






工业异常检测评价指标(I-AUROC、PRO等)
浅谈异常检测算法
IM-IAD:工业制造中的工业图像异常检测基准
根据异常数据的类型可以分为数字、文本、图像、视频。根据领域不同可分为工业异常检测、医疗异常检测、日志异常检测等。
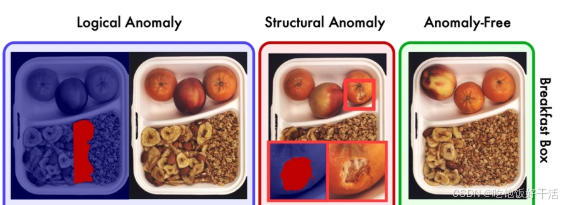
工业场景下的异常可分为结构性异常和逻辑性异常,结构性异常(Structural Anomaly)指产品上有瑕疵(如沾污、划痕等局部异常),逻辑性异常(Logical Anomaly)指各个组件没有正确组合,违背了逻辑约束的异常(如部件错位,丢失,多余,违背几何约束如长度等)。
半监督异常检测(semi-supervised AD):利用有限的样本标注信息,同时也不会像有监督算法那样需要大量的标注信息才能有效建模。
统一异常检测Unified Anomaly Detection:用多个类别的正常样本进行训练,目标是无需任何微调就能检测所有这些类别的异常

通用异常检测(GAD):训练一个单一的检测模型,使其能够在不同应用领域的多样化数据集上泛化检测异常,而无需针对目标数据进行进一步的训练。CVPR’24 | InCTRL

