








AA-CLIP是中科大关于零样本异常检测的一篇论文,已被CVPR2025收录。
arxiv paper:https://arxiv.org/pdf/2503.06661
github:https://github.com/Mwxinnn/AA-CLIP?tab=readme-ov-file
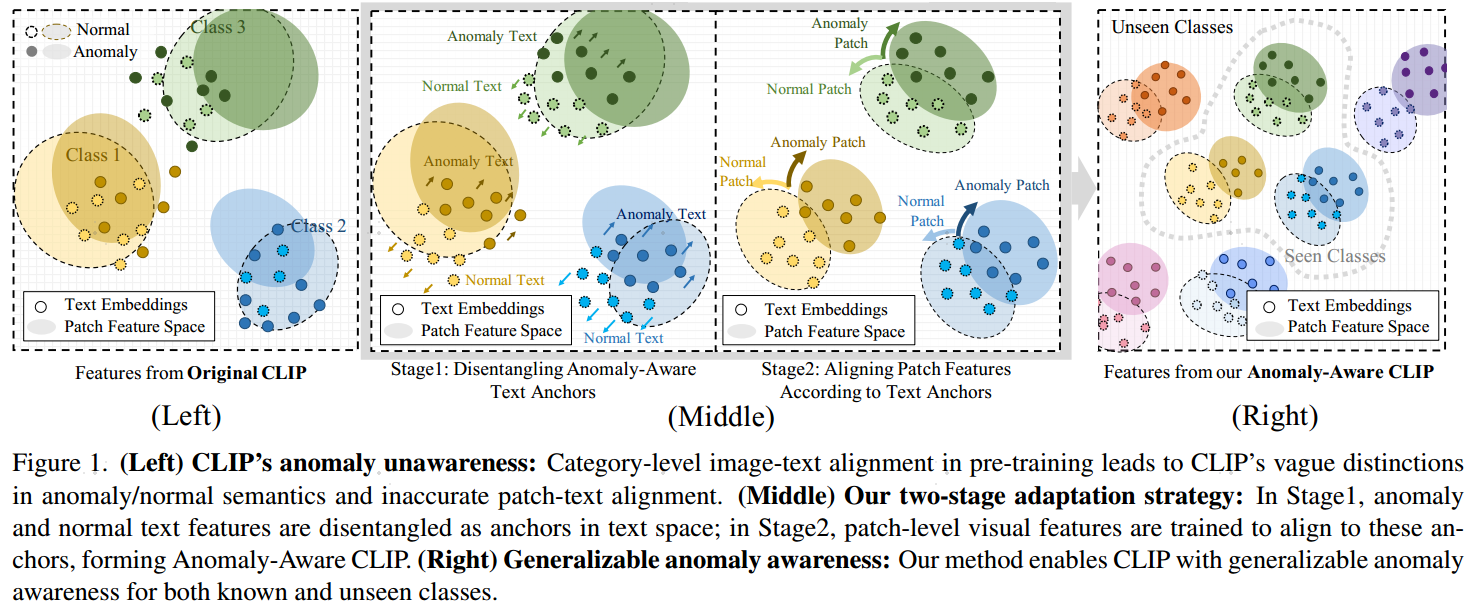
文章的核心在于原始的CLIP由于关注通用能力,缺乏对异常的感知,所以作者通过提升了文本分支对normal和abnormal的区分,提升了CLIP对异常的识别能力。
主要内容概览
AA-CLIP(Anomaly-Aware CLIP) 是一种针对零样本异常检测(Zero-Shot Anomaly Detection)的改进方法,旨在解决传统CLIP模型在区分正常与异常特征时的局限性(即“异常不感知”问题)。该方法通过两阶段策略增强CLIP的异常感知能力,同时保留其强大的跨模态泛化能力:
- 第一阶段:文本空间优化:引入残差适配器(Residual Adapters),调整CLIP的文本编码器,生成明确区分正常与异常语义的“文本锚点”。这些锚点通过“解耦损失”(Disentangle Loss)强制正交化,减少正常与异常文本特征的相关性,从而在文本空间中建立清晰的语义边界。
- 第二阶段:视觉空间对齐:在视觉编码器的浅层嵌入残差适配器,将局部(patch-level)视觉特征与优化后的文本锚点对齐,提升异常定位的精度。通过多粒度特征融合和损失函数(分类损失+分割损失),模型能同时实现图像级异常检测和像素级异常分割。
特性
- 零样本异常检测:无需目标类别的训练数据,直接检测未知类别的异常。
- 高效训练:仅需极少量标注样本(如每类2个样本,正负样本各1个)即可达到高性能。
- 跨领域泛化:在工业(如产品缺陷检测)和医学(如病灶识别)等不同领域均表现优异。
核心优势
- 两阶段优化:同时改进文本和视觉空间,解决CLIP的“异常不感知”问题。
- 轻量适配器:通过残差适配器调整模型浅层,保留CLIP的预训练知识,避免过拟合。
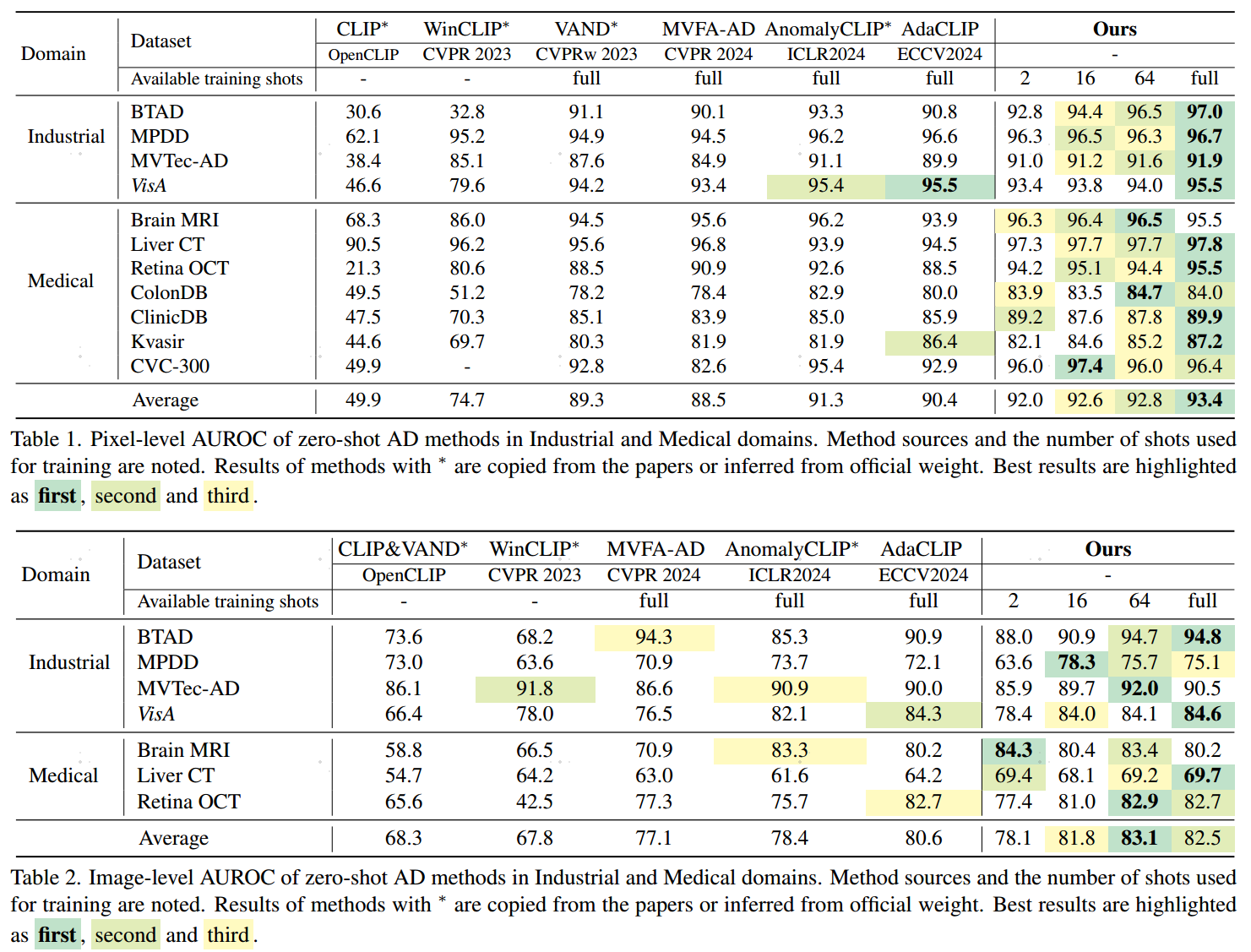
- 高效与泛化:在数据有限的情况下,跨数据集测试达到SOTA性能(如像素级AUROC 93.4%,图像级AUROC 83.1%)。
关于zero-shot任务下对训练数据的定义理解
