







优化算法
牛顿法
利用目标函数的二阶导数进行曲率校正来加速一阶梯度下降。
与一阶优化器相比,其收敛速度更快,能高度逼近最优值,几何上下降路径也更符合真实的最优下降路径
一维:
灰色线为最佳梯度方向,红色线为一阶梯度方向,绿色线为二阶梯度方向
显然二阶梯度方向更逼近最佳梯度方向,且到二阶导的最低点的距离
Δ
x
=
x
−
a
0
\Delta x=x-a_0
Δx=x−a0一般认为是最优步长
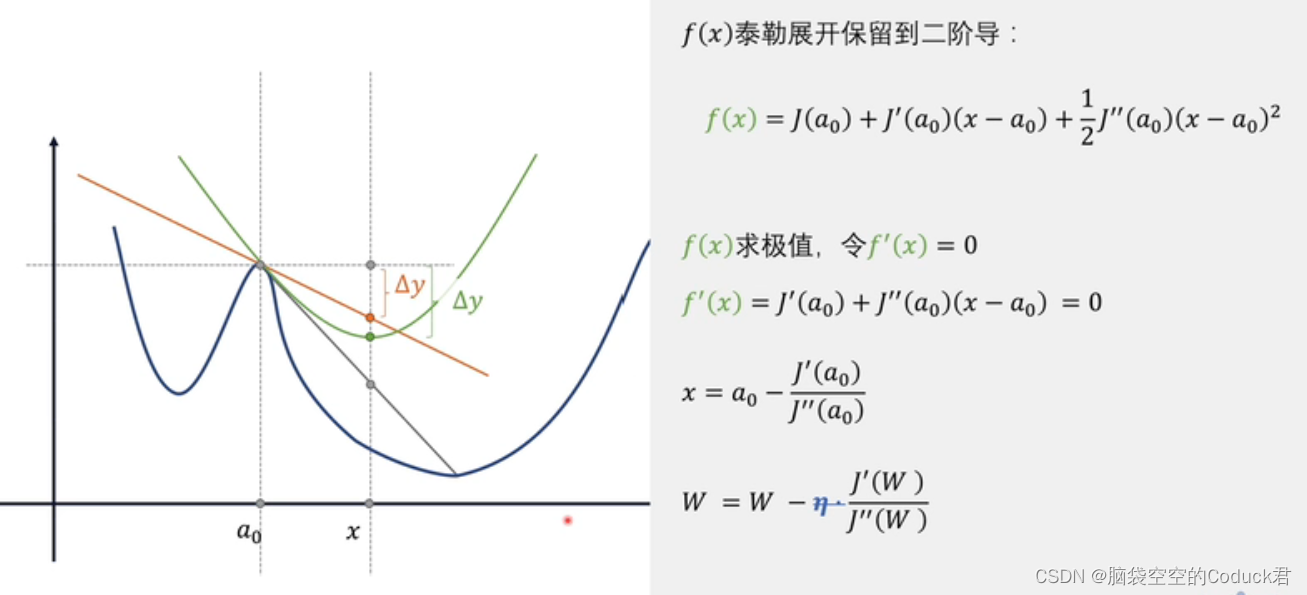
注意:没有学习率 η \eta η,学习步长是确定的,即为 Δ x \Delta x Δx,如果在非凸的目标函数中,可能要重新引入学习率
多维:
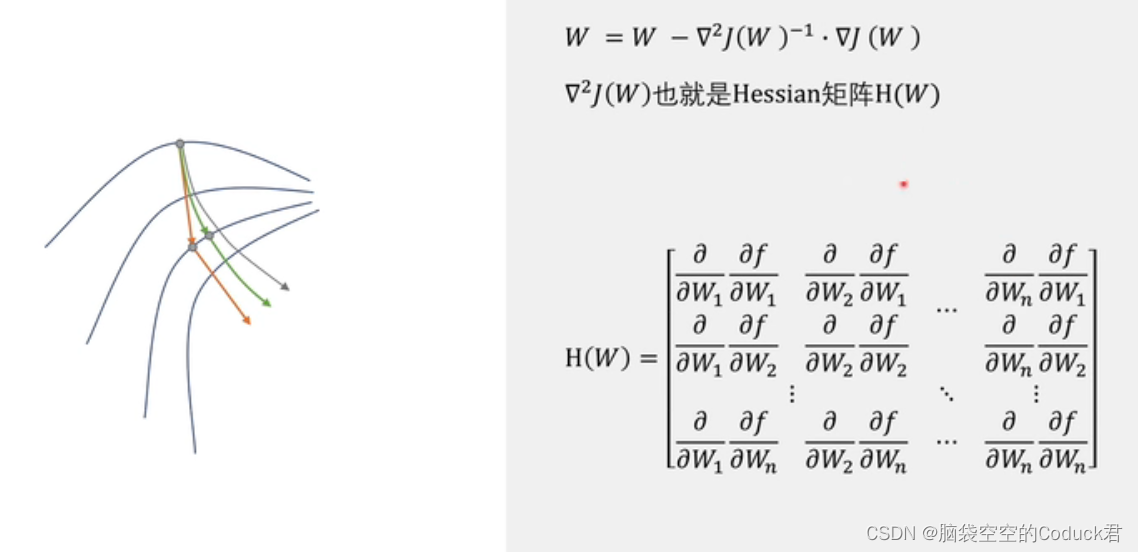
代码:
mindspore.nn.thor(net, learning_rate, damping, momentum, weight_decay=0.0, loss_scale=1.0,