异常检测最大特点在于异常类别难以定义,甚至可以说异常的类别是无穷的。异常检测目前的局限性,对于背景复杂,结构多样的场景,异常检测面临较大的挑战;对于细粒度的逻辑异常检测(如螺丝长2mm),目前的异常检测无能为力,通常会采用传统的图像分析
异常得分图:如果特征向量可以映射到输入像素上,将它们的异常分数分配给相应的像素,就可以产生一个2D异常图,显示每个像素的异常分数。常见的方法包括多变量高斯分布、高斯混合模型、规范化流和k-最近邻(kNN)算法。
一、无监督异常检测算法的“门派”
- 1、基于重建的方法
认为异常图像区域不应该能够被正确重建,因为它们不存在于训练样本中。一些方法利用自动编码器和生成对抗网络等生成模型对正常数据进行编码和重构。积分结构相似指数(SSIM)损失函数在训练中被广泛使用。作为输入图像与其重建图像之间逐像素的差异,生成异常图。然而,如果异常与正常训练数据具有共同的组成模式(例如局部边缘),或者解码器“太强”而无法很好地解码某些异常编码,则可能很好地重构图像中的异常。
(a) 传统重建类方法:包括自编码器(AEs)、变分自编码器(VAEs)和生成对抗网络(GANs),这些方法可以学习正常样本的分布并在测试阶段重建异常区域。这些模型的重建能力有限,无法很好地重建复杂的纹理和物体,尤其是大规模缺陷或消失的情况。
(b) 扩散模型:(如DDPM和LDM)展示了其强大的图像生成能力。存在的局限性:当前的扩散模型无法有效解决,多类别异常检测问题。
RealNet(CVPR 2024)显存要求高 - 2、基于特征嵌入的方法
将常规特征嵌入到压缩空间中。在嵌入空间中,异常特征与正常特征相距甚远。典型的方法利用在ImageNet上预训练的网络进行特征提取。PaDiM使用预训练模型,通过多元高斯分布嵌入提取的异常斑块特征。PatchCore使用最大限度地代表标称补丁特征的内存库,测试中采用马氏距离或最大特征距离对输入特征进行评分。这些方法使用ImageNet预训练网络提取广义正态特征。==然后采用多元高斯分布、归一化流、记忆库等统计算法嵌入正态特征分布。==通过将输入特征与学习分布或记忆特征进行比较来检测异常。
然而,工业图像通常具有与ImageNet不同的分布,直接使用这些有偏差的特征可能会导致不匹配问题。此外,统计算法往往存在计算复杂度高、内存消耗大的问题。CS-Flow、CFLOW和DifferNet提出通过归一化流(normalizing flow, NF)将正态特征分布转化为高斯分布。由于归一化流只能处理全尺寸的特征映射,即不允许下采样,并且耦合层消耗的内存是普通卷积层的几倍,因此这些方法都是消耗内存的。蒸馏方法训练一个学生网络,以匹配固定的预训练教师网络的输出,只有正常样本。给定一个异常查询,应该检测到学生和教师输出之间的差异,由于输入图像要同时经过教师和学生,因此计算复杂度增加了一倍。
基于流模型 Flow-based model 的图像缺陷检测算法DifferNet(2020)、CFlow(2021)、CS-Flow(2021)、FastFlow(2021)、MSFlow(2023)、PyramidFlow(2023) - 3、基于自监督学习(或称基于合成)
通常是在无异常图像上合成异常。CutPaste提出了一种生成用于异常检测的综合异常的简单策略,即剪切图像补丁并在大图像的随机位置粘贴。训练CNN从正态分布和增强数据分布中区分图像。然而,合成异常的外观与实际异常并不吻合。在实践中,由于缺陷是多种多样且不可预测的,因此生成包含所有异常值的异常集是不可能的。
(a) 图像级异常合成策略:
这种策略在图像级别上显式地模拟异常,通过复制和粘贴正常区域到随机位置(CutPaste),或者使用Poisson图像编辑无缝融合不同大小的图像块(NSA),来合成异常。这种方法能够提供详细的异常纹理,但由于是在图像级别上操作,因此可能缺乏多样性,因为它受限于原始图像的内容和结构。
(b) 特征级异常合成策略:
这种策略在特征级别上隐式地模拟异常,通过向正常特征添加高斯噪声(SimpleNet和UniAD)来合成异常。这种方法比图像级合成更高效,因为它在特征空间中操作,特征图的尺寸通常比原始图像小。然而,它可能缺乏方向性,因为它不容易控制合成异常的方向和位置,尤其是在需要合成近分布异常时。 - 4、基于视觉语言模型
CLIP的主要思想是通过对比学习来对齐图像和文本,即将图像和匹配的文本描述在联合特征空间拉近,同时分离不匹配的图文对。
常用的ViT模型
- ViT-B/16, ViT-B/32
ViT-B/16和ViT-B/32是Vision Transformer的基本版本,"B"代表Base模型,数字16和32代表图像块的大小(如16x16或32x32)。
ViT-B/16通常表现优于ViT-B/32,因为较小的块能够捕捉到更多的细节信息。
应用: 这些模型通常用于图像分类任务,适用于中等规模的数据集。 - ViT-L/16, ViT-L/32
ViT-L/16和ViT-L/32是更大的版本,"L"代表Large模型。
ViT-L/16拥有更多的参数,因而能够捕捉更复杂的特征,但也需要更多的计算资源和数据。
应用: 这些模型适用于大型数据集,如ImageNet-21k或JFT-300M,在高精度要求的任务中表现更好。 - ViT-H/14
ViT-H/14是Vision Transformer的超大版本,"H"代表Huge模型,使用14x14的块大小。
该模型拥有非常多的参数(大约有3亿参数),因此需要非常大的数据集和计算资源。
应用: ViT-H/14 在需要极高精度的任务中使用,特别是超大规模的视觉任务,如高级分类和检测。
二、 少或零样本异常检测
少或零样本异常检测最新研究跟踪
CAReg:超越FSAD实现少样本异常检测!
小样本异常检测新突破!全新FSAD方法全类别通用
基于视觉语言模型的方法
- ECCV 2024, AdaCLIP
- ECCV 2024, VCP-CLIP
- CVPR 2023, WinCLIP
- ICLR 2024, AnomalyCLIP
- CVPR 2024, InCtrl
- CVPR 2024, PromptAD
基于测试数据先验的方法
- NeurIPS 2023, ACR
- ICLR 2024, MuSc
三、异常检测顶会论文汇总
【ECCV2024】异常检测
【CVPR 2024】异常检测
【ICLR 2024】异常检测
【NeurIPS 2024】异常检测
【ICLR 2025】异常检测
【AAAI 2025】异常检测
四、评价指标
Image AUROC 衡量的是整个图像级别的异常检测性能,即模型正确识别图像是否包含异常的能力。
Pixel AUROC 衡量的是像素级别的异常定位性能,即模型能够准确指出图像中哪些像素属于异常的能力。
PRO(Per Region Overlap) 是一种衡量异常区域重叠程度的指标,用来评估模型在检测异常区域时的准确性。
五、异常检测之EfficientAD(2023)
EfficientAD: Accurate Visual Anomaly Detection at Millisecond-Level Latencies
异常检测之EfficientAD
EfficientAD 设计了师生模型(S-T Model)和自动编码器(AE)来检测不同类型的异常情况。AE检测逻辑异常,而S-T模型检测粗度和细粒度的结构异常。并设计低延迟结构PND、类似在线难样本挖掘(Online Hard Example Mining)的Hard feature loss和定制化的Anomaly Map Normalization,EfficientAD在mvtec数据集上表现出当前最优的性能。

