







🥧 我的环境:
- 语言环境:Python3
- 深度学习环境:TensorFlow2
🥂 相关教程:
- 编译器教程:新手入门深度学习 | 1-2:编译器Jupyter Notebook
- 深度学习环境配置教程:新手入门深度学习 | 1-1:配置深度学习环境
- 一个深度学习小白需要的所有资料我都放这里了:新手入门深度学习 | 目录
建议你学习本文之前先看看下面这篇入门文章,以便你可以更好的理解本文:
强烈建议大家使用Jupyter Lab编译器打开源码,你接下来的操作将会非常便捷的!
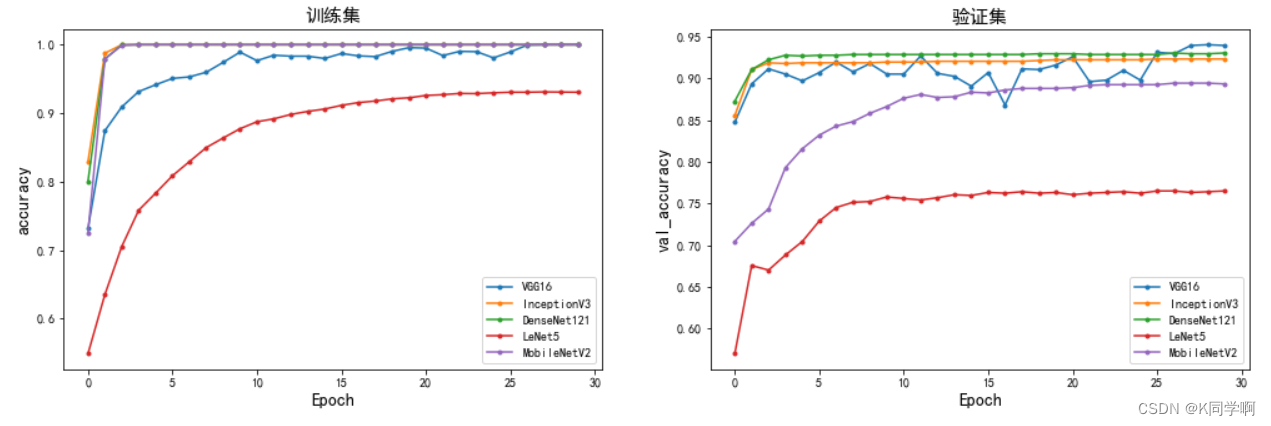
大家好,我是K同学啊!这次为大家准备了一个天气识别的实例,文章我采用了VGG16、ResNet50、IceptionV3、DenseNet121、LeNet-5、MobileNetV2、EfficientNetB0等7个模型来识别天气,使用的数据集包含 5,531 张不同类型天气的图像,最后模型的识别准确率为 93.9% 。
🍰 重点说明:本文为大家准备了多个算法进行对比分析,每一个算法的学习率都是独立的,你可以自由调整。并且为你提供了准确率(Accuracy)、损失(Loss)、召回率(recall)、精确率(precision)以及AUC值等众多指标的对比分析,你只需要选择需要对比的模型、指标以及数据集即可进行相应的对比分析。
🍡 在本代码中你还可以探究的内容如下:
- 同一个学习率对不同模型的影响
- 同一个模型在不同学习率下的性能
- Dropout层的作用(解决过拟合问题)
🍳 效果展示:
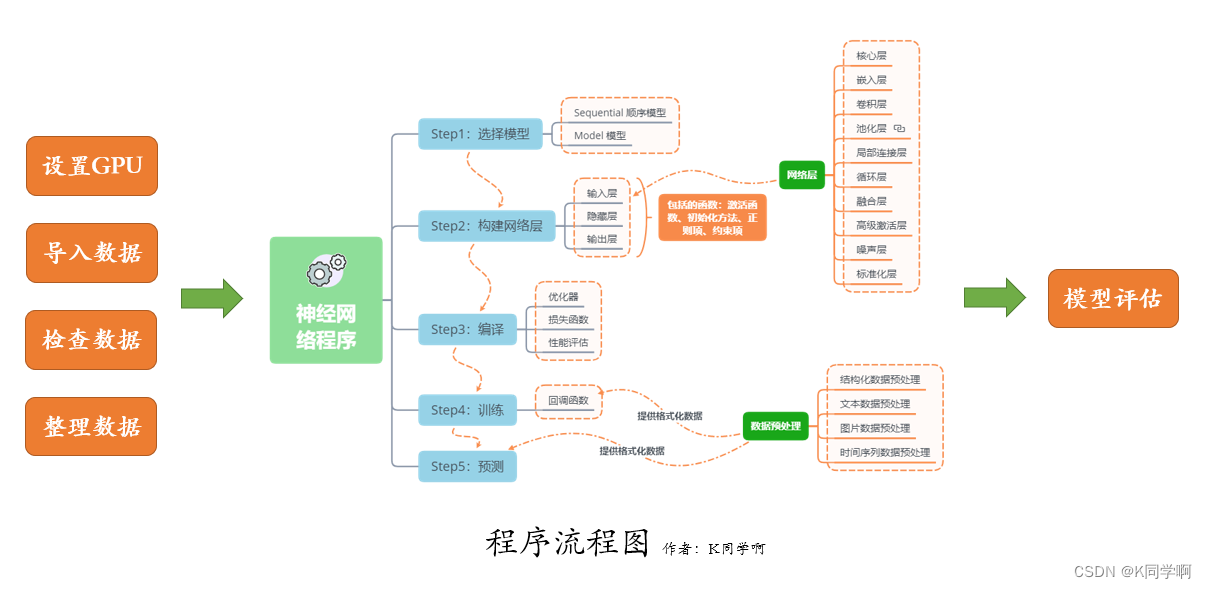
我们的代码流程图如下所示:
文章目录
🍔 前期准备工作
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 打印显卡信息,确认GPU可用
print(gpus)
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
🥗 导入数据
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
"./2-DataSet/",
validation_split=0.2,
subset="training",
label_mode = "categorical",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 5531 files belonging to 9 classes.