batch_size=32, use_nesterov=False,
decay_filter=<function <lambda> at 0x000002005CAA9550>, split_indices=None,
enable_clip_grad=False, frequency=100)
随机梯度下降
批量梯度下降
虽然梯度下降较快,但梯度下降都是采用所有样本(尤其是大数据集时)来计算,这就导致计算量很大
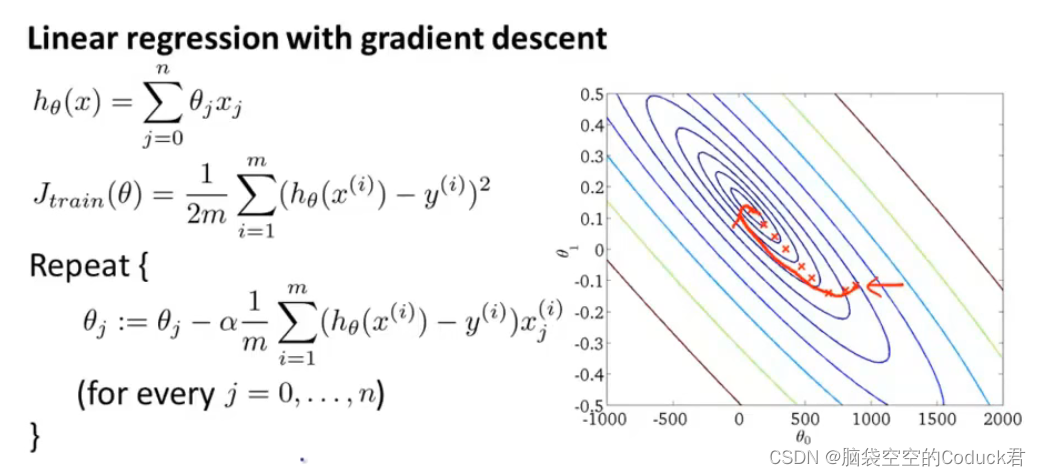
所以,随机梯度下降正是要优化计算梯度的问题
随机梯度下降的思想:每次只采用一个样本来更新梯度,减少计算量

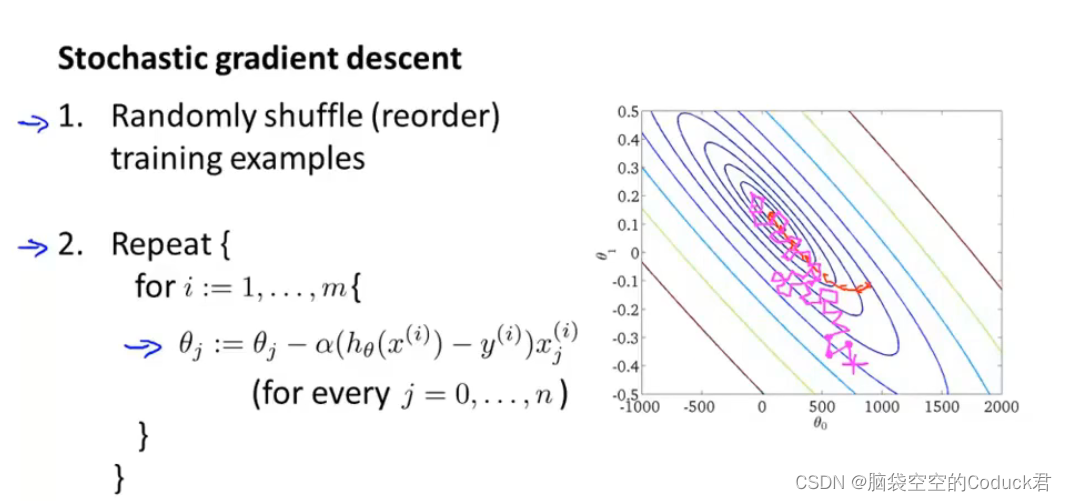