因为文章宣称最少只需要2个样本训练就能达到很好的效果,这里可能会对新人有一些混淆,这里结合这篇文章解释一下。关于zero-shot和无监督异常检测在工业质检上的区别,可以参考另一篇博客:【工业缺陷检测/工业质检】无监督检测(异常检测Anomaly Detection)与zero-shot零样本检测的区别与定义
本文提出的AA-CLIP确实属于零样本异常检测框架,其核心目标是让模型在测试阶段无需依赖目标类别的标注数据即可检测未知类别的异常。然而,在训练阶段仍需要少量标注样本(如每类2个正常和异常样本),这与零样本学习的定义并不矛盾。
1. 零样本学习的定义与实现方式
- 零样本的核心:模型在推理时能够处理训练阶段未见过的新类别,且无需这些新类别的标注数据。
- 实现条件:通常需要跨类别的语义关联(如文本描述、属性标签等)或少量基础类别的标注数据,以建立从已知到未知的泛化能力。
- AA-CLIP的适配:
在训练时,模型使用部分基础类别的少量标注样本(如工业产品中的某几类缺陷),通过优化文本和视觉空间的异常感知能力,使模型学习到**“正常-异常”的通用区分模式**。测试时,这些模式可直接迁移到新类别(如未训练过的其他工业产品或医学影像),无需新类别的标注数据。
2. 为何需要少量标注样本?
- 解决CLIP的“异常不感知”问题:
CLIP的原始文本编码器缺乏对“正常”与“异常”的语义区分能力。例如,CLIP可能将“划痕”和“光滑表面”的文本特征编码为相近向量,导致视觉特征对齐模糊。
AA-CLIP通过标注样本(如标注为正常或异常的图像)优化文本编码器,强制生成正交化的文本锚点(如“正常锚点”与“异常锚点”),从而在语义空间中明确区分两类特征。 - 残差适配器的学习:
使用残差适配器(Residual Adapters)对CLIP进行微调时,需要少量标注样本来指导适配方向(例如,通过分类和分割损失)。这种微调是任务导向的(学习异常检测的通用能力),而非针对具体目标类别。
3. 标注样本的作用范围
- 训练阶段的标注数据:属于基础类别(如某类工业零件或某类医学影像),用于教会模型区分“正常”与“异常”的通用模式。
- 测试阶段的零样本需求:模型可直接应用于新类别(如从未见过的零件或病灶类型),无需额外标注。
总结
AA-CLIP的“零样本”体现在测试时对未知类别的无需标注,而训练时少量标注样本的作用是建立通用的异常感知能力,而非学习特定类别的特征。这种设计在降低标注成本的同时,实现了跨类别、跨领域的强泛化性能,符合零样本学习的核心目标。
