






LLaMA-Factory是一个非常好用的开源的无代码微调框架,在模型微调方式、参数配置、数据集设置、模型保存、模型合并、模型测试以及模型试用上,提供了非常完备的开发接口。下面是对微调全过程(数据集篇)的一个记录。
数据模型准备
微调时一般需要准备三个数据集:一个是自我认知数据集,一个是特定任务数据集,一个是通用任务数据集。
特定任务数据集一般是要自定义的,由于对于这个计算机行业面试模拟的大模型来说,我们需要的要求是
我们准备的自定义数据集的格式如下:
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)"
}
]
如果不需要考虑多轮对话的话,history可以不要,这里采用了两种数据集的组织方式,但我们的预想最好是有多轮的上下文联系,所以也制作了alpaca格式的数据集。自定义数据集的格式比较简单,只有instruction、input和output,对于instruction和input对于微调大模型的具体作用,我们查阅了很多资料也没有弄清楚只好多种格式组合尝试。
一种是只有instruction和output,把问题作为instruction。
另一种是把问题作为input,把“你是面试官,用户是面试者,请对用户输入的面试现场的回答进行评价,固定输出格式为:评分: 评语: 下一个问题:”作为instruction。
还有一种是把问题作为instruction,把“你是面试官,用户是面试者,请对用户输入的面试现场的回答进行评价,固定输出格式为:评分: 评语: 下一个问题:”作为input。但经过多次训练测试发现这种数据集的效果很不好,最后放弃。
在根据组员用计算机专业领域的内容生成完多个自定义的问答json文件之后,分别生成其训练用的self-cognition、identity的文件以及test测试文件,根据以下代码计算其sha1值:
import hashlib
def calculate_sha1(file_path):
sha1 = hashlib.sha1()
try:
with open(file_path, 'rb') as file:
while True:
data = file.read(8192) # Read in chunks to handle large files
if not data:
break
sha1.update(data)
return sha1.hexdigest()
except FileNotFoundError:
return "File not found."
# 使用示例
file_path = './data/self_cognition_modified.json' # 替换为您的文件路径
sha1_hash = calculate_sha1(file_path)
print("SHA-1 Hash:", sha1_hash)
将这些json文件放入data文件夹下,同步修改dataset_info.json文件,输入新增的文件名称和对应的sha1值。
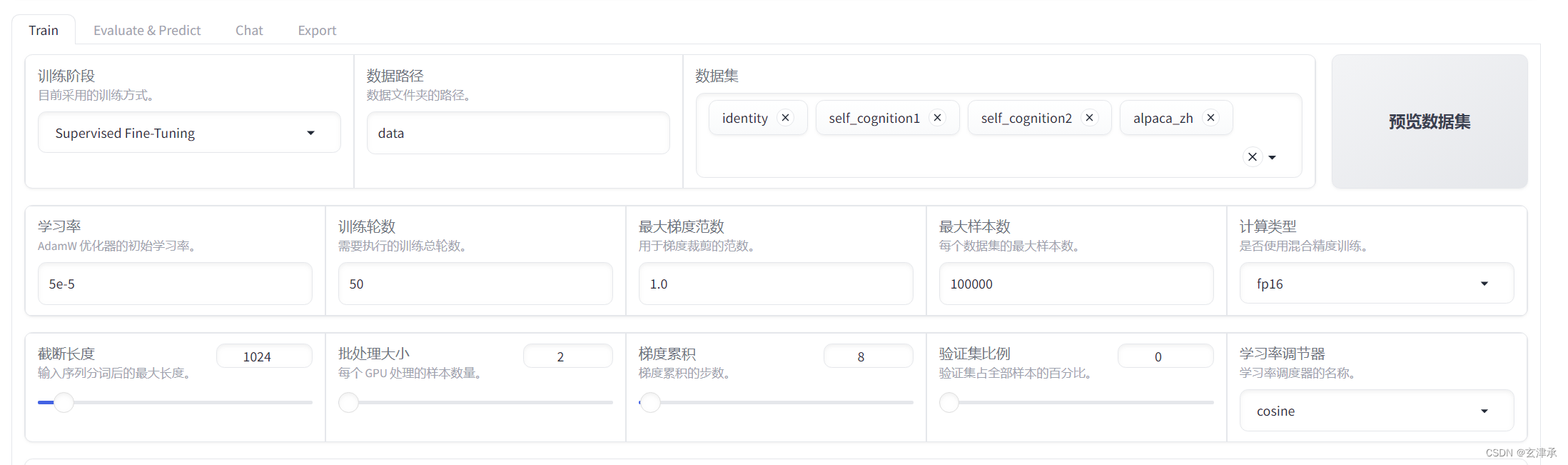
在后台执行CUDA_VISIBLE_DEVICES=0 python src/train_web.py命令,成功开启网页,设置如下,手动输入模型路径。
训练完成之后的界面,可以查看损失函数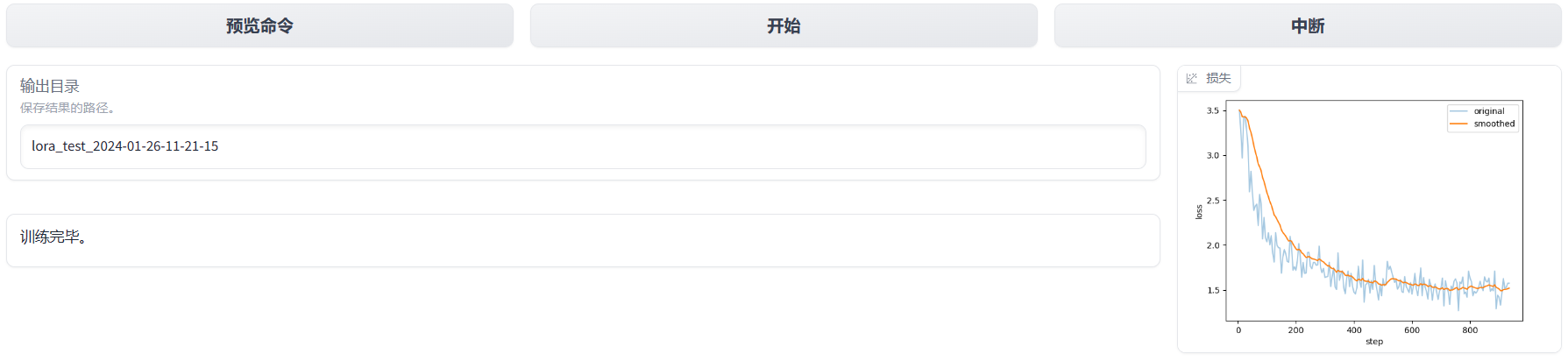
切换到Chat并点击加载模型后,可以进入聊天,直观的预览训练结果

