






长短时记忆网络(LSTM)作为当前最流行的RNN,能成功解决原始循环神经网络的缺陷,运用于语音识别、图片描述、自然语言处理等许多领域。
将卷积神经网络(CNN)的特征提取能力与长短期记忆网络(LSTM)的时序建模能力相结合,能够显著提升模型在时序数据处理、图像处理和视频分析等任务中的表现。
因此,【LSTM+CNN】技术在行为识别、视频分类、医疗诊断等多个领域展示了其潜力和有效性,其创新的方法和良好的表现使其成为研究的热点之一。
为了帮助大家寻找发文的创新点,本文总结了20篇最近两年内【LSTM+CNN】论文研究成果,这些论文的文章、来源以及论文的代码都整理好了,有需要的同学赶快扫码领取!
需要的同学添加公众号【沃的顶会】 回复 LS20 即可全部领取
自动语音识别(ASR)端到端深度学习模型
Automatic speech recognition for the Nepali language using CNN, bidirectional LSTM and ResNet
文章解析:
这篇文章介绍了一种用于尼泊尔语自动语音识别(ASR)的端到端深度学习模型。该模型通过训练和测试OpenSLR数据集,将尼泊尔语的语音转换成文本。通过有效结合不同的神经网络组件,实现了较低的字符错误率。
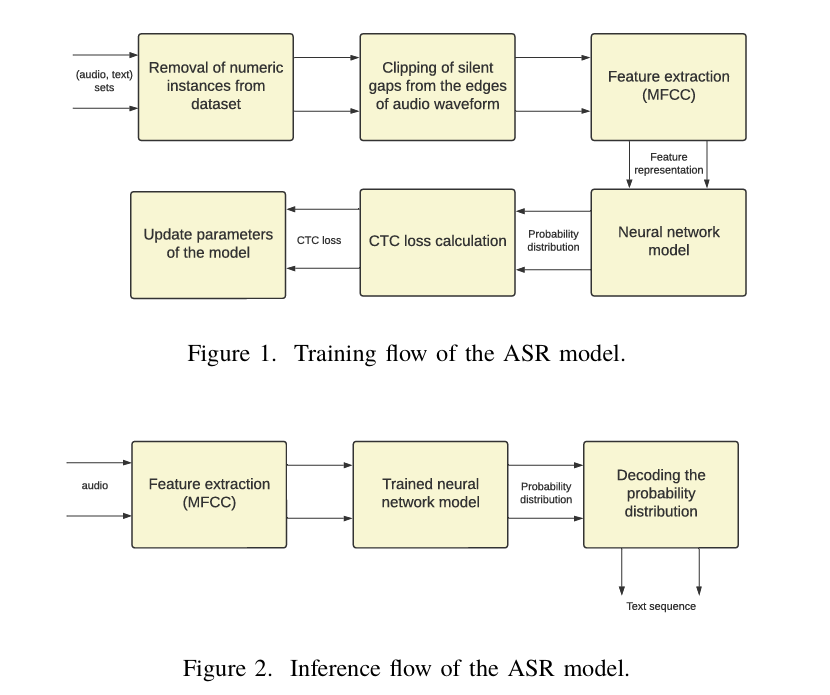
在数据预处理阶段,剪除了音频数据两端的静音间隙,以实现更统一的音频帧与相应文本的映射。模型使用梅尔频率倒谱系数(MFCCs)作为音频特征输入。
创新点:
1.研究中尝试了多种神经网络结构,包括不同变体的LSTM、GRU、CNN和ResNet。结果表明,将双向长短期记忆网络(BiLSTM)与一维CNN和ResNet结合的模型在该数据集上表现最佳。该模型在训练期间使用连接主义时序分类(CTC)函数进行损失计算,并使用CTC束搜索解码预测尼泊尔文本的最可能字符序列。在测试数据集上,该模型达到了17.06%的字符错误率(CER)。
2.数据采集和预处理步骤:去除数字实例、剪切静音间隙、使用MFCCs作为特征提取技术。MFCCs能够基于功率谱生成特征向量,是尼泊尔语ASR领域中一个强大的特征提取技术。
实验方法:
1.模型中使用ResNet、1D-CNN、RNN(特别是LSTM和GRU)以及CTC损失函数为机器学习组件。
ResNet通过引入残差学习框架解决深度神经网络的退化问题。1D-CNN用于提取局部化特征,而RNN变体则适用于处理序列数据。CTC损失函数允许模型在训练期间处理输入音频和输出文本之间的未知对齐。
2.使用BiRNN来提高预测的准确性,并引入dropout技术以避免过拟合。
3.实验设置:使用OpenSLR数据集的训练过程,包括数据集划分、音频采样、特征提取和优化器设置。
训练过程使用了Adam优化器,并且模型在NVIDIA Tesla T4 GPU上进行了多达58个周期的训练。
实验结果:
1.实验结果展示了不同模型在测试数据集上的CER,并讨论了模型性能。最终,结合1D-CNN、ResNet和BiLSTM的模型在未见过的测试数据集上实现了最低的CER,达到了82.94%的字符准确率。
2.结论:ResNet结合1D-CNN和BiLSTM的模型取得了最佳结果,并克服了CTC损失值早期饱和的限制。有效的数据清洗过程改善了音频帧与对应字符之间的对齐。
需要的同学添加公众号【沃的顶会】 回复 LS20 即可全部领取
手机识别任务中的原始波形声学模型
Phonetic Error Analysis of Raw Waveform Acoustic Models with Parametric and Non-Parametric CNNs
文章解析:
本文分析了TIMIT手机识别任务中原始波形声学模型的误差模式。此次分析超越了传统的电话错误率(PER)度量标准。
与原始波形模型相比,本次研究开发了一个在TIMIT上性能最高的原始波形模型,并计算了每个类别中每个BPC的PER。
此外,还研究了来自《华尔街日报》的迁移学习对原始波形模型性能的影响。为每个语音分类构建了一个混淆矩阵,包括没有迁移学习和有迁移学习的原始波形模型,并将其与Wav2vec 2.0和滤波器组系统的语音混淆模式进行了比较。
创新点:
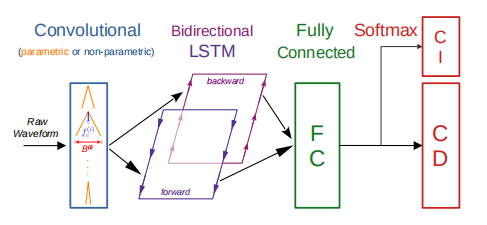
1.开发具有参数级联(Sinc2Net)或非参数CNNs和循环层的原始波形声学模型,与其他原始波形模型相比,它们在TIMIT 上获得了最高的性能。
2.计算原始波形模型的每个语音分类中所有广泛的语音类的PER。
3.计算原始波形模型的每个语音分类的混淆矩阵。
4.探讨了来自《华尔街日报》的迁移学习对语音错误和混淆矩阵的影响。
5.用最先进的Wav2vec 2.0和基于滤波器组的系统比较分析每个BPC的平均速度和原始波形模型的混淆模式。
实验方法及结果:
1.将手机分为三组:{摩擦音、双元音、摩擦音、鼻音、爆炸音、半元音、元音、沉默音、{辅音、元音+、沉默音、{浊音、无声音},并计算每个类别中每个广义语音类的PER。
2.利用替代误差为每个类别构造了一个混淆矩阵,并将其混淆模式与过滤器组和Wav2vec 2.0系统的混淆模式进行了比较。
3.本次原始波形声学模型由参数(Sinc2Net)或非参数cnn和双向lstm组成,在TIMIT Dev/测试集上实现了到13.7%/15.2%的PERs,优于先前文献中报道的原始波形模型的PERs。
4.研究了来自《华尔街日报》的迁移学习对语音错误模式和混淆矩阵的影响。它将开发/测试集上的PER降低为11.8%/13.7%。
需要的同学添加公众号【沃的顶会】 回复 LS20 即可全部领取

















 1677
1677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