算法实现/核心路径
1. 概览与核心创新
目标:解决CLIP在零样本异常检测中的“异常不感知”问题,即文本和视觉特征对正常与异常语义的区分能力不足。
核心思想:通过两阶段适配策略,分别优化CLIP的文本空间和视觉空间,提升异常检测的语义区分与定位能力,同时保留CLIP的预训练知识。
主要创新点:
- 两阶段优化:
- 文本空间解耦:生成正交化的“正常-异常”文本锚点,明确语义边界。
- 视觉空间对齐:通过多粒度特征融合,增强局部异常区域的敏感度。
- 轻量化适配器设计:
- 在CLIP的文本和视觉分支浅层嵌入残差适配器(Residual Adapters),仅微调少量参数,避免破坏预训练知识。
- 解耦损失(Disentangle Loss):
- 强制正常与异常文本锚点的正交性,提高正常与异常的可区分性。
2. 实现细节
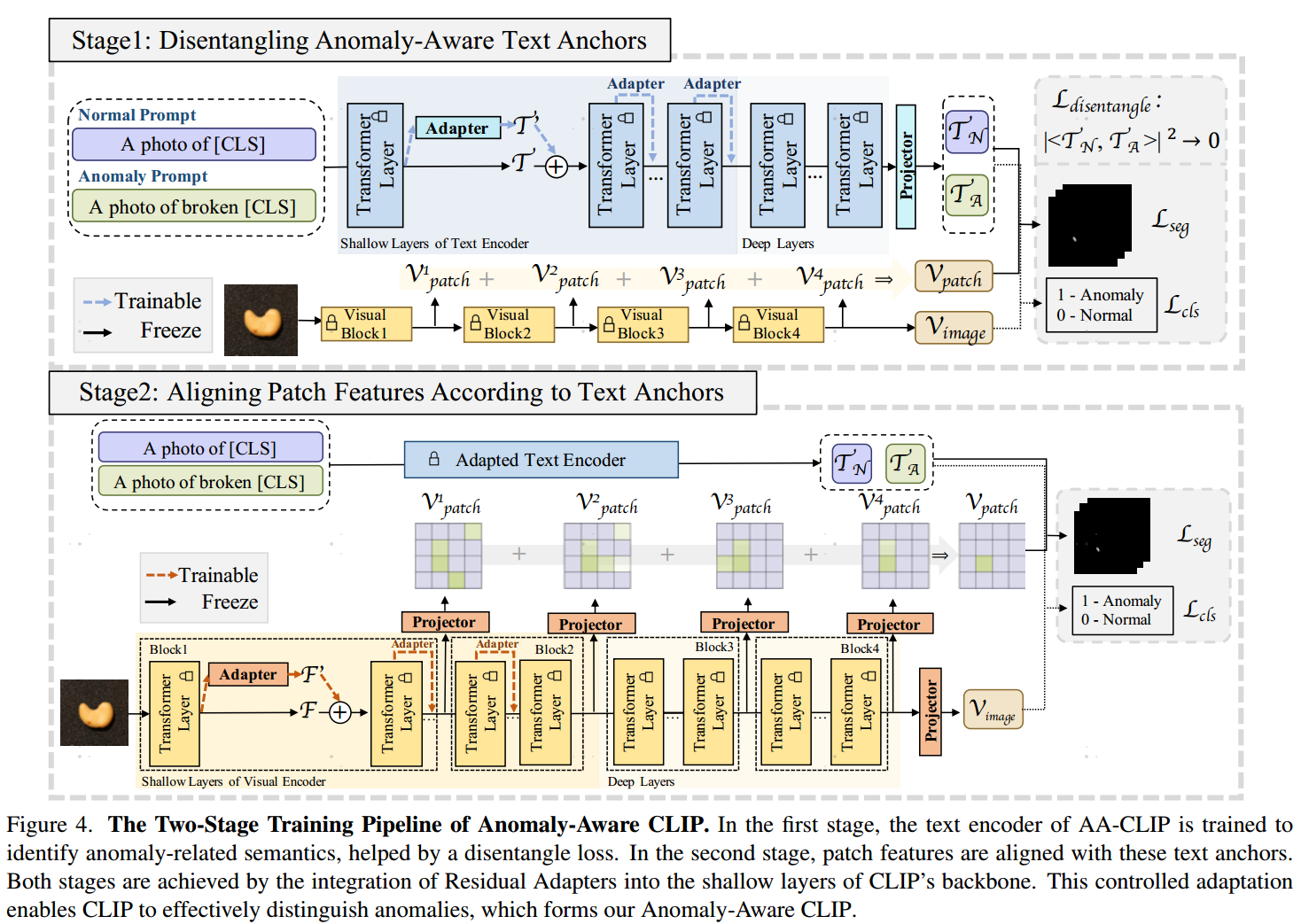
(1) 残差适配器(Residual Adapters)——学习新特征的核心
- 结构设计:
在CLIP文本编码器和视觉编码器的浅层Transformer层(如文本编码器前3层、视觉编码器前6层)插入轻量适配器。 - 数学形式:
对第(i)层输出特征(x^i),适配器生成残差特征:
x r e s i d u a l i = Norm ( Act ( W i x i ) ) x_{residual}^i = \text{Norm}(\text{Act}(W^i x^i)) xresiduali=Norm(Act(Wixi))
其中, W i W^i Wi为可学习的线性权重, Act ( ⋅ ) \text{Act}(·) Act(⋅)为激活函数, Norm \text{Norm} Norm为归一化操作。 - 特征融合:
原始特征与残差特征通过加权融合生成增强特征:
x e n h a n c e d i = λ x r e s i d u a l i + ( 1 − λ ) x i x_{enhanced}^i = \lambda x_{residual}^i + (1-\lambda)x^i xenhancedi=λxresiduali+(1−λ)xi
其中, λ \lambda λ(如0.1)控制残差比例,平衡新知识与原始特征。
(2) 两阶段训练策略
阶段一:文本空间解耦(生成异常感知文本锚点)