如果大模型符合要求,就可以导出了
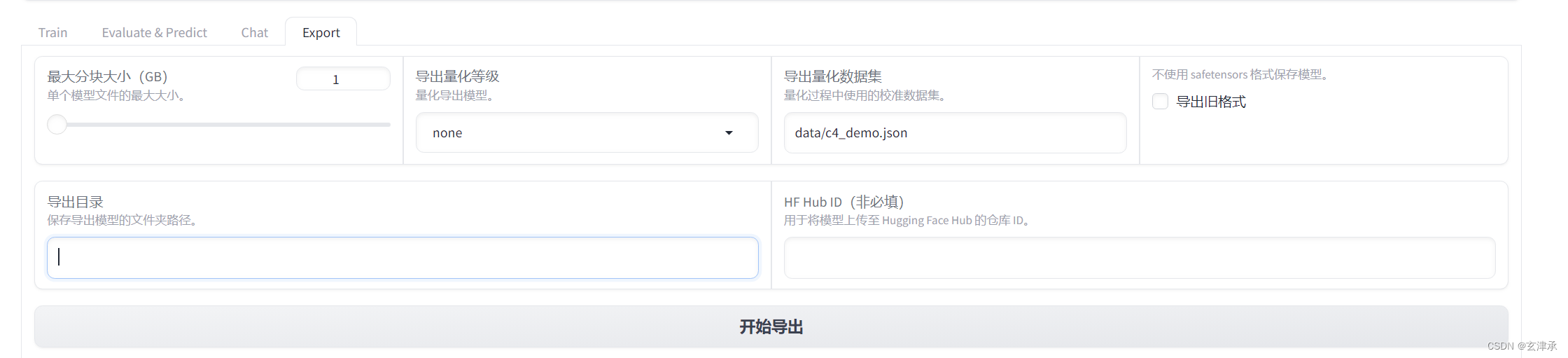
这就是用LLaMA-Factory进行大模型微调的一个基本流程
明确了这么一个基本流程,后续再开展细致的微调、调参工作就比较容易了。















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









