,一种将基于GQA的预训练模型转换为基于MLA的模型的后训练方法。实验结果表明,经过转换和微调后的MLA模型在下游任务上表现出了显著的性能提升。这一结果证明了MLA在提高模型表达能力和减少KV缓存大小方面的有效性。
在未来工作中,我们计划将TransMLA方法应用于更大规模的LLM模型,如LLaMA和Mistral等。此外,我们还计划开发针对MLA的推理加速技术,以保持转换后模型的低延迟。通过这些努力,我们期望能够进一步推动MLA在LLMs中的广泛应用,并为实现更高效的知识蒸馏提供支持。
七、详细分析与讨论
7.1 MLA与GQA的比较
MLA和GQA都是旨在减少KV缓存开销的注意力修改方法。然而,它们在实现方式和性能表现上存在显著差异。
MLA通过低秩分解将键和值矩阵分解为两个较小矩阵的乘积,从而允许缓存压缩后的潜在KV状态。这种方法不仅显著减少了KV缓存的大小,还通过上投影矩阵增强了模型的表达能力。相比之下,GQA通过将查询头分成多个组来减少KV缓存的大小,但这可能会牺牲模型的表达能力。
实验结果表明,对于相同的KV缓存开销,MLA的表达能力总是大于GQA。这一结论为将基于GQA的模型转换为基于MLA的模型提供了理论基础。此外,实验还表明,经过转换和微调后的MLA模型在下游任务上表现出了显著的性能提升。
7.2 TransMLA方法的优势
TransMLA方法具有以下几个优势:
-
灵活性:TransMLA方法可以应用于各种基于GQA的预训练模型,而无需对模型结构进行重大修改。这使得它成为一种灵活且易于实现的模型转换方法。
-
高效性:通过减少KV缓存的大小和加速推理过程,TransMLA方法可以显著提高模型的效率。这对于在大规模数据集上进行训练和推理的任务尤为重要。
-
高性能:实验结果表明,经过转换和微调后的MLA模型在下游任务上表现出了显著的性能提升。这证明了MLA在提高模型表达能力方面的有效性。
7.3 潜在挑战与未来研究方向
尽管TransMLA方法已经取得了显著的成果,但仍然存在一些潜在挑战和未来研究方向:
-
模型压缩与加速:尽管MLA可以减少KV缓存的大小,但对于超大规模模型来说,仍然存在内存和计算资源的限制。因此,未来的研究可以探索如何将MLA与其他模型压缩和加速技术相结合,以实现更高的效率和性能。
-
多模态融合:当前的研究主要集中在文本领域的大型语言模型上。然而,随着多模态技术的不断发展,如何将MLA应用于多模态任务中成为了一个有趣的研究方向。未来的研究可以探索如何将MLA与图像、视频等其他模态的数据相结合,以实现更广泛的应用场景。
-
可解释性与鲁棒性:尽管MLA在性能上表现优异,但其内部机制和决策过程仍然缺乏可解释性。此外,对于对抗性攻击和噪声数据等鲁棒性问题也需要进一步研究。未来的研究可以探索如何提高MLA的可解释性和鲁棒性,以增强其在实际应用中的可靠性。

















 1408
1408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