这个浅层网络乍一看没什么,因为早期的ST方法也用的浅层网络提取特征,而且一般来说,深层网络的表达能力更强,那这里为什么要用这么浅的网络呢?主要有两个原因:
- 为了推理速度
浅层网络当然比深层网络推理速度快(当然是结构一致的情况下),但是浅层网络对比深层网络其特征表达能力较弱,为了弥补这一差距,将PDN与一个深层网络(WideResNet-101)进行蒸馏。 - 为了局部特征提取
对于工业异常检测的场景来说,很多结构性异常(比如沾污,划痕等)是可以通过局部特征进行识别定位的。而网络越深,其可视野越大,提取的特征越偏向于“全局”,所以浅层网络可以通过更容易将可视野约束在较小范围,且不同patch的异常不会影响到当前patch的特征,从而有利于异常的定位。
异常检测之GLASS(2024)
GLASS: 基于全局和局部异常共合成策略的异常检测方法
本文提出的GLASS方法在图像和特征级别上控制合成异常的分布,通过使用梯度上升来实现。
在特征级别上,GLASS使用梯度上升引导的高斯噪声来合成全局异常,这种方法可以在正常样本分布附近有方向地合成异常,从而实现更紧密的分类边界,提高弱缺陷检测的性能。
在图像级别上,GLASS通过纹理叠加来合成局部异常,提供更多样化的异常合成范围。
GLASS方法通过梯度上升控制合成异常的方向,使得合成的异常更有可能位于分类边界附近,从而减少正常样本和异常样本之间的重叠,降低误分类的风险。

异常检测之RegAD(2022)
少样本异常检测,基于配准技术,使用具有三个空间变换网络块的孪生神经网络进行配准,训练单一可推广模型不需要对新类别进行重新训练
异常检测之CAReg(2024)
CAReg:超越FSAD
在RegAD基础上提出了一种新颖的少样本异常检测方法,称为CAReg,通过学习通用的跨类别配准技术,仅使用每个类别的正常图像进行训练,从而实现了对新类别的无需微调的模型应用,

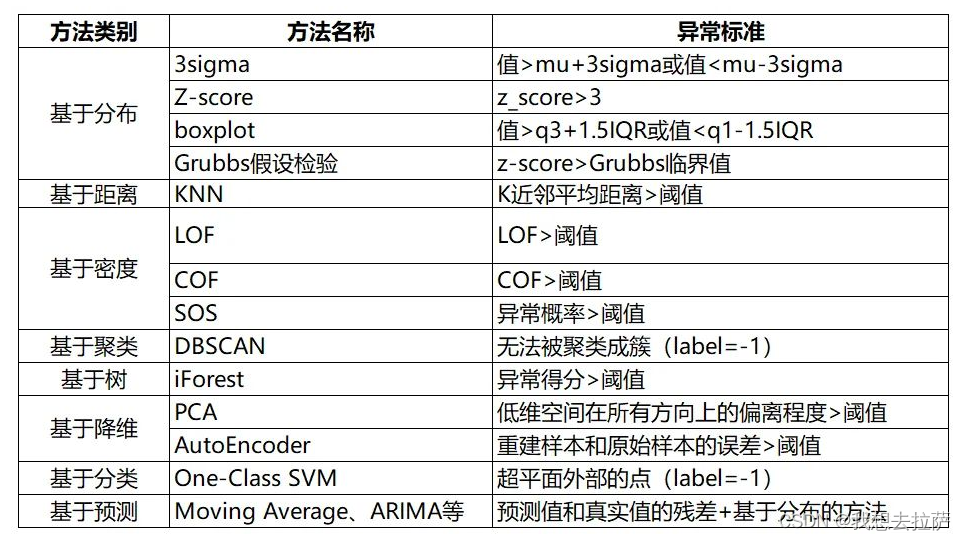
六、传统异常检测方法

















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









