







一、前言
Bert是对GPT一代的改进,将其中的单向Transfromers变成了双向的,拓宽了NLP领域的各种任务,为后来LLMs的发展起到了极强的作用,是深度学习领域的一项重要的创新性模型。
二、模型架构
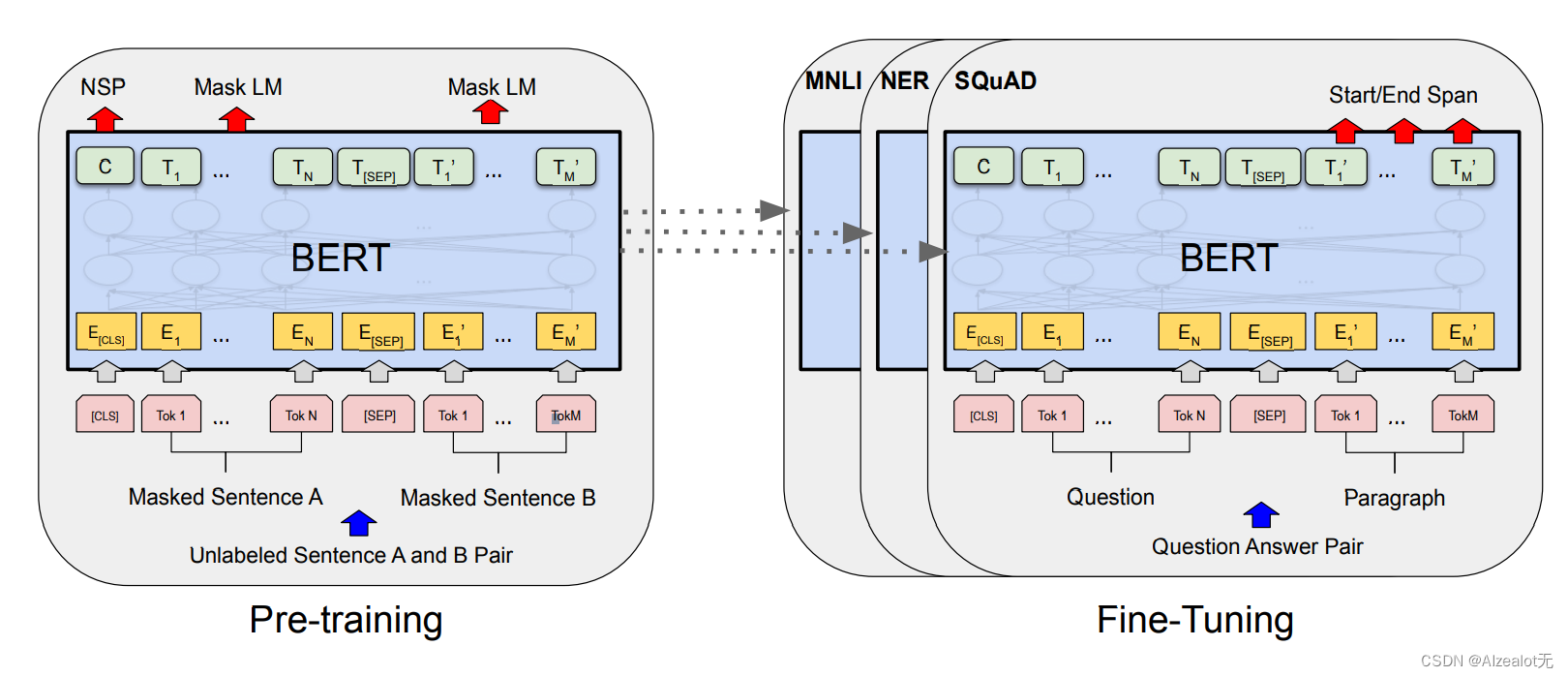
主要分为Bert预训练和Fine-Tuning两个部分。
三、词的表示

本研究中,Bert将三种表示简单加和,使用到尽可能多的文本信息。
四、预训练

创新之处在于用到的是二向Transformer,在两项无监督任务上做了预训练。

又使用了这种Masked 模型去防止信息的串通,随机掩盖了一部分信息,以防止二向时的不同的数据相互串通。

然后在一个文本预测任务上做了预训练。
五、微调

简而言之,BERT的微调能够在两个句子之间进行很好地信息Attention,可以理解为将有用的信息聚合,比单向的优势在于此。
因此,Bert能够更好地进行一系列NLP任务,拓宽了大语言模型的性能和应用范围。
六、结语
关注无神,一起学机器学习!
有问题欢迎评论区留言交流。
码字不易,期待您的一键三连。















 789
789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









