







参考代码:SOLOFusion
1. 概述
介绍:汽车的驾驶过程是时变的,则对该场景的处理方法最好也应该具有时间维度引入。这篇文章提出现有BEV感知算法中时序信息信息存在特征粒度较粗(特征图尺寸小)和使用到的时序信息较少(使用到的帧数少) 的问题,同时观察到距离车体不同距离下对时序信息的敏感程度是不一样的,距离越远越则需要多帧信息,但是也需要考虑实际机器的资源是有限的。对于上述问题文章提出了分别在高分辨率(在图像特征空间构建cost volume)和低分辨率(在BEV特征空间构建cost volume)分别进行时序信息融合,并且两者相互补全。需要指出在高分辨率下是参考MVSNet的方法去构建cost volume,而低分辨率也是需要对特征进行对齐操作的,这样也需要知道对应帧间位姿关系。
使用图像进行深度估计过程中,自然是希望对应像素的偏差足够大,这样才能够明显区分并表征出来。对应到时序数据中也是希望所使用的视频段跨度大一些,这样在图像中呈现的差异也变大了,如下图所示,这样才能保证localization potential(文中用其表征多视图下深度估计的难易程度)
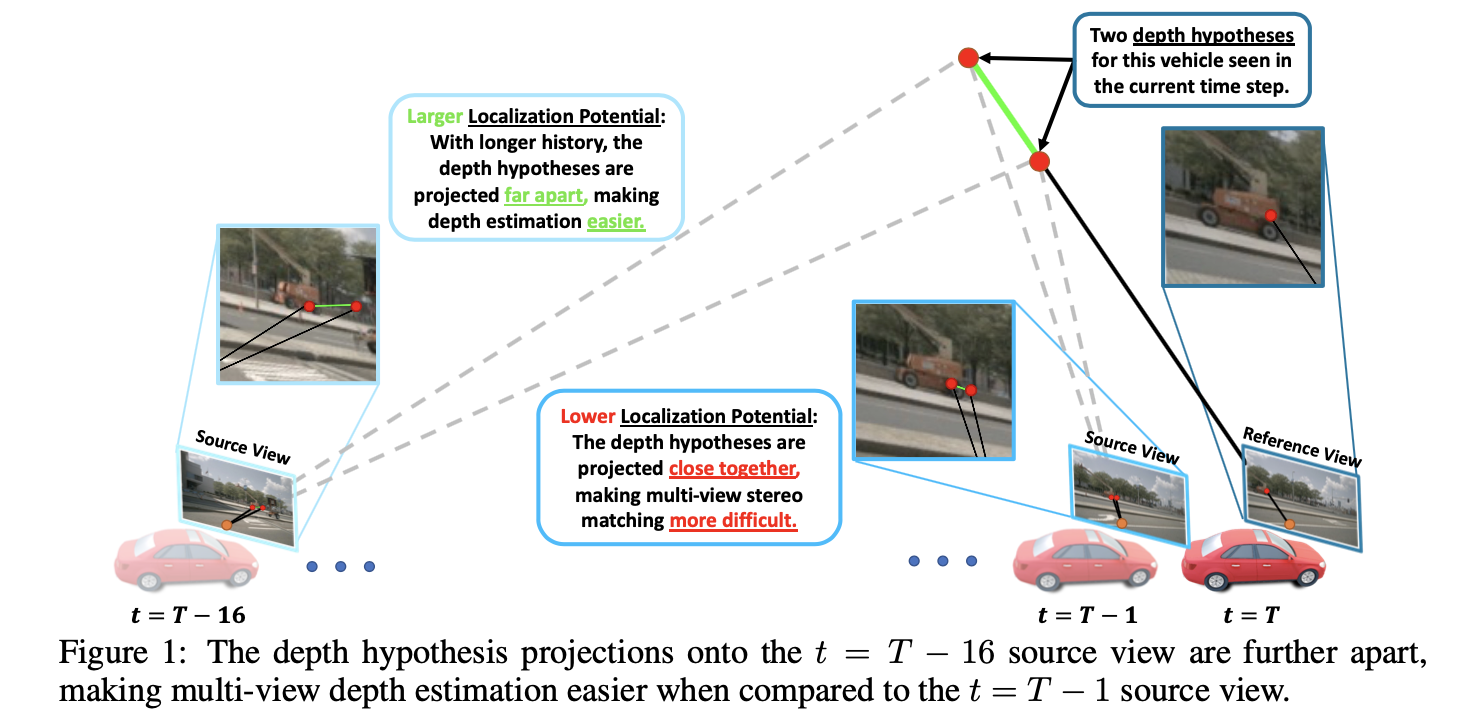
时序数据数量带来的影响:
将 t − 1 t-1 t−1帧中的点 a a a通过相机内外参数和到 t t t帧的位姿变换 [ R ∣ t ] [R|t] [R∣t]映射到对应的 b b b点,这个映射关系自然可以写出。不过文中更加关注的是在点 b b
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1431
1431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