- 输入:正常与异常的文本提示(如“a normal [CLASS]”和“an anomalous [CLASS] with [DEFECT]”)。
- 优化目标:
-
对齐损失( L a l i g n \mathcal{L}_{align} Lalign):包含图像级分类损失( L c l s \mathcal{L}_{cls} Lcls)和像素级分割损失( L s e g \mathcal{L}_{seg} Lseg)。
L c l s = BCE ( p c l s , y ) , L s e g = Dice ( p s e g , S ) + Focal ( p s e g , S ) \mathcal{L}_{cls} = \text{BCE}(p_{cls}, y), \quad \mathcal{L}_{seg} = \text{Dice}(p_{seg}, S) + \text{Focal}(p_{seg}, S) Lcls=BCE(pcls,y),Lseg=Dice(pseg,S)+Focal(pseg,S) -
解耦损失( L d i s \mathcal{L}_{dis} Ldis)实现正常与异常区分的核心:强制正常锚点 T N T_N TN与异常锚点 T A T_A TA正交 :
L d i s = ∣ < T N , T A > ∣ 2 \mathcal{L}_{dis} = |<T_N, T_A>|^2 Ldis=∣<TN,TA>∣2
-
总损失: L t o t a l = L a l i g n + γ L d i s \mathcal{L}_{total} = \mathcal{L}_{align} + \gamma \mathcal{L}_{dis} Ltotal=Lalign+γLdis( γ = 0.1 \gamma=0.1 γ=0.1)。
-
阶段二:视觉空间对齐(优化局部特征)
- 多粒度特征提取:
从视觉编码器的不同层(如第6、12、18、24层)提取特征,通过可学习投影器(Proj_i(\cdot))对齐到文本锚点空间。 - 特征融合:
多层级特征聚合为 V p a t c h = ∑ i = 1 4 V p a t c h i V_{patch} = \sum_{i=1}^4 V_{patch}^i Vpatch=∑i=14Vpatchi,计算与文本锚点的余弦相似度,生成异常热图。 - 训练目标:
沿用阶段一的 L a l i g n \mathcal{L}_{align} Lalign,优化视觉编码器的适配器参数,提升局部对齐能力。
(3) 关键参数与训练设置
- 模型架构:基于OpenCLIP的ViT-L/14,输入分辨率518×518。
- 训练配置:
- 阶段一:5 epochs,学习率 1 × 1 0 − 5 1\times10^{-5} 1×10−5。
- 阶段二:20 epochs,学习率 5 × 1 0 − 4 5\times10^{-4} 5×10−4。
- 优化器:Adam,单卡训练(NVIDIA RTX 3090)。
总结
AA-CLIP通过两阶段轻量化适配策略,在文本空间建立清晰的正常-异常语义边界,并在视觉空间强化局部特征对齐,有效解决了CLIP的“异常不感知”问题。其核心创新在于解耦损失与残差适配器的设计,实现了高效、精准的零样本异常检测,为工业质检和医学影像分析提供了通用解决方案。
核心创新解读——Disentangle Loss的实现细节
在AA-CLIP的第一阶段训练中,Disentangle Loss(解耦损失) 是解决CLIP“异常不感知”问题的核心设计。
1. Disentangle Loss的数学形式
- 目标:强制正常文本锚点 T N T_N TN 与异常文本锚点 T A T_A TA 在文本空间中正交,减少语义混淆。
- 定义:
L d i s = ∣ < T N , T A > ∣ 2 \mathcal{L}_{dis} = |<T_N, T_A>|^2 Ldis=∣<TN,TA>∣2
其中, < T N , T A > <T_N, T_A> <TN,TA> 表示两者的内积,平方操作进一步放大相关性。 - 物理意义:
最小化 L d i s \mathcal{L}_{dis} Ldis 等价于迫使 T N T_N TN 与 T A T_A TA 的夹角接近90度(正交),从而在文本空间中建立清晰的语义边界。
2. 实现流程
-
文本锚点生成:
- 对于每个类别,输入正常提示(如“a normal [CLASS]”)和异常提示(如“an anomalous [CLASS] with [DEFECT]”)。
- 通过文本编码器(含残差适配器)生成对应的文本特征 T N T_N TN 和 T A T_A TA。
-
损失计算:
- 在每批次训练中,计算当前批次所有类别的 T N T_N TN 和 T A T_A TA的内积平方均值。
- 例如,若批次包含 (B) 个类别,则:
L d i s = 1 B ∑ i = 1 B ∣ < T N ( i ) , T A ( i ) > ∣ 2 \mathcal{L}_{dis} = \frac{1}{B} \sum_{i=1}^B |<T_N^{(i)}, T_A^{(i)}>|^2 Ldis=B1i=1∑B∣<TN(i),TA(i)>∣2
3. 作用与效果
-
语义解耦:
通过正交约束,正常与异常文本锚点在嵌入空间中形成独立的簇,避免语义重叠(如图3所示)。 -
增强异常敏感性:
文本空间的清晰区分引导视觉编码器更精准地分离正常与异常区域的特征。 -
零样本泛化:
解耦后的文本锚点具有类别无关性(如“正常”与“异常”的通用概念),可迁移到未见类别。 -
文本特征可视化(图3)显示,未使用该损失时,正常与异常文本特征仍存在部分重叠。

实验结果
附:基于CLIP的一些其他异常检测方法
因为CLIP的强大能力,其实已经有很多类似的对CLIP改进来提升异常检测效果的算法,这里结合论文中提到的简单列举几个
1. WinCLIP
- 改进点:
提出多层级视觉特征提取与聚合,通过整合CLIP视觉编码器不同层级的特征(如浅层细节和深层语义),增强局部与全局信息的融合。 - 核心方法:
- 提取多尺度视觉特征(如不同Transformer层的输出)。
- 通过特征融合策略(如加权平均或拼接)生成综合特征表示。
- 与文本特征进行对比对齐,提升异常定位能力。
- 优势:
在零样本场景下,通过多粒度特征提升对复杂异常的检测能力。 - 局限性:
依赖原始CLIP的文本编码器,未解决正常与异常语义混淆问题。
2. VAND
- 改进点:
在视觉编码器中引入线性投影层(Linear Projector),优化局部(patch-level)视觉特征的表示能力。 - 核心方法:
- 在CLIP视觉编码器的中间层插入轻量级线性投影模块。
- 通过投影后的局部特征与文本特征对齐,提升异常区域的响应。
- 优势:
简单高效,显著提升像素级异常定位性能。 - 局限性:
仅优化视觉特征,未改进文本空间的语义区分,导致异常判别依赖原始CLIP的模糊文本嵌入。
3. MVFA-AD
- 改进点:
提出多视角特征对齐(Multi-View Feature Alignment),结合图像级和像素级对齐策略。 - 核心方法:
- 同时优化图像整体与局部区域的跨模态对齐。
- 引入辅助损失函数(如对比损失)强化特征一致性。
- 优势:
兼顾全局异常分类与局部异常定位,提升综合性能。 - 局限性:
训练复杂度较高,对标注数据量需求较大。
4. AnomalyCLIP
- 改进点:
通过**可学习的提示词(Learnable Prompts)**动态调整文本编码,增强异常语义的表达。 - 核心方法:
- 在文本提示中插入可学习的嵌入向量(如“[DEFECT]”)。
- 通过端到端训练优化提示词,使文本特征更适配异常检测任务。
- 优势:
提升文本提示的灵活性,适应多样化的异常类型。 - 局限性:
可能破坏CLIP的预训练知识,导致泛化能力下降(尤其在数据稀缺场景)。
5. AdaCLIP
- 改进点:
采用混合可学习提示(Hybrid Learnable Prompts),结合固定模板与动态参数,平衡任务适配与知识保留。 - 核心方法:
- 设计固定部分(如“a photo of [CLASS]”)与可学习部分(如异常描述词)的混合提示模板。
- 通过参数微调优化异常相关的语义表达。
- 优势:
在保持CLIP泛化能力的同时,增强对异常特征的敏感性。 - 局限性:
对异常语义的建模仍依赖人工设计的提示模板,难以覆盖复杂场景。
总结对比
| 方法 | 改进核心 | 优势 | 局限性 |
|---|---|---|---|
| WinCLIP | 多层级特征聚合 | 增强局部与全局对齐 | 依赖原始CLIP文本编码,语义区分不足 |
| VAND | 视觉局部特征投影 | 简单高效,提升定位精度 | 未优化文本空间,依赖模糊语义 |
| MVFA-AD | 多视角对齐(图像+像素) | 综合性能强 | 训练复杂度高,数据需求大 |
| AnomalyCLIP | 可学习提示词 | 动态适配异常语义 | 可能破坏CLIP预训练知识 |
| AdaCLIP | 混合提示模板 | 平衡适配与泛化 | 依赖人工设计模板,灵活性受限 |
AA-CLIP的差异化创新
相较于上述方法,AA-CLIP的核心改进在于:
- 文本空间解耦:通过残差适配器与解耦损失,强制分离正常与异常文本锚点,解决CLIP的“异常不感知”问题。
- 视觉空间多粒度对齐:融合多层级视觉特征,并通过适配器优化局部表示,提升细粒度异常定位能力。
- 轻量化设计:仅调整浅层参数,保留CLIP的预训练知识,确保泛化性与效率的平衡。


















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