随机梯度下降中变量的轨迹比批量梯度下降 中观察到的梯度下降中观察到的轨迹嘈杂得多。这是由于梯度的随机性质。也就是说,即使我们接近最小值,我们仍然受到瞬间梯度所注入的不确定性的影响。即使经过50次迭代,质量仍然不那么好。更糟糕的是,经过额外的步骤,它不会得到改善。这给我们留下了唯一的选择:改变学习率,采用动态降低学习率的方法。
注意:
1、首先对数据要进行随机排序
2、虽然每次只采用一个样本去更新梯度,但是代价函数还是要计算所有样本的代价

3、随机梯度下降的时候,下降的路径可能会很曲折,不断波动,但是总体趋势还是会不断减小。但是最后可能不一定能够收敛到全局最小值,但是也会收敛到近似最小值
4、外循环Repeat次数按实际情况
为了进一步优化,我们采用在优化过程中动态降低学习率的方法

小批量随机梯度下降

尽管在处理的样本数方面,随机梯度下降的收敛速度快于梯度下降,但与梯度下降相比,它需要更多的时间来达到同样的损失,因为逐个样本来计算梯度并不那么有效。 小批量随机梯度下降能够平衡收敛速度和计算效率。
代码:
mindspore.nn.SGD(params, learning_rate=0.1, momentum=0.0, dampening=0.0, weight_decay=0.0,
nesterov=False, loss_scale=1.0)
动量法
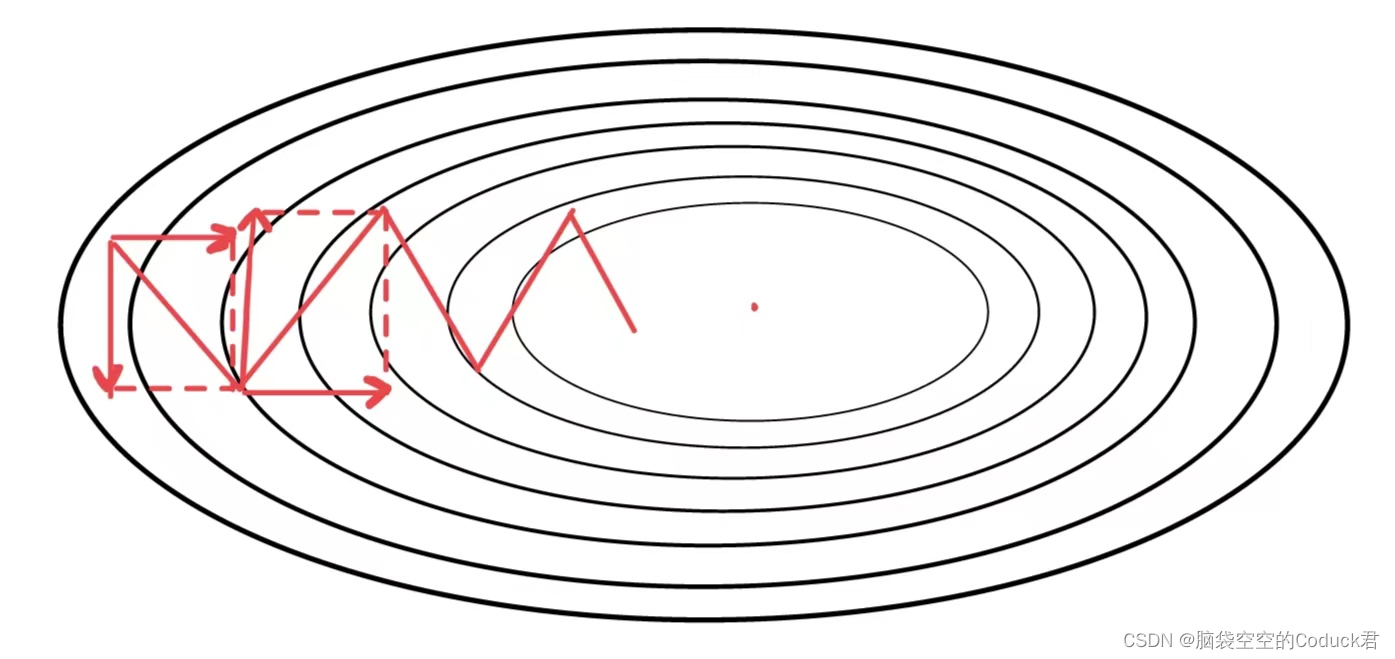
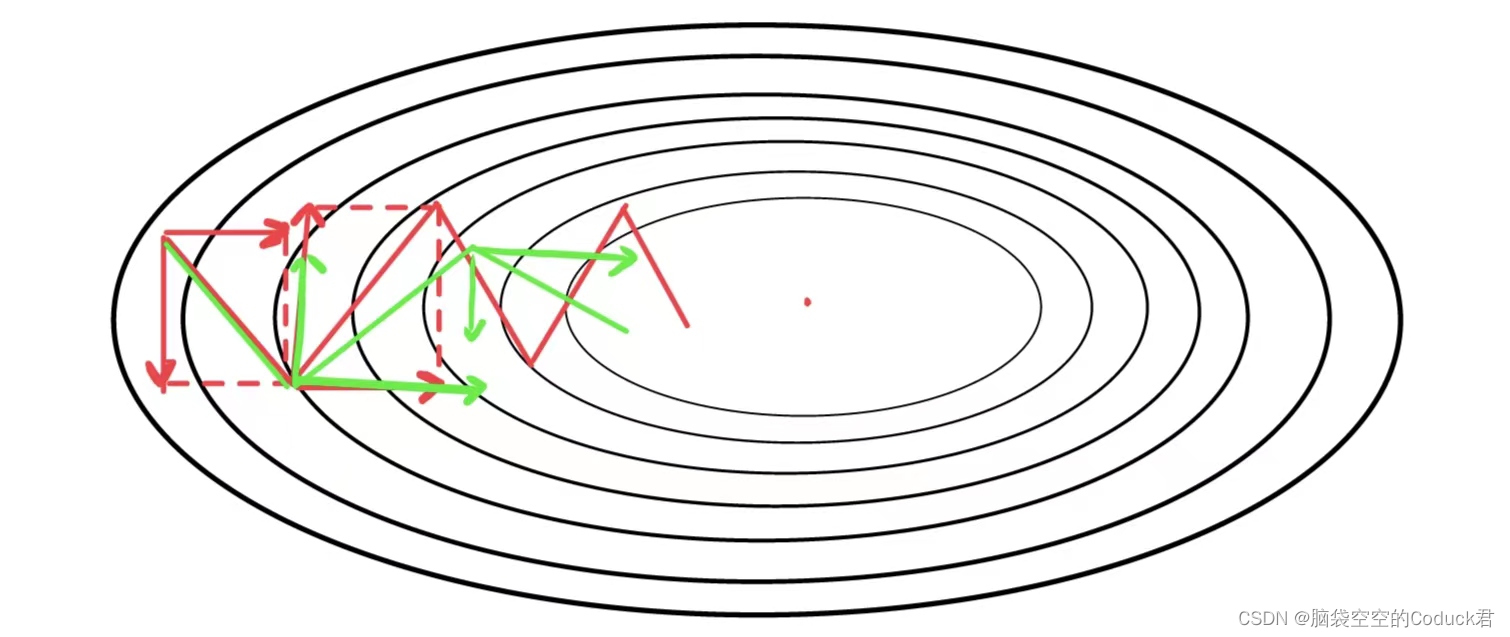
在梯度下降过程中,梯度下降的方向总是向最优路径方向偏移,将梯度方向分解,能发现梯度方向可分解为横轴上前进方向和纵轴上的偏移方向,若能弱化偏移方向,增强前进方向,则能更快到达最低点。红色路径为最初路径,绿色路径为以上方法优化后的路径。















 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









