







1. 概述
导读:这篇文章采用分组卷积(pointwise group convolution)与通道混合(channel shuffle)操作构造了一个新的轻量级网络ShuffleNet。在ImageNet分类任务上top-1的错误率比MobileNet低了7.8%,计算量只有40 MFLOPs。在基于ARM的移动设备上ShuffleNet在保持与AlexNet相似精度的情况下快了13倍。
实质上,文中提出使用pointwise group卷积去减少原本1x1卷积的计算复杂度,但是这样会打断chanel之间的信息流动,为此使用channle shuffle的机制来维持信息的流动性,对于其它的部分是使用深度可分离卷积实现计算量的降低,从而构建了这篇文章提出的结构ShuffleNet。
2. 方法设计
2.1 Channel Shuffle for Group Convolutions
在网络结构Xception与ResNeXt网络中引入了深度可分离卷积与分组卷积,从而减少了网络的计算量。但是这些网络并没有考虑block中1x1的深度可分离卷积的计算量也是很大的,文章作者在设计ShuffleNet的时候参考了这两种网络的设计思路。

对于分组卷积其结构如图1(a)所示,输入的卷积被分为三个组,之后再在各个组上叠加卷积,存在的问题就是组间的信息是被阻隔的。由此提出了图1(b)中的网络结构,将每个子组中的信息也进行划分,之后相互混合得到组合的信息;在此基础上使用更有效的方式实现得到图1(c)中的结构,这样带来的好处是:(1)shuffle操作之前和之后的group可以不同;(2)shuffle操作可微,能端到端进行训练;
2.2 ShuffleNet Unit
在之前shuffle操作的基础上,文章进一步提出了ShuffleNet Unit模块。在图2(a)中是使用深度可分离卷积加速之后的残差块,其计算量还是比较大的(1x1卷积部分)。
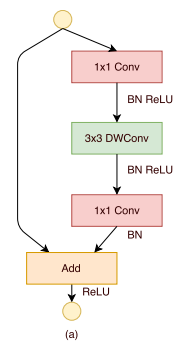
图2(b)是文章提出的Shuffle Unit模块,主要的不同点是对1x1的卷积使用分组卷积进行替换,第一个分组卷积之后经过channel shuffle实现特征混合,再送入深度可分离卷积(注意,这里没有使用ReLU)。图2(c)是其stride为2时的网络结构

计算量分析:
首先对于原始的ResNet网络结构,对于输入为
c
∗
h
∗
w
c*h*w
c∗h∗w,1x1卷积中channel映射之后有c变为m,两个1x1维度变换卷积带来的计算量是:
c
o
s
t
1
=
c
∗
h
∗
w
∗
m
∗
1
∗
1
+
m
∗
h
∗
w
∗
c
∗
1
∗
1
cost1=c*h*w*m*1*1+m*h*w*c*1*1
cost1=c∗h∗w∗m∗1∗1+m∗h∗w∗c∗1∗1
中间部分计算量:
c
o
s
t
2
=
m
∗
h
∗
w
∗
m
∗
3
∗
3
cost2=m*h*w*m*3*3
cost2=m∗h∗w∗m∗3∗3
合起来就是
c
o
s
t
=
c
o
s
t
1
+
c
o
s
t
2
=
h
w
(
2
c
m
+
9
m
2
)
cost=cost1+cost2=hw(2cm+9m^2)
cost=cost1+cost2=hw(2cm+9m2)。
对于ResNeXt的版本,由于引入了分组的概念,中间部分的计算量有所减少,总的计算量变为:
c
o
s
t
=
h
w
(
2
c
m
+
9
m
2
g
)
cost=hw(2cm+\frac{9m^2}{g})
cost=hw(2cm+g9m2)。文章的模块不仅仅使用了分组卷积还使用了深度可分离卷积,其计算量为:
c
o
s
t
=
h
w
(
2
c
m
g
+
9
m
)
cost=hw(\frac{2cm}{g}+9m)
cost=hw(g2cm+9m)。
PS: 值得注意的是文章理论推出的计算量并不代表该网络在实际低功耗设备上的性能表现,还需要考虑到内存访问频率等带来的影响。
2.3 网络结构
下表是文章在Shuffle Unit基础上提出的ShuffleNet网络结构:

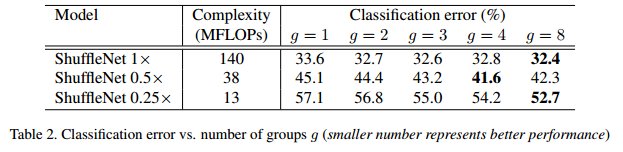
注意实验中的ShuffleNet sx代表的是相对于表1中对filter的数量使用s系数来控制,越小filter越少,见表2所示:
3. 实验结果
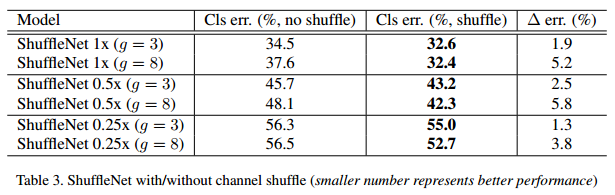
首先,验证Shuffle操作的有效性:
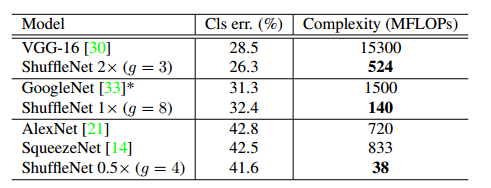
ShuffleNet与其它网络的性能对比:
与MobileNet的性能对比:
















 888
888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