Using 4425 files for training.
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
"./2-DataSet/",
validation_split=0.2,
subset="validation",
label_mode = "categorical",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 5531 files belonging to 9 classes.
Using 1106 files for validation.
class_names = train_ds.class_names
print(class_names)
['dew', 'fogsmog', 'frost', 'hail', 'lightning', 'rain', 'rainbow', 'rime', 'snow']
AUTOTUNE = tf.data.AUTOTUNE
# 归一化
def train_preprocessing(image,label):
return (image/255.0,label)
train_ds = (
train_ds.cache()
.map(train_preprocessing) # 这里可以设置预处理函数
.prefetch(buffer_size=AUTOTUNE)
)
val_ds = (
val_ds.cache()
.map(train_preprocessing) # 这里可以设置预处理函数
.prefetch(buffer_size=AUTOTUNE)
)
plt.figure(figsize=(14, 8)) # 图形的宽为10高为5
for images, labels in train_ds.take(1):
for i in range(28):
plt.subplot(4, 7, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示图片
plt.imshow(images[i])
plt.title(class_names[np.argmax(labels[i])])
plt.show()

🥙 设置评估指标metrics
评估指标用于衡量深度学习算法模型的质量,评估深度学习算法模型对于任何项目都是必不可少的。在深度学习中,也有许多不同类型的评估指标可用于衡量算法模型,例如accuracy、precision、recall、auc等都是常用的评估指标。
关于评估指标metrics的详细介绍请参考:🍦新手入门深度学习 | 3-5:评估指标metrics
metrics = [
tf.keras.metrics.CategoricalAccuracy(name='accuracy'),
tf.keras.metrics.Precision(name='precision'),
tf.keras.metrics.Recall(name='recall'),
tf.keras.metrics.AUC(name='auc')
]
🍟 定义模型
🥪 VGG16模型
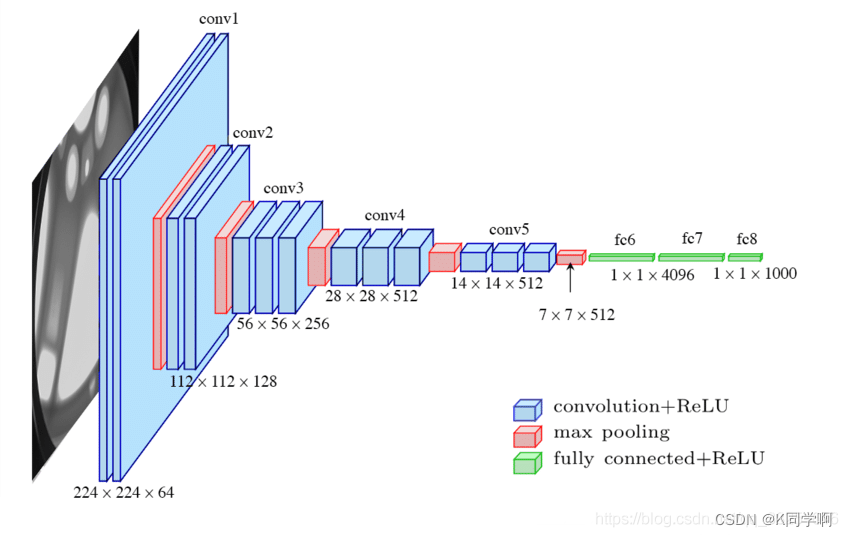
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout,BatchNormalization,Activation
# 加载预训练模型
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5647
5647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











