







在医学图像分割领域,Mamba已经形成了与CNN、Transformer三足鼎立之势。与其他两者相比,Mamba具有更强的长距离信息交互能力与线性时间复杂度,能够更高效地处理长序列数据,减少内存需求,实现更快的推理速度。
最新的顶会论文也关注到了Mamba在医学领域的广泛应用和前景。例如,有论文提出了基于Mamba的U-Net变体,如SegMamba、VM-UNet等,这些模型在医学图像分割任务中取得了比CNN和Transformer更好的结果。
我整理了10篇最新Mamba用于医学领域的研究论文,需要的同学添加工中号【真AI至上】 回复 曼巴医学 即可全部领取
SegMamba: Long-range Sequential Modeling
文章解析:
本文介绍了一种名为SegMamba的新3D医学图像分割模型,该模型结合了U形结构和Mamba,能够有效地捕捉全体积特征中的长程依赖关系。
与传统的CNN和Transformer方法相比,SegMamba在处理高分辨率3D医学图像时表现出更高的效率和速度。此外,作者还贡献了一个新的大规模3D结直肠癌分割数据集CRC-500。
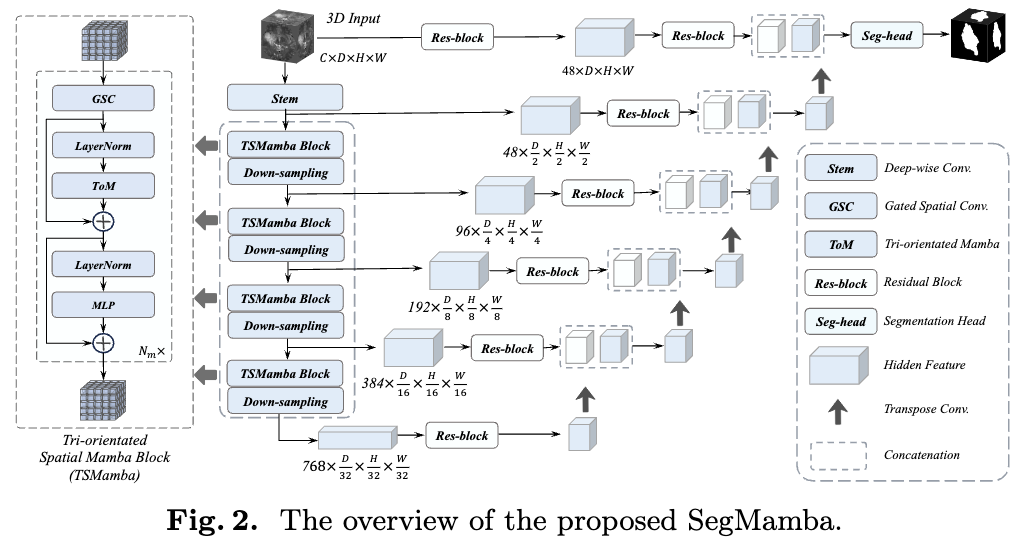
创新点:
1.首次将Mamba模型应用于3D医学图像分割,有效捕捉全体积特征中的长程依赖关系。
2.设计了三向Mamba(ToM
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









